زبان برنامهنویسی راست
نوشته استیو کلابنیک، کارول نیکولز، و کریس کریچو، با مشارکت اعضای جامعه راست
این نسخه از متن فرض را بر این میگذارد که شما از Rust نسخه 1.85.0 (منتشرشده در تاریخ ۲۰۲۵/۰۲/۱۷) یا جدیدتر استفاده میکنید و در فایل Cargo.toml تمامی پروژهها مقدار edition = “2024” را برای پیکربندی بهکار بردهاید تا از نگارش ۲۰۲۴ Rust و شیوههای مرسوم آن بهرهمند شوید. برای نصب یا بهروزرسانی Rust به بخش «نصب» در فصل ۱ مراجعه کنید.
فرمت HTML بهصورت آنلاین در دسترس است در
https://doc.rust-lang.org/stable/book/
و بهصورت آفلاین با نصبهای راست که با rustup انجام شدهاند؛ دستور rustup doc --book را اجرا کنید تا باز شود.
چندین [ترجمه] جامعه نیز در دسترس است.
این متن در فرمت کاغذی و الکترونیکی از انتشارات No Starch Press نیز موجود است.
🚨 میخواهید تجربه یادگیری تعاملیتری داشته باشید؟ نسخه دیگری از کتاب راست را امتحان کنید که شامل: آزمونها، برجستهسازیها، تجسمها، و موارد دیگر است: https://rust-book.cs.brown.edu
پیشگفتار
همیشه اینقدر واضح نبود، اما زبان برنامهنویسی راست اساساً درباره توانمندسازی است: فرقی نمیکند چه نوع کدی اکنون مینویسید، راست به شما این قدرت را میدهد که فراتر بروید، با اعتمادبهنفس در طیف وسیعتری از حوزهها برنامهنویسی کنید.
بهعنوان مثال، کارهای “در سطح سیستم” که با جزئیات سطح پایین مدیریت حافظه، نمایش دادهها و همروندی سر و کار دارند. به طور سنتی، این حوزه از برنامهنویسی پیچیده و فقط برای عده معدودی قابل دسترسی است که سالهای لازم را برای اجتناب از مشکلات معروف آن صرف کردهاند. حتی کسانی که در این زمینه فعالیت میکنند نیز با احتیاط عمل میکنند تا کد آنها در معرض بهرهبرداری، خرابی یا خرابی دادهها قرار نگیرد.
راست این موانع را از بین میبرد و با حذف مشکلات قدیمی و ارائه مجموعهای دوستانه و صیقلخورده از ابزارها به شما کمک میکند. برنامهنویسانی که نیاز دارند به کنترلهای سطح پایینتر “فرو روند”، میتوانند این کار را با راست انجام دهند، بدون پذیرش خطر معمول خرابیها یا مشکلات امنیتی و بدون نیاز به یادگیری جزئیات ابزارهای پیچیده. بهتر از آن، این زبان طوری طراحی شده است که شما را بهصورت طبیعی به سمت کدی قابلاطمینان و کارآمد از نظر سرعت و استفاده از حافظه هدایت میکند.
برنامهنویسانی که قبلاً با کد سطح پایین کار میکنند، میتوانند با راست جاهطلبیهای خود را افزایش دهند. بهعنوان مثال، معرفی همروندی در راست عملی نسبتاً کمخطر است: کامپایلر اشتباهات کلاسیک را برای شما میگیرد. و شما میتوانید با اطمینان به این که بهطور تصادفی خرابیها یا آسیبپذیریها را معرفی نمیکنید، بهینهسازیهای جسورانهتری را در کد خود پیاده کنید.
اما راست محدود به برنامهنویسی سیستمهای سطح پایین نیست. این زبان به قدری بیانگر و راحت است که نوشتن برنامههای خط فرمان (CLI)، سرورهای وب و بسیاری از انواع دیگر کدها را دلپذیر میکند — نمونههای سادهای از هر دو را در بخشهای بعدی کتاب خواهید یافت. کار با راست به شما این امکان را میدهد که مهارتهایی بسازید که از یک حوزه به حوزه دیگر قابلانتقال باشند؛ میتوانید راست را با نوشتن یک برنامه وب یاد بگیرید و سپس همان مهارتها را برای هدف قرار دادن رزبری پای خود به کار ببرید.
این کتاب پتانسیل راست برای توانمندسازی کاربرانش را به طور کامل در آغوش میگیرد. این متنی دوستانه و قابلدسترس است که قصد دارد نه تنها دانش شما در مورد راست، بلکه دامنه و اعتمادبهنفس شما را بهعنوان یک برنامهنویس به طور کلی ارتقا دهد. پس وارد شوید، آماده یادگیری باشید — و به جامعه راست خوش آمدید!
— نیکولاس ماتساکیس و آرون تورون
مقدمه
توجه: این نسخه از کتاب همان The Rust Programming Language است که به صورت چاپی و الکترونیکی از No Starch Press در دسترس است.
به زبان برنامهنویسی راست خوش آمدید، یک کتاب مقدماتی درباره راست. زبان برنامهنویسی راست به شما کمک میکند نرمافزاری سریعتر و قابلاعتمادتر بنویسید. در طراحی زبانهای برنامهنویسی، راحتی در سطح بالا و کنترل در سطح پایین اغلب در تضاد هستند؛ راست این تناقض را به چالش میکشد. با ایجاد تعادل بین تواناییهای فنی قدرتمند و تجربه عالی برنامهنویسی، راست به شما این امکان را میدهد که جزئیات سطح پایین (مانند استفاده از حافظه) را بدون دردسرهای سنتی مرتبط با چنین کنترلی مدیریت کنید.
راست برای چه کسانی است
راست برای افراد مختلف با دلایل متنوع ایدهآل است. بیایید به برخی از مهمترین گروهها نگاهی بیندازیم.
تیمهای برنامهنویسی
راست ابزاری اثبات شده برای همکاری میان تیمهای بزرگ برنامهنویسان با سطوح مختلف دانش برنامهنویسی سیستم است. کد سطح پایین مستعد اشکالات ظریف متعددی است که در بیشتر زبانهای دیگر تنها از طریق تست گسترده و بازبینی دقیق کد توسط برنامهنویسان با تجربه قابل شناسایی هستند. در راست، کامپایلر نقش نگهبان را ایفا میکند و از کامپایل کردن کدهایی با این اشکالات گریزان، از جمله اشکالات همروندی، جلوگیری میکند. با کار کردن در کنار کامپایلر، تیم میتواند زمان خود را بر روی منطق برنامه به جای رفع اشکالات صرف کند.
راست همچنین ابزارهای مدرن برنامهنویسی را به دنیای برنامهنویسی سیستمها میآورد:
- Cargo، مدیر وابستگی و ابزار ساخت، اضافه کردن، کامپایل کردن، و مدیریت وابستگیها را در سراسر اکوسیستم راست ساده و یکپارچه میکند.
- ابزار قالببندی Rustfmt، یک سبک کدنویسی ثابت را در بین برنامهنویسان تضمین میکند.
- rust-analyzer یکپارچگی محیط توسعه یکپارچه (IDE) را برای تکمیل کد و پیامهای خطای درونخطی فراهم میکند.
با استفاده از این ابزارها و دیگر ابزارهای اکوسیستم راست، برنامهنویسان میتوانند در هنگام نوشتن کد سطح سیستمها بهرهور باشند.
دانشجویان
راست برای دانشجویان و کسانی است که به یادگیری مفاهیم سیستمها علاقهمند هستند. بسیاری از افراد با استفاده از راست موضوعاتی مانند توسعه سیستمعامل را آموختهاند. جامعه راست بسیار پذیرنده است و با خوشحالی به سوالات دانشجویان پاسخ میدهد. از طریق تلاشهایی مانند این کتاب، تیمهای راست میخواهند مفاهیم سیستمها را برای افراد بیشتری، به ویژه کسانی که تازه وارد برنامهنویسی هستند، قابل دسترستر کنند.
شرکتها
صدها شرکت، بزرگ و کوچک، از راست در تولید برای وظایف متنوعی استفاده میکنند، از جمله ابزارهای خط فرمان، خدمات وب، ابزارهای DevOps، دستگاههای تعبیهشده، تحلیل و رمزگذاری صدا و تصویر، ارزهای دیجیتال، زیستاطلاعات، موتورهای جستجو، برنامههای اینترنت اشیاء، یادگیری ماشین و حتی بخشهای اصلی مرورگر وب فایرفاکس.
توسعهدهندگان متنباز
راست برای کسانی است که میخواهند زبان برنامهنویسی راست، جامعه، ابزارهای توسعهدهنده و کتابخانهها را بسازند. ما دوست داریم شما در توسعه زبان راست مشارکت کنید.
افرادی که سرعت و پایداری را ارزشمند میدانند
Rust برای کسانی است که بهدنبال سرعت و پایداری در یک زبان برنامهنویسی هستند. منظور از سرعت، هم سرعت اجرای کدهای Rust و هم سرعت توسعه برنامه با استفاده از Rust است. بررسیهای کامپایلر Rust پایداری را حتی هنگام افزودن ویژگیهای جدید یا بازسازی کد (refactoring) تضمین میکنند. این در تضاد با کدهای قدیمی و شکننده در زبانهایی است که چنین بررسیهایی ندارند و توسعهدهندگان اغلب از تغییر آنها واهمه دارند. Rust با تمرکز بر مفهوم انتزاعهای بدونهزینه (zero-cost abstractions)— یعنی ویژگیهای سطح بالا که پس از کامپایل به کدی در سطح پایین و سریع مانند کد دستی تبدیل میشوند—تلاش میکند تا کد امن، کدی سریع نیز باشد.
زبان راست امیدوار است از بسیاری از کاربران دیگر نیز پشتیبانی کند؛ افرادی که در اینجا ذکر شدند تنها برخی از بزرگترین ذینفعان هستند. در کل، بزرگترین جاهطلبی راست این است که با ارائه ایمنی و بهرهوری، سرعت و راحتی، مصالحههایی که برنامهنویسان دههها پذیرفتهاند را حذف کند. راست را امتحان کنید و ببینید آیا انتخابهای آن برای شما مناسب است یا خیر.
این کتاب برای چه کسانی است
این کتاب فرض میکند که شما قبلاً در یک زبان برنامهنویسی دیگر کدنویسی کردهاید اما هیچ فرضی در مورد اینکه کدام زبان است، ندارد. ما سعی کردهایم مطالب را به گونهای ارائه دهیم که برای افراد با زمینههای برنامهنویسی متنوع قابل دسترسی باشد. ما زمان زیادی را صرف صحبت درباره اینکه برنامهنویسی چیست یا چگونه باید به آن فکر کنید، نمیکنیم. اگر کاملاً تازهوارد برنامهنویسی هستید، بهتر است کتابی را بخوانید که به طور خاص مقدمهای بر برنامهنویسی ارائه میدهد.
نحوه استفاده از این کتاب
به طور کلی، این کتاب فرض میکند که شما آن را به ترتیب از ابتدا تا انتها میخوانید. فصلهای بعدی بر مفاهیم فصلهای قبلی بنا شدهاند و فصلهای اولیه ممکن است به جزئیات خاصی وارد نشوند اما در فصول بعدی به آن موضوعات بازمیگردند.
در این کتاب، دو نوع فصل وجود دارد: فصلهای مفهومی و فصلهای پروژهای. در فصلهای مفهومی، درباره یک جنبه از راست یاد خواهید گرفت. در فصلهای پروژهای، برنامههای کوچکی را با هم میسازیم و آنچه را که تاکنون آموختهاید به کار میگیریم. فصلهای ۲، ۱۲ و ۲۱ فصلهای پروژهای هستند؛ بقیه فصلها مفهومی هستند.
فصل ۱ نحوه نصب راست، نوشتن یک برنامه “سلام دنیا!” و استفاده از Cargo، مدیر بسته و ابزار ساخت راست را توضیح میدهد. فصل ۲ مقدمهای عملی برای نوشتن برنامهای در راست است و شما را به ساخت یک بازی حدس عدد میبرد. در اینجا مفاهیم را به طور کلی پوشش میدهیم و جزئیات بیشتری را در فصول بعدی ارائه خواهیم کرد. اگر میخواهید بلافاصله کار عملی انجام دهید، فصل ۲ مناسب شماست. فصل ۳ ویژگیهای راست را که مشابه ویژگیهای سایر زبانهای برنامهنویسی است پوشش میدهد و در فصل ۴ درباره سیستم مالکیت راست یاد خواهید گرفت. اگر شما یک یادگیرنده دقیق هستید که ترجیح میدهید قبل از ادامه، همه جزئیات را بیاموزید، ممکن است بخواهید فصل ۲ را رد کنید و مستقیماً به فصل ۳ بروید و پس از یادگیری جزئیات به فصل ۲ بازگردید تا روی پروژهای کار کنید.
فصل ۵ به ساختارها (structs) و متدها میپردازد و فصل ۶ شامل enumerations (enums)، عبارات match و سازه کنترلی if let است. از ساختارها و enumها برای ایجاد انواع سفارشی در راست استفاده خواهید کرد.
در فصل ۷، درباره سیستم ماژول راست و قوانین حریم خصوصی برای سازماندهی کد و رابط برنامهنویسی عمومی (API) آن یاد خواهید گرفت. فصل ۸ به بررسی برخی از ساختارهای داده مجموعه رایج که کتابخانه استاندارد ارائه میدهد، مانند vectors، strings و hash maps میپردازد. فصل ۹ فلسفه و تکنیکهای مدیریت خطا در راست را بررسی میکند.
فصل ۱۰ به مفاهیم جنریکها، traits و lifetimes میپردازد که به شما این قدرت را میدهد تا کدی بنویسید که به انواع مختلف اعمال شود. فصل ۱۱ کاملاً درباره تست است که حتی با تضمینهای ایمنی راست، برای اطمینان از درستی منطق برنامه شما ضروری است. در فصل ۱۲، پیادهسازی بخشی از ابزار خط فرمان grep که متن را در فایلها جستجو میکند، خواهیم ساخت. برای این کار، از بسیاری از مفاهیمی که در فصلهای قبلی مورد بحث قرار گرفتند استفاده خواهیم کرد.
فصل ۱۳ به بررسی closures و iterators میپردازد: ویژگیهایی از راست که از زبانهای برنامهنویسی تابعی آمدهاند. در فصل ۱۴، Cargo را به طور عمیقتری بررسی خواهیم کرد و درباره بهترین روشها برای اشتراکگذاری کتابخانههای خود با دیگران صحبت خواهیم کرد. فصل ۱۵ اشارهگر (Pointer)های هوشمند (smart pointers) ارائهشده توسط کتابخانه استاندارد و traitsی که قابلیتهای آنها را امکانپذیر میسازد بررسی میکند.
در فصل ۱۶، با مدلهای مختلف برنامهنویسی همروند (concurrent) آشنا خواهیم شد و دربارهی اینکه چگونه Rust به شما کمک میکند تا بدون ترس در چند thread برنامهنویسی کنید صحبت میکنیم. در فصل ۱۷، بر پایهی آن مفاهیم، نگارش async و await را در Rust بررسی میکنیم و همچنین به سراغ taskها، futureها، و streamها میرویم که مدل همروندی سبکوزن را فراهم میکنند.
فصل ۱۸ به مقایسهی شیوههای رایج در Rust با اصول برنامهنویسی شیگرا میپردازد که ممکن است پیشتر با آنها آشنا باشید. فصل ۱۹ مرجعی است برای الگوها (patterns) و pattern matching، که راهکارهایی قدرتمند برای بیان مفاهیم در سراسر برنامههای Rust هستند. فصل ۲۰ مجموعهای متنوع از موضوعات پیشرفته را در بر میگیرد، از جمله Rust ناایمن (unsafe)، ماکروها، و مباحث بیشتری دربارهی lifetimeها، traitها، نوعها، تابعها و closureها.
در فصل ۲۱، پروژهای را تکمیل میکنیم که در آن یک سرور وب چندرشتهای سطح پایین پیادهسازی خواهیم کرد!
در نهایت، برخی ضمیمهها شامل اطلاعات مفیدی دربارهی زبان Rust هستند که بهصورت مرجعگونه ارائه شدهاند. ضمیمهی الف به کلمات کلیدی Rust میپردازد، ضمیمهی ب عملگرها و نمادهای Rust را پوشش میدهد، ضمیمهی ج traitهای قابلمشتق موجود در کتابخانهی استاندارد را بررسی میکند، ضمیمهی د به برخی ابزارهای مفید توسعه میپردازد، و ضمیمهی ه نگارشهای مختلف Rust را توضیح میدهد. در ضمیمهی و میتوانید ترجمههای این کتاب را بیابید، و در ضمیمهی ی با روند توسعهی Rust و مفهوم Rust شبانه (nightly) آشنا خواهید شد.
هیچ روش نادرستی برای خواندن این کتاب وجود ندارد: اگر میخواهید به جلو بروید، این کار را انجام دهید! ممکن است مجبور شوید به فصلهای قبلی بازگردید اگر با سردرگمی روبهرو شدید. اما هرچه برای شما مناسب است انجام دهید.
بخش مهمی از فرآیند یادگیری راست، یادگیری نحوه خواندن پیامهای خطای کامپایلر است: این پیامها شما را به سمت کدی که کار میکند هدایت میکنند. به همین دلیل، مثالهای زیادی را ارائه میدهیم که کامپایل نمیشوند، همراه با پیام خطایی که کامپایلر در هر وضعیت نمایش میدهد. بدانید که اگر یک مثال تصادفی را وارد کنید و اجرا کنید، ممکن است کامپایل نشود! مطمئن شوید که متن اطراف را بخوانید تا ببینید آیا مثالی که میخواهید اجرا کنید قرار است خطا بدهد یا خیر. Ferris همچنین به شما کمک میکند کدی که قرار نیست کار کند را تشخیص دهید:
| Ferris | معنی |
|---|---|
 | این کد کامپایل نمیشود! |
 | این کد وحشت میکند! |
 | این کد رفتار مورد انتظار را تولید نمیکند. |
در بیشتر موارد، شما را به نسخه صحیح هر کدی که کامپایل نمیشود هدایت خواهیم کرد.
کد منبع
فایلهای منبعی که این کتاب از آنها تولید میشود را میتوانید در GitHub پیدا کنید.
شروع به کار
بیایید سفر خود به دنیای راست را آغاز کنیم! چیزهای زیادی برای یادگیری وجود دارد، اما هر سفری از جایی شروع میشود. در این فصل، درباره موارد زیر صحبت خواهیم کرد:
- نصب راست بر روی لینوکس، macOS، و ویندوز
- نوشتن برنامهای که
سلام دنیا!را چاپ میکند - استفاده از
cargo، مدیر بسته و سیستم ساخت راست
نصب
اولین قدم نصب راست است. ما راست را از طریق rustup دانلود میکنیم، ابزاری خط فرمان برای مدیریت نسخههای راست و ابزارهای مربوطه. برای دانلود به اتصال اینترنتی نیاز دارید.
توجه: اگر به هر دلیلی ترجیح میدهید از
rustupاستفاده نکنید، لطفاً صفحه روشهای نصب دیگر راست را برای گزینههای بیشتر مشاهده کنید.
مراحل زیر نسخه پایدار جدیدترین کامپایلر راست را نصب میکنند. تضمینهای پایداری راست اطمینان میدهند که تمام مثالهای کتاب که کامپایل میشوند، با نسخههای جدیدتر راست نیز کامپایل خواهند شد. خروجی ممکن است کمی متفاوت باشد، زیرا راست به طور مرتب پیغامهای خطا و هشدارها را بهبود میبخشد. به عبارت دیگر، هر نسخه پایدار جدیدی که با این مراحل نصب کنید، باید با محتوای این کتاب به درستی کار کند.
یادداشت دستورات خط فرمان
در این فصل و throughout the book، ما برخی از دستورات استفاده شده در ترمینال را نمایش خواهیم داد. خطوطی که باید در ترمینال وارد کنید، همگی با $ شروع میشوند. شما نیازی به وارد کردن نماد $ ندارید؛ این نماد نشاندهنده شروع هر دستور است. خطوطی که با $ شروع نمیشوند معمولاً خروجی دستور قبلی را نشان میدهند. علاوه بر این، مثالهای خاص PowerShell از > به جای $ استفاده میکنند.
نصب rustup در لینوکس یا macOS
اگر از لینوکس یا macOS استفاده میکنید، یک ترمینال باز کرده و دستور زیر را وارد کنید:
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
این دستور یک اسکریپت دانلود کرده و نصب ابزار rustup را آغاز میکند که نسخه پایدار جدید راست را نصب میکند. ممکن است از شما خواسته شود تا رمز عبور خود را وارد کنید. اگر نصب موفقیتآمیز بود، خط زیر ظاهر میشود:
Rust is installed now. Great!
همچنین به یک لینکر نیاز خواهید داشت که برنامهای است که راست از آن برای ترکیب خروجیهای کامپایل شده خود به یک فایل استفاده میکند. احتمالاً شما یک لینکر دارید. اگر با ارورهای لینکر روبهرو شدید، باید یک کامپایلر C نصب کنید که معمولاً لینکر را نیز شامل میشود. یک کامپایلر C همچنین مفید است زیرا برخی از پکیجهای رایج راست به کد C وابستهاند و به یک کامپایلر C نیاز دارند.
برای نصب کامپایلر C در macOS، دستور زیر را اجرا کنید:
$ xcode-select --install
کاربران لینوکس معمولاً باید GCC یا Clang را طبق مستندات توزیع خود نصب کنند. برای مثال، اگر از اوبونتو استفاده میکنید، میتوانید پکیج build-essential را نصب کنید.
نصب rustup در ویندوز
در ویندوز، به https://www.rust-lang.org/tools/install بروید و دستورالعملهای نصب راست را دنبال کنید. در یک مرحله از نصب، از شما خواسته میشود تا Visual Studio را نصب کنید. این ابزار یک لینکر و کتابخانههای بومی لازم برای کامپایل برنامهها را فراهم میکند. اگر به کمک بیشتری نیاز دارید، این صفحه را مشاهده کنید https://rust-lang.github.io/rustup/installation/windows-msvc.html
بقیه کتاب از دستورات استفاده شده در cmd.exe و PowerShell استفاده میکند. اگر تفاوتهای خاصی وجود داشته باشد، توضیح خواهیم داد که کدام را باید استفاده کنید.
عیبیابی
برای بررسی اینکه راست به درستی نصب شده است یا خیر، یک شل باز کرده و این دستور را وارد کنید:
$ rustc --version
باید شماره نسخه، هش کمیّت و تاریخ کمیّت برای جدیدترین نسخه پایدار منتشر شده را به صورت زیر ببینید:
rustc x.y.z (abcabcabc yyyy-mm-dd)
اگر این اطلاعات را مشاهده کردید، راست به درستی نصب شده است! اگر این اطلاعات را مشاهده نکردید، بررسی کنید که راست در متغیر سیستم %PATH% شما قرار دارد.
در CMD ویندوز، از دستور زیر استفاده کنید:
> echo %PATH%
در PowerShell، از دستور زیر استفاده کنید:
> echo $env:Path
در لینوکس و macOS، از دستور زیر استفاده کنید:
$ echo $PATH
اگر همه چیز درست باشد و راست همچنان کار نکند، منابع زیادی برای کمک وجود دارد. برای تماس با سایر راستنویسان (لقب خندهداری که خودمان به کار میبریم)، به صفحه اجتماع مراجعه کنید.
بروزرسانی و حذف نصب
بعد از نصب راست از طریق rustup، بروزرسانی به نسخه جدید بسیار آسان است. از شل خود دستور زیر را اجرا کنید:
$ rustup update
برای حذف نصب راست و rustup، اسکریپت حذف زیر را از شل خود اجرا کنید:
$ rustup self uninstall
مستندات محلی
نصب راست همچنین شامل یک نسخه محلی از مستندات است تا بتوانید آن را به صورت آفلاین مطالعه کنید. برای باز کردن مستندات محلی در مرورگر خود، دستور rustup doc را اجرا کنید.
هر زمان که از یک نوع یا تابع ارائهشده توسط کتابخانه استاندارد استفاده میکنید و مطمئن نیستید که چه کار میکند یا چگونه از آن استفاده کنید، از مستندات رابط برنامهنویسی (API) برای یافتن آن استفاده کنید!
ویرایشگرهای متن و محیطهای توسعه یکپارچه
این کتاب هیچ فرضی درباره ابزارهایی که برای نوشتن کد راست استفاده میکنید، ندارد. تقریباً هر ویرایشگر متنی کار را انجام میدهد! با این حال، بسیاری از ویرایشگرها و محیطهای توسعه یکپارچه (IDE) پشتیبانی داخلی برای راست دارند. همیشه میتوانید فهرست نسبتاً جدیدی از بسیاری از ویرایشگرها و IDEها را در صفحه ابزارها در وبسایت راست پیدا کنید.
کار با این کتاب بهصورت آفلاین
در چندین مثال، از پکیجهایی در Rust استفاده خواهیم کرد
که فراتر از کتابخانه استاندارد هستند. برای اجرای این
مثالها، یا باید به اینترنت متصل باشید یا اینکه
پیشاپیش این وابستگیها را دانلود کرده باشید.
برای دانلود پیشاپیش این وابستگیها، میتوانید
دستورات زیر را اجرا کنید. (در ادامه، cargo و
عملکرد هرکدام از این دستورات را بهطور کامل توضیح خواهیم داد.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add [email protected] [email protected]
این کار نسخههای دانلودشدهی این پکیجها را در کش
ذخیره میکند تا در آینده نیازی به دانلود مجدد نباشد.
پس از اجرای این دستورات، نیازی به نگهداشتن
پوشهی get-dependencies ندارید. اگر این دستورات
را اجرا کرده باشید، میتوانید در باقی قسمتهای
این کتاب از فلگ --offline همراه با تمام دستورات
cargo استفاده کنید تا بهجای اتصال به شبکه،
از نسخههای کششده بهره ببرید.
سلام، دنیا!
حالا که Rust را نصب کردهاید، وقت آن است که اولین برنامهی Rust خود را بنویسید.
وقتی زبان جدیدی را یاد میگیرید، معمولاً یک برنامه کوچک مینویسید که متن Hello, world! را به صفحه نمایش چاپ کند، پس ما هم همین کار را خواهیم کرد!
نکته: این کتاب فرض میکند که شما با خط فرمان آشنایی پایهای دارید. Rust هیچگونه الزامی در مورد ویرایش یا ابزارهای شما یا جایی که کد شما قرار دارد ندارد، بنابراین اگر ترجیح میدهید از یک محیط توسعه یکپارچه (IDE) به جای خط فرمان استفاده کنید، میتوانید از IDE مورد علاقه خود استفاده کنید. بسیاری از IDEها اکنون از Rust پشتیبانی میکنند؛ برای جزئیات، مستندات IDE خود را بررسی کنید. تیم Rust تمرکز خود را بر enabling پشتیبانی خوب از IDE از طریق
rust-analyzerگذاشته است. برای جزئیات بیشتر، به ضمیمه د مراجعه کنید.
ایجاد یک دایرکتوری پروژه
شما با ایجاد یک دایرکتوری برای ذخیره کدهای Rust خود شروع خواهید کرد. برای Rust مهم نیست که کد شما کجا قرار دارد، اما برای تمرینها و پروژههای این کتاب، پیشنهاد میکنیم یک دایرکتوری projects در دایرکتوری خانهتان بسازید و تمام پروژههایتان را در آن نگهدارید.
یک ترمینال باز کنید و دستورات زیر را وارد کنید تا یک دایرکتوری projects و یک دایرکتوری برای پروژهی “Hello, world!” در داخل دایرکتوری projects ایجاد کنید.
برای لینوکس، macOS، و PowerShell در ویندوز، این دستورات را وارد کنید:
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
برای CMD ویندوز، این دستورات را وارد کنید:
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
نوشتن و اجرای یک برنامه Rust
حالا یک فایل سورس جدید بسازید و آن را main.rs نامگذاری کنید. فایلهای Rust همیشه با پسوند .rs تمام میشوند. اگر از بیش از یک کلمه در نام فایل استفاده میکنید، سنت معمول این است که از خط تیره زیر برای جدا کردن آنها استفاده کنید. به عنوان مثال، از hello_world.rs به جای helloworld.rs استفاده کنید.
حالا فایل main.rs که تازه ایجاد کردهاید را باز کنید و کد موجود در فهرست 1-1 را وارد کنید.
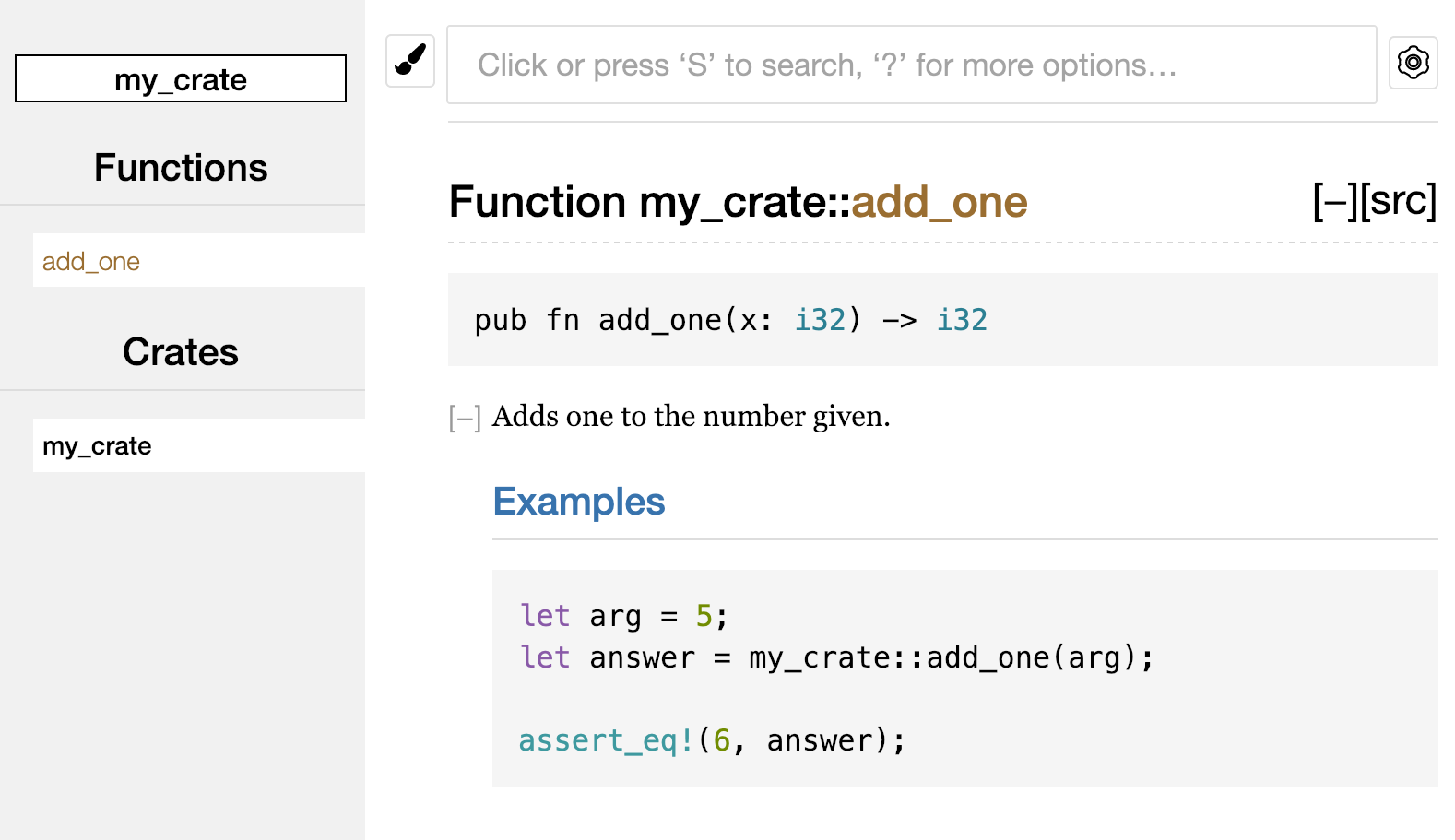
fn main() { println!("Hello, world!"); }
Hello, world! را چاپ میکندفایل را ذخیره کنید و به پنجره ترمینال خود در دایرکتوری ~/projects/hello_world برگردید. در لینوکس یا macOS، دستورات زیر را وارد کنید تا فایل را کامپایل کرده و اجرا کنید:
$ rustc main.rs
$ ./main
Hello, world!
در ویندوز، به جای ./main دستور .\main.exe را وارد کنید:
> rustc main.rs
> .\main
Hello, world!
صرفنظر از سیستمعامل شما، رشته Hello, world! باید در ترمینال چاپ شود. اگر این خروجی را مشاهده نکردید، به بخش “رفع مشکلات” در قسمت نصب مراجعه کنید تا روشهای دریافت کمک را بیابید.
اگر Hello, world! چاپ شد، تبریک میگوییم! شما به طور رسمی یک برنامه نویس Rust شدهاید—خوش آمدید!
آناتومی یک برنامه Rust
بیایید این برنامه “Hello, world!” را به طور دقیق بررسی کنیم. این اولین بخش معما است:
fn main() { }
این خطوط یک تابع به نام main تعریف میکنند. تابع main خاص است: همیشه اولین کدی است که در هر برنامه Rust اجرایی اجرا میشود. در اینجا، خط اول یک تابع به نام main اعلام میکند که هیچ پارامتر ندارد و هیچ چیزی را برنمیگرداند. اگر پارامترهایی وجود داشتند، آنها داخل پرانتزهای () قرار میگرفتند.
بدن تابع در {} قرار دارد. Rust از آکولادها برای احاطه کردن تمام بدنههای توابع استفاده میکند. این یک سبک خوب است که آکولاد باز را در همان خط اعلام تابع قرار دهید و یک فضای خالی بین آنها اضافه کنید.
نکته: اگر میخواهید در پروژههای Rust خود از یک سبک استاندارد پیروی کنید، میتوانید از ابزاری به نام
rustfmtبرای فرمت کردن کد خود در یک سبک خاص استفاده کنید (بیشتر در موردrustfmtدر ضمیمه د). تیم Rust این ابزار را همراه با توزیع استاندارد Rust شامل کرده است، همانطور کهrustcاست، بنابراین باید قبلاً روی کامپیوتر شما نصب شده باشد!
بدن تابع main شامل کد زیر است:
#![allow(unused)] fn main() { println!("Hello, world!"); }
این خط، تمام کار این برنامهی کوچک را انجام میدهد: متنی را روی صفحه چاپ میکند. در اینجا سه نکتهی مهم وجود دارد که باید به آنها توجه کنید.
نخست، println! یک ماکرو در Rust را فراخوانی میکند.
اگر بهجای ماکرو، یک تابع فراخوانی شده بود،
نگارش آن بهصورت println (بدون !) میبود.
ماکروهای Rust روشی برای نوشتن کدی هستند که
کد دیگری تولید میکنند و به گسترش نگارش Rust
کمک میکنند. در فصل بیستم Chapter 20
آنها را با جزئیات بیشتری بررسی خواهیم کرد.
در حال حاضر تنها کافیست بدانید که استفاده از
! به این معناست که در حال فراخوانی یک ماکرو هستید
و ماکروها همیشه از همان قواعدی که توابع پیروی میکنند،
تبعیت نمیکنند.
دوم، شما رشته "Hello, world!" را مشاهده میکنید. این رشته را به عنوان آرگومان به println! میدهیم و این رشته به صفحه نمایش چاپ میشود.
سوم، خط را با یک نقطهویرگول (;) تمام میکنیم که نشان میدهد این عبارت تمام شده و عبارت بعدی آماده شروع است. بیشتر خطوط کد Rust با نقطهویرگول تمام میشوند.
کامپایل کردن و اجرا کردن مراحل جداگانه هستند
شما به تازگی یک برنامه جدید ایجاد شده را اجرا کردهاید، بنابراین بیایید هر مرحله از فرآیند را بررسی کنیم.
قبل از اجرای یک برنامه Rust، باید آن را با استفاده از کامپایلر Rust کامپایل کنید. برای این کار باید دستور rustc را وارد کرده و نام فایل سورس خود را به آن بدهید، مانند این:
$ rustc main.rs
اگر پیشزمینهای از C یا C++ دارید، متوجه خواهید شد که این مشابه دستور gcc یا clang است. پس از کامپایل موفق، Rust یک فایل اجرایی باینری تولید میکند.
در لینوکس، macOS و PowerShell در ویندوز، میتوانید فایل اجرایی را با وارد کردن دستور ls در شل خود مشاهده کنید:
$ ls
main main.rs
در لینوکس و macOS، شما دو فایل خواهید دید. در PowerShell در ویندوز، همان سه فایلی را که با CMD میبینید مشاهده خواهید کرد. در CMD در ویندوز، باید دستور زیر را وارد کنید:
> dir /B %= گزینه /B میگوید که فقط نام فایلها نمایش داده شود =%
main.exe
main.pdb
main.rs
این لیست فایل سورس با پسوند .rs، فایل اجرایی (main.exe در ویندوز، اما main در سایر پلتفرمها)، و در صورت استفاده از ویندوز، یک فایل شامل اطلاعات دیباگ با پسوند .pdb را نشان میدهد. از اینجا، شما فایل main یا main.exe را اجرا میکنید، مانند این:
$ ./main # یا .\main.exe در ویندوز
اگر فایل main.rs شما برنامه “Hello, world!” باشد، این خط Hello, world! را در ترمینال شما چاپ میکند.
اگر با زبانهای داینامیک مانند Ruby، Python یا JavaScript آشنایی بیشتری دارید، ممکن است عادت نداشته باشید که کامپایل و اجرای یک برنامه را به عنوان مراحل جداگانه انجام دهید. Rust یک زبان کامپایل شده پیش از زمان است، به این معنی که شما میتوانید یک برنامه را کامپایل کرده و فایل اجرایی را به شخص دیگری بدهید تا آن را اجرا کند، حتی بدون اینکه Rust روی سیستم آن شخص نصب شده باشد. اگر به کسی فایل .rb، .py یا .js بدهید، آنها نیاز به نصب پیادهسازی Ruby، Python یا JavaScript (به ترتیب) دارند. اما در این زبانها، شما فقط به یک دستور نیاز دارید تا برنامه خود را کامپایل و اجرا کنید. همه چیز در طراحی زبانها یک تعادل است.
فقط با کامپایل کردن با rustc برای برنامههای ساده کافی است، اما با رشد پروژه شما، میخواهید تمام گزینهها را مدیریت کرده و اشتراکگذاری کد خود را آسان کنید. در ادامه، ما ابزار Cargo را معرفی خواهیم کرد که به شما کمک میکند برنامههای واقعی Rust بنویسید.
سلام، Cargo!
Cargo سیستم ساخت و مدیر بستههای Rust است. بیشتر Rustacean ها از این ابزار برای مدیریت پروژههای Rust خود استفاده میکنند زیرا Cargo بسیاری از وظایف را برای شما انجام میدهد، مانند ساختن کد شما، دانلود کتابخانههایی که کد شما به آنها وابسته است، و ساختن آن کتابخانهها. (ما به کتابخانههایی که کد شما به آنها نیاز دارد وابستگیها میگوییم.)
سادهترین برنامههای Rust، مانند برنامهای که تا کنون نوشتهایم، هیچ وابستگیای ندارند. اگر پروژه “Hello, world!” را با Cargo میساختیم، فقط از بخشی از Cargo استفاده میکرد که مسئول ساختن کد شما است. هنگامی که برنامههای پیچیدهتری در Rust بنویسید، وابستگیها را اضافه خواهید کرد و اگر پروژهای را با استفاده از Cargo شروع کنید، اضافه کردن وابستگیها بسیار راحتتر خواهد بود.
به دلیل اینکه اکثریت عظیم پروژههای Rust از Cargo استفاده میکنند، بقیه این کتاب فرض میکند که شما نیز از Cargo استفاده میکنید. Cargo با Rust نصب میشود اگر از نصبکنندههای رسمی که در بخش [“نصب”][installation] بحث شدهاند استفاده کرده باشید. اگر Rust را از طریق روشهای دیگری نصب کردهاید، بررسی کنید که آیا Cargo نصب شده است یا نه با وارد کردن دستور زیر در ترمینال خود:
$ cargo --version
اگر شماره نسخهای مشاهده کردید، آن را دارید! اگر خطای command not found را دیدید، به مستندات روش نصب خود مراجعه کنید تا نحوه نصب جداگانه Cargo را پیدا کنید.
ایجاد یک پروژه با Cargo
بیایید یک پروژه جدید با استفاده از Cargo بسازیم و ببینیم چگونه از پروژه اولیه “Hello, world!” ما متفاوت است. به دایرکتوری projects خود بروید (یا هر جایی که تصمیم گرفتهاید کد خود را ذخیره کنید). سپس، در هر سیستمعاملی، دستور زیر را وارد کنید:
$ cargo new hello_cargo
$ cd hello_cargo
دستور اول یک دایرکتوری جدید به نام hello_cargo ایجاد میکند و پروژهای به همین نام ایجاد میکند. ما پروژه خود را hello_cargo نامگذاری کردهایم و Cargo فایلهای خود را در دایرکتوری به همین نام ایجاد میکند.
به دایرکتوری hello_cargo بروید و فایلها را لیست کنید. خواهید دید که Cargo دو فایل و یک دایرکتوری برای ما ایجاد کرده است: یک فایل Cargo.toml و یک دایرکتوری src که داخل آن یک فایل main.rs است.
همچنین یک مخزن Git جدید به همراه یک فایل .gitignore ایجاد شده است. فایلهای Git در صورتی که دستور cargo new را در یک مخزن Git موجود اجرا کنید، ایجاد نمیشوند؛ میتوانید این رفتار را با استفاده از cargo new --vcs=git لغو کنید.
نکته: Git یک سیستم کنترل نسخه رایج است. شما میتوانید دستور
cargo newرا تغییر دهید تا از سیستم کنترل نسخهای متفاوت یا هیچ سیستم کنترل نسخهای استفاده کند با استفاده از پرچم--vcs. برای دیدن گزینههای موجود، دستورcargo new --helpرا اجرا کنید.
فایل Cargo.toml را در ویرایشگر متن دلخواه خود باز کنید. این فایل باید مشابه کدی باشد که در فهرست 1-2 آمده است.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
cargo new ایجاد شده استاین فایل در فرمت [TOML][toml] (زبان ساده و آشکار تام) است که فرمت پیکربندی Cargo است.
خط اول، [package]، یک عنوان بخش است که نشان میدهد بیانیههای بعدی در حال پیکربندی یک بسته هستند. همانطور که اطلاعات بیشتری به این فایل اضافه میکنیم، بخشهای دیگری را اضافه خواهیم کرد.
سه خط بعدی اطلاعات پیکربندیای را تنظیم میکنند که Cargo برای کامپایل برنامه شما به آنها نیاز دارد: نام، نسخه و نسخهای از Rust که باید استفاده شود. در مورد کلید edition در [ضمیمه ه][appendix-e] صحبت خواهیم کرد.
آخرین خط، [dependencies]، شروع یک بخش است که شما باید وابستگیهای پروژه خود را در آن ذکر کنید. در Rust، بستههای کد به نام کرِیتها شناخته میشوند. برای این پروژه نیازی به کرِیتهای دیگر نداریم، اما در پروژه اول فصل 2 به آنها نیاز خواهیم داشت، بنابراین در آن زمان از این بخش وابستگیها استفاده خواهیم کرد.
حالا فایل src/main.rs را باز کنید و نگاهی بیندازید:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
Cargo یک برنامه “Hello, world!” برای شما ایجاد کرده است، درست مانند برنامهای که در فهرست 1-1 نوشتیم! تا کنون، تفاوتهای بین پروژه ما و پروژهای که Cargo ایجاد کرده این است که Cargo کد را در دایرکتوری src قرار داده و ما یک فایل پیکربندی Cargo.toml در دایرکتوری بالای پروژه داریم.
Cargo انتظار دارد که فایلهای منبع شما داخل دایرکتوری src قرار داشته باشند. دایرکتوری بالای پروژه فقط برای فایلهای README، اطلاعات مجوز، فایلهای پیکربندی و هر چیز دیگری که مربوط به کد شما نباشد، استفاده میشود. استفاده از Cargo به شما کمک میکند پروژههایتان را سازماندهی کنید. برای هر چیز جایی وجود دارد و همه چیز در جای خود قرار دارد.
اگر پروژهای شروع کردهاید که از Cargo استفاده نمیکند، همانطور که در پروژه “Hello, world!” انجام دادیم، میتوانید آن را به پروژهای که از Cargo استفاده میکند تبدیل کنید. کد پروژه را به دایرکتوری src منتقل کرده و یک فایل Cargo.toml مناسب ایجاد کنید. یکی از راههای آسان برای بهدست آوردن آن فایل Cargo.toml این است که دستور cargo init را اجرا کنید که بهطور خودکار آن را برای شما ایجاد میکند.
ساخت و اجرای پروژه با Cargo
حالا بیایید ببینیم که چه تفاوتی در زمانی که برنامه “Hello, world!” را با Cargo میسازیم و اجرا میکنیم وجود دارد! از دایرکتوری hello_cargo خود، پروژه را با وارد کردن دستور زیر بسازید:
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
این دستور یک فایل اجرایی در target/debug/hello_cargo (یا target\debug\hello_cargo.exe در ویندوز) ایجاد میکند به جای این که آن را در دایرکتوری فعلی شما قرار دهد. زیرا ساخت پیشفرض یک ساخت دیباگ است، Cargo فایل باینری را در دایرکتوری به نام debug قرار میدهد. شما میتوانید فایل اجرایی را با این دستور اجرا کنید:
$ ./target/debug/hello_cargo # یا .\target\debug\hello_cargo.exe در ویندوز
Hello, world!
اگر همه چیز درست پیش رفته باشد، Hello, world! باید در ترمینال چاپ شود. اجرای cargo build برای اولین بار همچنین باعث میشود که Cargo یک فایل جدید در بالای دایرکتوری ایجاد کند: Cargo.lock. این فایل نسخههای دقیق وابستگیهای پروژه شما را پیگیری میکند. چون این پروژه وابستگی ندارد، این فایل کمی خالی است. شما هیچگاه نیازی به تغییر دستی این فایل نخواهید داشت؛ Cargo محتویات آن را برای شما مدیریت میکند.
ما همین حالا پروژه را با دستور cargo build ساختیم و با ./target/debug/hello_cargo اجرا کردیم، اما همچنین میتوانیم از cargo run برای کامپایل کردن کد و سپس اجرای باینری حاصل در یک دستور استفاده کنیم:
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
استفاده از cargo run راحتتر از این است که بخواهید دستور cargo build را اجرا کرده و سپس مسیر کامل به باینری را استفاده کنید، بنابراین بیشتر توسعهدهندگان از cargo run استفاده میکنند.
توجه کنید که این بار، خروجیای که نشان دهد Cargo در حال کامپایل کردن hello_cargo است، مشاهده نکردیم. Cargo متوجه شد که فایلها تغییر نکردهاند، بنابراین بازسازی نکرد و فقط باینری را اجرا کرد. اگر کد منبع خود را تغییر داده بودید، Cargo ابتدا پروژه را بازسازی میکرد و سپس آن را اجرا میکرد، و شما این خروجی را میدیدید:
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo همچنین یک دستور به نام cargo check را فراهم میکند. این دستور کد شما را به سرعت بررسی میکند تا مطمئن شود که کامپایل میشود اما هیچ اجرایی تولید نمیکند:
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
چرا شما به یک فایل اجرایی نیاز ندارید؟ اغلب، cargo check بسیار سریعتر از cargo build است زیرا مرحله تولید یک فایل اجرایی را رد میکند. اگر شما به طور مداوم در حال بررسی کد خود هستید، استفاده از cargo check سرعت فرایند اطلاع دادن به شما از این که پروژه هنوز کامپایل میشود را افزایش میدهد! به همین دلیل، بسیاری از Rustaceans به طور دورهای cargo check را در حین نوشتن کد خود اجرا میکنند تا مطمئن شوند که پروژهشان کامپایل میشود. سپس زمانی که آماده استفاده از باینری شدند، از دستور cargo build استفاده میکنند.
بیایید خلاصهای از آنچه که تا به حال در مورد Cargo آموختهایم مرور کنیم:
- ما میتوانیم یک پروژه با استفاده از
cargo newبسازیم. - ما میتوانیم یک پروژه را با استفاده از
cargo buildبسازیم. - ما میتوانیم یک پروژه را با یک مرحله از ساخت و اجرا با استفاده از
cargo runبسازیم و اجرا کنیم. - ما میتوانیم یک پروژه را بدون تولید باینری برای بررسی خطاها با استفاده از
cargo checkبسازیم. - به جای ذخیره نتیجه ساخت در همان دایرکتوری که کد ما قرار دارد، Cargo آن را در دایرکتوری target/debug ذخیره میکند.
یک مزیت اضافی استفاده از Cargo این است که دستورات آن در همه سیستمعاملها یکسان است. بنابراین، از این پس، دیگر دستورالعملهای خاصی برای لینوکس و macOS در مقابل ویندوز ارائه نخواهیم کرد.
ساخت برای انتشار
وقتی پروژه شما آماده انتشار است، میتوانید از دستور cargo build --release برای کامپایل کردن آن با بهینهسازیها استفاده کنید. این دستور یک فایل اجرایی در دایرکتوری target/release به جای target/debug ایجاد میکند. بهینهسازیها باعث میشوند که کد Rust شما سریعتر اجرا شود، اما فعال کردن آنها زمان کامپایل برنامه را طولانیتر میکند. به همین دلیل، دو پروفایل مختلف وجود دارد: یکی برای توسعه که شما میخواهید سریعاً و به دفعات پروژه را بازسازی کنید، و دیگری برای ساختن برنامه نهایی که به کاربر تحویل خواهید داد، که به دفعات بازسازی نمیشود و باید سریعترین اجرا را داشته باشد. اگر در حال اندازهگیری زمان اجرای کد خود هستید، حتماً از دستور cargo build --release استفاده کنید و با فایل اجرایی در target/release اندازهگیری کنید.
Cargo به عنوان یک کنوانسیون
در پروژههای ساده، Cargo نسبت به استفاده از rustc مزیت زیادی ندارد، اما با پیچیدهتر شدن برنامهها، ارزش خود را نشان میدهد. زمانی که برنامهها به چندین فایل نیاز پیدا میکنند یا وابستگی دارند، استفاده از Cargo برای هماهنگ کردن فرایند ساخت بسیار راحتتر میشود.
حتی اگر پروژه hello_cargo ساده باشد، اکنون از بسیاری از ابزارهای واقعی استفاده میکند که در طول مسیر Rust خود به آنها نیاز خواهید داشت. در واقع، برای کار بر روی هر پروژه موجود، میتوانید از دستورات زیر برای بررسی کد با استفاده از Git، تغییر به دایرکتوری آن پروژه و ساخت آن استفاده کنید:
$ git clone example.org/someproject
$ cd someproject
$ cargo build
برای اطلاعات بیشتر در مورد Cargo، میتوانید به مستندات آن مراجعه کنید.
خلاصه
شما در حال حاضر شروع بسیار خوبی برای سفر خود در Rust دارید! در این فصل، شما یاد گرفتهاید که چگونه:
- آخرین نسخه پایدار Rust را با استفاده از
rustupنصب کنید. - به نسخه جدیدتر Rust بروزرسانی کنید.
- مستندات محلی نصبشده را باز کنید.
- یک برنامه “Hello, world!” را با استفاده از
rustcمستقیماً بنویسید و اجرا کنید. - یک پروژه جدید را با استفاده از کنوانسیونهای Cargo بسازید و اجرا کنید.
این زمان بسیار خوبی است که برنامهای بزرگتر بسازید تا با خواندن و نوشتن کد Rust بیشتر آشنا شوید. بنابراین، در فصل 2، یک برنامه بازی حدس زدن خواهیم ساخت. اگر ترجیح میدهید ابتدا یاد بگیرید که مفاهیم برنامهنویسی رایج در Rust چگونه کار میکنند، فصل 3 را مطالعه کنید و سپس به فصل 2 بازگردید.
برنامهنویسی یک بازی حدس زدن
بیایید با کار روی یک پروژه عملی با هم به دنیای Rust وارد شویم! این فصل با نشان دادن نحوه استفاده از مفاهیم رایج Rust در یک برنامه واقعی، شما را با آنها آشنا میکند. درباره let، match، متدها، توابع مرتبط (associated functions)، جعبهها (crates)ی خارجی و موارد دیگر خواهید آموخت! در فصلهای بعدی، این ایدهها را به طور مفصل بررسی خواهیم کرد. در این فصل، فقط اصول اولیه را تمرین میکنید.
ما یک مسئله کلاسیک برنامهنویسی برای مبتدیان را پیادهسازی خواهیم کرد: یک بازی حدس زدن. این بازی به این صورت عمل میکند: برنامه یک عدد صحیح تصادفی بین 1 تا 100 تولید میکند. سپس از بازیکن میخواهد که یک حدس وارد کند. پس از وارد کردن حدس، برنامه مشخص میکند که آیا حدس خیلی پایین است یا خیلی بالا. اگر حدس درست باشد، برنامه یک پیام تبریک چاپ میکند و از بازی خارج میشود.
راهاندازی یک پروژه جدید
برای راهاندازی یک پروژه جدید، به دایرکتوری projects که در فصل 1 ایجاد کردید بروید و یک پروژه جدید با استفاده از Cargo ایجاد کنید، به این صورت:
$ cargo new guessing_game
$ cd guessing_game
دستور اول، cargo new، نام پروژه (guessing_game) را به عنوان آرگومان اول میگیرد. دستور دوم به دایرکتوری پروژه جدید منتقل میشود.
فایل Cargo.toml تولیدشده را مشاهده کنید:
Filename: Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
همانطور که در فصل 1 دیدید، cargo new یک برنامه “Hello, world!” برای شما تولید میکند. فایل src/main.rs را بررسی کنید:
Filename: src/main.rs
fn main() { println!("Hello, world!"); }
حالا این برنامه “Hello, world!” را کامپایل کرده و در همان مرحله با استفاده از دستور cargo run اجرا کنید:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/guessing_game`
Hello, world!
دستور run زمانی که نیاز دارید به سرعت روی یک پروژه تکرار کنید مفید است، همانطور که در این بازی انجام خواهیم داد، و به سرعت هر مرحله را قبل از ادامه به مرحله بعدی آزمایش میکنیم.
فایل src/main.rs را دوباره باز کنید. شما تمام کد را در این فایل خواهید نوشت.
پردازش یک حدس
اولین بخش از برنامه بازی حدس زدن از کاربر درخواست ورودی میکند، آن ورودی را پردازش میکند و بررسی میکند که ورودی در قالب مورد انتظار باشد. برای شروع، به بازیکن اجازه میدهیم یک حدس وارد کند. کد موجود در لیستینگ 2-1 را در فایل src/main.rs وارد کنید.
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}این کد اطلاعات زیادی دارد، پس بیایید خط به خط آن را بررسی کنیم. برای گرفتن ورودی کاربر و سپس چاپ نتیجه بهعنوان خروجی، نیاز داریم که کتابخانه ورودی/خروجی io را به دامنه بیاوریم. کتابخانه io از کتابخانه استاندارد که با نام std شناخته میشود، میآید:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}بهطور پیشفرض، Rust مجموعهای از آیتمها را که در کتابخانه استاندارد تعریف شدهاند به دامنه هر برنامه وارد میکند. این مجموعه prelude نامیده میشود و میتوانید همه چیز در آن را در مستندات کتابخانه استاندارد ببینید.
اگر نوعی که میخواهید استفاده کنید در prelude نباشد، باید آن نوع را بهطور صریح با یک دستور use به دامنه بیاورید. استفاده از کتابخانه std::io به شما ویژگیهای مفیدی مانند امکان پذیرش ورودی کاربر میدهد.
همانطور که در فصل 1 دیدید، تابع main نقطه ورود به برنامه است:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}نحو fn یک تابع جدید را اعلام میکند؛ پرانتزها () نشان میدهند که هیچ پارامتری وجود ندارد و کروشه باز { بدنه تابع را شروع میکند.
همچنین در فصل 1 آموختید که println! یک ماکرو است که یک رشته را به صفحه چاپ میکند:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}این کد یک پیغام اعلام میکند که بازی چیست و از کاربر درخواست ورودی میکند.
ذخیره مقادیر با متغیرها
سپس، یک متغیر ایجاد میکنیم تا ورودی کاربر را ذخیره کند، مانند این:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}حالا برنامه جالبتر میشود! در این خط کوچک چیزهای زیادی در حال اتفاق است. ما از دستور let برای ایجاد متغیر استفاده میکنیم. در اینجا یک مثال دیگر آورده شده است:
let apples = 5;این خط یک متغیر جدید به نام apples ایجاد میکند و آن را به مقدار 5 متصل میکند. در Rust، متغیرها بهطور پیشفرض غیرقابلتغییر هستند، به این معنا که پس از اختصاص مقدار به متغیر، مقدار تغییر نخواهد کرد. این مفهوم را بهطور مفصل در بخش “متغیرها و تغییرپذیری” در فصل 3 بررسی خواهیم کرد. برای متغیری که تغییرپذیر باشد، mut را قبل از نام متغیر اضافه میکنیم:
let apples = 5; // immutable
let mut bananas = 5; // mutableنکته: نحو
//یک نظر (comment) را آغاز میکند که تا انتهای خط ادامه دارد. Rust همه چیز در نظرات را نادیده میگیرد. نظرات را در فصل 3 با جزئیات بیشتری بررسی خواهیم کرد.
بازگشت به برنامه بازی حدس زدن: اکنون میدانید که let mut guess یک متغیر تغییرپذیر به نام guess معرفی میکند. علامت مساوی (=) به Rust میگوید که میخواهیم چیزی را به این متغیر متصل کنیم. در سمت راست علامت مساوی، مقداری قرار دارد که guess به آن متصل میشود، که نتیجه فراخوانی String::new است، یک تابع که یک نمونه جدید از نوع String بازمیگرداند. String یک نوع رشتهای ارائهشده توسط کتابخانه استاندارد است که بخشی از متن قابل رشد و با رمزگذاری UTF-8 است.
نحو :: در خط ::new نشان میدهد که new یک تابع مرتبط با نوع String است. یک تابع مرتبط تابعی است که روی یک نوع پیادهسازی شده است، در اینجا String. این تابع new یک رشته جدید و خالی ایجاد میکند. شما در بسیاری از انواع یک تابع new پیدا خواهید کرد، زیرا این نام معمولاً برای تابعی که یک مقدار جدید از یک نوع خاص ایجاد میکند استفاده میشود.
در مجموع، خط let mut guess = String::new(); یک متغیر تغییرپذیر ایجاد کرده است که در حال حاضر به یک نمونه جدید و خالی از String متصل شده است. خوب!
دریافت ورودی کاربر
به یاد آورید که با use std::io; در اولین خط برنامه، قابلیت ورودی/خروجی را از کتابخانه استاندارد اضافه کردیم. اکنون تابع stdin را از ماژول io فراخوانی میکنیم که به ما امکان مدیریت ورودی کاربر را میدهد:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}اگر ماژول io را با دستور use std::io;
در ابتدای برنامه وارد نکرده بودیم، همچنان
میتوانستیم از این تابع استفاده کنیم، به این شکل
که آن را بهصورت std::io::stdin فراخوانی کنیم.
تابع stdin نمونهای از std::io::Stdin
بازمیگرداند، که نوعی است برای نمایش یک
دسته (handle) به ورودی استاندارد ترمینال شما.
در خط بعدی، متد .read_line(&mut guess) را روی handle ورودی استاندارد فراخوانی میکنیم تا ورودی کاربر را دریافت کنیم. همچنین &mut guess را بهعنوان آرگومان به read_line ارسال میکنیم تا به آن بگوییم ورودی کاربر را در چه رشتهای ذخیره کند. وظیفه کامل read_line این است که هر چیزی را که کاربر در ورودی استاندارد تایپ میکند به رشتهای اضافه کند (بدون بازنویسی محتوای آن)، بنابراین این رشته را بهعنوان آرگومان ارسال میکنیم. آرگومان رشته باید تغییرپذیر باشد تا متد بتواند محتوای رشته را تغییر دهد.
علامت & نشان میدهد که این آرگومان یک ارجاع است، که به شما راهی میدهد تا به چندین بخش از کد اجازه دهید به یک قطعه داده دسترسی داشته باشند بدون اینکه نیاز به کپی کردن آن داده در حافظه چندین بار داشته باشید. ارجاعات یک ویژگی پیچیده هستند و یکی از مزایای اصلی Rust این است که استفاده از ارجاعات ایمن و آسان است. نیازی نیست جزئیات زیادی درباره آن بدانید تا این برنامه را کامل کنید. فعلاً، تنها چیزی که باید بدانید این است که، مانند متغیرها، ارجاعات بهطور پیشفرض غیرقابل تغییر هستند. بنابراین، باید &mut guess بنویسید بهجای &guess تا آن را تغییرپذیر کنید. (فصل 4 ارجاعات را بهطور کامل توضیح خواهد داد.)
مدیریت خطای احتمالی با Result
ما همچنان روی همین خط کد کار میکنیم. اکنون در حال بحث درباره خط سوم هستیم، اما توجه داشته باشید که این هنوز بخشی از یک خط منطقی از کد است. قسمت بعدی این متد است:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}ما میتوانستیم این کد را به این صورت بنویسیم:
io::stdin().read_line(&mut guess).expect("Failed to read line");با این حال، یک خط طولانی خواندن آن را دشوار میکند، بنابراین بهتر است آن را تقسیم کنیم. اغلب توصیه میشود یک خط جدید و فضای سفید معرفی کنید تا خطوط طولانی را هنگام فراخوانی متدی با نحو .method_name() تقسیم کنید. حالا بیایید ببینیم این خط چه میکند.
همانطور که قبلاً ذکر شد، read_line هر چیزی که کاربر وارد میکند را در رشتهای که به آن ارسال میکنیم قرار میدهد، اما همچنین یک مقدار Result بازمیگرداند. Result یک enumeration است که اغلب به عنوان enum نامیده میشود و نوعی است که میتواند در یکی از چندین حالت ممکن باشد. ما هر حالت ممکن را یک متغیر (variant) مینامیم.
فصل 6 به جزئیات بیشتری در مورد enumها خواهد پرداخت. هدف از انواع Result رمزگذاری اطلاعات مدیریت خطا است.
متغیرهای Result شامل Ok و Err هستند. متغیر Ok نشان میدهد که عملیات موفقیتآمیز بوده و مقداری که با موفقیت تولید شده است را در خود دارد. متغیر Err به معنای این است که عملیات شکست خورده و اطلاعاتی درباره چگونگی یا دلیل شکست عملیات در خود دارد.
مقادیر نوع Result، مانند مقادیر هر نوع دیگری، متدهایی تعریفشده بر روی خود دارند. یک نمونه از Result یک متد expect دارد که میتوانید آن را فراخوانی کنید. اگر این نمونه از Result یک مقدار Err باشد، expect باعث میشود برنامه متوقف شده و پیغام خطایی که بهعنوان آرگومان به expect پاس دادهاید را نمایش دهد. اگر متد read_line یک Err بازگرداند، احتمالاً به دلیل خطایی از سیستمعامل زیربنایی است. اگر این نمونه از Result یک مقدار Ok باشد، expect مقدار بازگشتی که Ok در خود دارد را میگیرد و فقط آن مقدار را بازمیگرداند تا بتوانید از آن استفاده کنید. در این مورد، آن مقدار تعداد بایتهای ورودی کاربر است.
اگر expect را فراخوانی نکنید، برنامه کامپایل میشود، اما هشداری دریافت خواهید کرد:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust هشدار میدهد که از مقدار Result بازگشتی از read_line استفاده نکردهاید، که نشان میدهد برنامه یک خطای ممکن را مدیریت نکرده است.
روش درست برای جلوگیری از هشدار این است که واقعاً کد مدیریت خطا بنویسید، اما در مورد ما فقط میخواهیم وقتی مشکلی پیش آمد این برنامه متوقف شود، بنابراین میتوانیم از expect استفاده کنیم. درباره بازیابی از خطاها در فصل 9 خواهید آموخت.
چاپ مقادیر با جاینگهدارهای println!
علاوه بر کروشه بسته، فقط یک خط دیگر برای بحث در کدی که تاکنون نوشتهایم باقی مانده است:
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}این خط رشتهای را که اکنون ورودی کاربر را در خود دارد چاپ میکند. مجموعه {} از کروشههای باز و بسته یک جاینگهدار است: به {} بهعنوان پنجههای کوچک خرچنگی فکر کنید که یک مقدار را در جای خود نگه میدارند. هنگام چاپ مقدار یک متغیر، نام متغیر میتواند داخل کروشهها قرار گیرد. هنگام چاپ نتیجه ارزیابی یک عبارت، کروشههای باز و بسته خالی را در رشته فرمت قرار دهید، سپس رشته فرمت را با لیستی از عبارات جداشده با کاما دنبال کنید تا در هر جاینگهدار خالی به همان ترتیب چاپ شوند. چاپ یک متغیر و نتیجه یک عبارت در یک فراخوانی println! به این صورت خواهد بود:
#![allow(unused)] fn main() { let x = 5; let y = 10; println!("x = {x} and y + 2 = {}", y + 2); }
این کد x = 5 and y + 2 = 12 را چاپ میکند.
آزمایش بخش اول
بیایید بخش اول بازی حدس زدن را آزمایش کنیم. با استفاده از دستور cargo run آن را اجرا کنید:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
در این مرحله، بخش اول بازی تمام شده است: ما ورودی را از صفحهکلید میگیریم و سپس آن را چاپ میکنیم.
تولید یک عدد مخفی
در مرحله بعد، باید یک عدد مخفی تولید کنیم که کاربر سعی خواهد کرد آن را حدس بزند. عدد مخفی باید هر بار متفاوت باشد تا بازی بارها قابل بازی و لذتبخش باشد. از یک عدد تصادفی بین 1 تا 100 استفاده میکنیم تا بازی خیلی سخت نباشد. Rust هنوز قابلیت تولید اعداد تصادفی را در کتابخانه استاندارد خود ندارد. با این حال، تیم Rust یک crate rand با این قابلیت ارائه میدهد.
استفاده از یک crate برای دسترسی به قابلیتهای بیشتر
به یاد داشته باشید که یک crate مجموعهای از فایلهای کد منبع Rust است. پروژهای که ما در حال ساخت آن هستیم یک crate دودویی است که یک فایل اجرایی است. crate rand یک crate کتابخانهای است که حاوی کدی است که قرار است در برنامههای دیگر استفاده شود و به تنهایی قابل اجرا نیست.
هماهنگی Cargo با جعبهها (crates)ی خارجی یکی از نقاط قوت آن است. قبل از اینکه بتوانیم کدی بنویسیم که از rand استفاده کند، باید فایل Cargo.toml را تغییر دهیم تا crate rand را به عنوان وابستگی اضافه کنیم. اکنون آن فایل را باز کنید و خط زیر را به انتهای آن، زیر بخش [dependencies] که Cargo برای شما ایجاد کرده است، اضافه کنید. مطمئن شوید که rand را دقیقاً همانطور که در اینجا آمده است با این شماره نسخه مشخص کنید، وگرنه مثالهای کد در این آموزش ممکن است کار نکنند:
Filename: Cargo.toml
[dependencies]
rand = "0.8.5"
در فایل Cargo.toml، هر چیزی که بعد از یک سرآیند بیاید بخشی از آن بخش است و تا زمانی که بخش دیگری شروع نشود ادامه مییابد. در [dependencies] به Cargo میگویید پروژه شما به کدام جعبهها (crates)ی خارجی وابسته است و کدام نسخه از آن جعبهها (crates) را نیاز دارید. در این مورد، ما crate rand را با مشخصکننده نسخه 0.8.5 مشخص میکنیم. Cargo نسخهبندی معنایی (گاهی اوقات SemVer نامیده میشود) را درک میکند، که یک استاندارد برای نوشتن شماره نسخهها است. مشخصکننده 0.8.5 در واقع مخفف ^0.8.5 است که به این معناست که هر نسخهای که حداقل 0.8.5 باشد ولی کمتر از 0.9.0 باشد.
Cargo این نسخهها را دارای API عمومی سازگار با نسخه 0.8.5 در نظر میگیرد و این مشخصه تضمین میکند که آخرین نسخه patch را دریافت خواهید کرد که همچنان با کد موجود در این فصل کامپایل میشود. هیچ تضمینی وجود ندارد که نسخه 0.9.0 یا بالاتر همان API را داشته باشد که مثالهای زیر استفاده میکنند.
اکنون، بدون تغییر هیچ کدی، بیایید پروژه را بسازیم، همانطور که در لیستینگ 2-2 نشان داده شده است.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
cargo build پس از افزودن crate rand به عنوان وابستگیممکن است نسخههای متفاوتی را ببینید (اما همه آنها با کد سازگار خواهند بود، به لطف SemVer!) و خطوط متفاوتی (بسته به سیستمعامل) داشته باشید، و این خطوط ممکن است به ترتیب متفاوتی ظاهر شوند.
وقتی یک وابستگی خارجی اضافه میکنیم، Cargo جدیدترین نسخههای هر چیزی که آن وابستگی نیاز دارد را از رجیستری دریافت میکند، که یک کپی از دادههای Crates.io است. Crates.io جایی است که افراد در اکوسیستم Rust پروژههای منبعباز Rust خود را برای استفاده دیگران ارسال میکنند.
پس از بهروزرسانی رجیستری، Cargo بخش [dependencies] را بررسی میکند و هر crateی را که در لیست نیست و هنوز دانلود نشده است دانلود میکند. در این مورد، اگرچه ما فقط rand را بهعنوان یک وابستگی لیست کردهایم، Cargo سایر جعبهها (crates)یی را که rand برای کارکردن به آنها وابسته است نیز دریافت کرده است. پس از دانلود جعبهها (crates)، Rust آنها را کامپایل میکند و سپس پروژه را با وابستگیهای موجود کامپایل میکند.
اگر بلافاصله دوباره دستور cargo build را اجرا کنید بدون اینکه هیچ تغییری ایجاد کرده باشید، خروجیای بهجز خط Finished دریافت نخواهید کرد. Cargo میداند که قبلاً وابستگیها را دانلود و کامپایل کرده است، و شما هیچ تغییری در فایل Cargo.toml خود ندادهاید. Cargo همچنین میداند که شما هیچ تغییری در کد خود ندادهاید، بنابراین آن را هم دوباره کامپایل نمیکند. وقتی کاری برای انجام دادن وجود ندارد، فقط خارج میشود.
اگر فایل src/main.rs را باز کنید، یک تغییر جزئی در آن ایجاد کنید، و سپس آن را ذخیره کرده و دوباره بسازید، فقط دو خط خروجی خواهید دید:
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
این خطوط نشان میدهند که Cargo فقط با تغییر کوچک شما در فایل src/main.rs بیلد را بهروزرسانی کرده است. وابستگیهای شما تغییری نکردهاند، بنابراین Cargo میداند که میتواند از آنچه قبلاً دانلود و کامپایل کرده است استفاده مجدد کند.
اطمینان از بیلدهای قابل بازتولید با فایل Cargo.lock
Cargo مکانیزمی دارد که اطمینان میدهد شما یا هر کس دیگری بتوانید هر بار که کد خود را بیلد میکنید، همان نتیجه را دریافت کنید: Cargo تنها از نسخههایی از وابستگیها که مشخص کردهاید استفاده میکند، مگر اینکه خلاف آن را اعلام کنید. برای مثال، فرض کنید هفته آینده نسخه 0.8.6 از crate rand منتشر میشود و آن نسخه شامل یک رفع باگ مهم است، اما همچنین شامل یک برگشت (regression) است که کد شما را خراب میکند. برای مدیریت این موضوع، Rust فایل Cargo.lock را در اولین باری که cargo build را اجرا میکنید ایجاد میکند، بنابراین اکنون این فایل در دایرکتوری guessing_game وجود دارد.
وقتی برای اولین بار پروژهای را بیلد میکنید، Cargo همه نسخههای وابستگیهایی که با معیارها تطابق دارند را پیدا میکند و سپس آنها را به فایل Cargo.lock مینویسد. وقتی در آینده پروژه خود را بیلد میکنید، Cargo میبیند که فایل Cargo.lock وجود دارد و از نسخههای مشخصشده در آن استفاده میکند، به جای اینکه تمام کار پیدا کردن نسخهها را دوباره انجام دهد. این کار به شما اجازه میدهد که بهطور خودکار یک بیلد قابل بازتولید داشته باشید. به عبارت دیگر، پروژه شما در نسخه 0.8.5 باقی خواهد ماند تا زمانی که به صورت صریح آن را بهروزرسانی کنید، به لطف فایل Cargo.lock. چون فایل Cargo.lock برای بیلدهای قابل بازتولید مهم است، معمولاً همراه با بقیه کد پروژه در سیستم کنترل نسخه (source control) ذخیره میشود.
بهروزرسانی یک crate برای دریافت نسخه جدید
وقتی میخواهید یک crate را بهروزرسانی کنید، Cargo دستور update را فراهم میکند که فایل Cargo.lock را نادیده میگیرد و تمام نسخههای جدیدی که با مشخصات شما در فایل Cargo.toml سازگار هستند را پیدا میکند. سپس Cargo آن نسخهها را به فایل Cargo.lock مینویسد. در این مورد، Cargo تنها به دنبال نسخههایی میگردد که بالاتر از 0.8.5 و کمتر از 0.9.0 باشند. اگر crate rand دو نسخه جدید 0.8.6 و 0.9.0 را منتشر کرده باشد، با اجرای cargo update چنین چیزی را خواهید دید:
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.9.0)
Cargo نسخه 0.9.0 را نادیده میگیرد. در این مرحله، شما همچنین تغییری در فایل Cargo.lock مشاهده میکنید که نشان میدهد نسخه crate rand که اکنون استفاده میکنید 0.8.6 است. برای استفاده از نسخه 0.9.0 rand یا هر نسخهای در سری 0.9.x، باید فایل Cargo.toml را به این شکل تغییر دهید:
[dependencies]
rand = "0.9.0"
دفعه بعد که cargo build را اجرا کنید، Cargo رجیستری جعبهها (crates)ی موجود را بهروزرسانی میکند و نیازمندیهای شما برای rand را بر اساس نسخه جدیدی که مشخص کردهاید ارزیابی میکند.
چیزهای بیشتری درباره Cargo و اکوسیستم آن وجود دارد که در فصل 14 بحث خواهیم کرد، اما فعلاً این تمام چیزی است که باید بدانید. Cargo استفاده از کتابخانهها را بسیار آسان میکند، بنابراین Rustaceans میتوانند پروژههای کوچکتری بنویسند که از تعدادی بسته تشکیل شدهاند.
تولید یک عدد تصادفی
بیایید استفاده از rand را برای تولید یک عدد برای حدس زدن شروع کنیم. مرحله بعد بهروزرسانی فایل src/main.rs است، همانطور که در لیستینگ 2-3 نشان داده شده است.
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}ابتدا خط use rand::Rng; را اضافه میکنیم. صفت (trait) Rng متدهایی را تعریف میکند که تولیدکنندگان اعداد تصادفی پیادهسازی میکنند، و این صفت باید در دامنه باشد تا بتوانیم از آن متدها استفاده کنیم. فصل 10 بهطور مفصل به بررسی صفتها خواهد پرداخت.
سپس دو خط در وسط اضافه میکنیم. در خط اول، تابع rand::thread_rng را فراخوانی میکنیم که تولیدکننده اعداد تصادفی خاصی را که میخواهیم استفاده کنیم به ما میدهد: تولیدکنندهای که محلی برای نخ فعلی اجرا است و توسط سیستمعامل seed میشود. سپس متد gen_range را روی تولیدکننده اعداد تصادفی فراخوانی میکنیم. این متد توسط صفت Rng که با دستور use rand::Rng; وارد دامنه کردیم، تعریف شده است. متد gen_range یک عبارت بازهای را بهعنوان آرگومان میگیرد و یک عدد تصادفی در آن بازه تولید میکند. نوع عبارت بازهای که در اینجا استفاده میکنیم به صورت start..=end است و شامل حد پایین و بالا میشود، بنابراین باید 1..=100 را مشخص کنیم تا عددی بین 1 تا 100 درخواست کنیم.
نکته: شما نمیتوانید بهطور پیشفرض بدانید که کدام صفتها را باید استفاده کنید و کدام متدها و توابع را از یک crate فراخوانی کنید، بنابراین هر crate دارای مستنداتی با دستورالعملهایی برای استفاده از آن است. ویژگی جالب دیگر Cargo این است که اجرای دستور
cargo doc --openمستندات ارائهشده توسط تمام وابستگیهای شما را بهصورت محلی میسازد و در مرورگر شما باز میکند. اگر به دیگر قابلیتهای craterandعلاقهمند هستید، برای مثال دستورcargo doc --openرا اجرا کنید و رویrandدر نوار کناری سمت چپ کلیک کنید.
خط جدید دوم عدد مخفی را چاپ میکند. این خط در حین توسعه برنامه برای آزمایش آن مفید است، اما در نسخه نهایی آن را حذف خواهیم کرد. اگر برنامه به محض شروع پاسخ را چاپ کند، خیلی بازی هیجانانگیزی نخواهد بود!
برنامه را چند بار اجرا کنید:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
شما باید اعداد تصادفی متفاوتی دریافت کنید و تمام آنها باید بین 1 تا 100 باشند. عالی!
مقایسه حدس با عدد مخفی
حالا که ورودی کاربر و یک عدد تصادفی داریم، میتوانیم آنها را مقایسه کنیم. این مرحله در لیستینگ 2-4 نشان داده شده است. توجه داشته باشید که این کد هنوز کامپایل نخواهد شد، همانطور که توضیح خواهیم داد.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}ابتدا یک دستور use دیگر اضافه میکنیم تا نوعی به نام std::cmp::Ordering را از کتابخانه استاندارد وارد دامنه کنیم. نوع Ordering یک enum دیگر است و دارای متغیرهای Less، Greater و Equal است. اینها سه نتیجه ممکن هنگام مقایسه دو مقدار هستند.
سپس پنج خط جدید در انتهای کد اضافه میکنیم که از نوع Ordering استفاده میکنند. متد cmp دو مقدار را مقایسه میکند و میتواند روی هر چیزی که قابل مقایسه باشد فراخوانی شود. این متد یک ارجاع به مقداری که میخواهید مقایسه کنید میگیرد: در اینجا مقایسه بین guess و secret_number است. سپس یکی از متغیرهای enum Ordering که با دستور use به دامنه آوردیم را بازمیگرداند. از یک عبارت match برای تصمیمگیری در مورد اقدام بعدی بر اساس اینکه کدام متغیر Ordering از فراخوانی cmp با مقادیر guess و secret_number بازگشته است استفاده میکنیم.
یک عبارت match از شاخهها (arms) تشکیل شده است. یک شاخه شامل یک الگو برای مطابقت است و کدی که باید اجرا شود اگر مقدار دادهشده به match با الگوی آن شاخه تطابق داشته باشد. Rust مقدار دادهشده به match را گرفته و به ترتیب هر الگوی شاخه را بررسی میکند. الگوها و سازه match از ویژگیهای قدرتمند Rust هستند: آنها به شما اجازه میدهند موقعیتهای مختلفی که کد شما ممکن است با آنها روبرو شود را بیان کنید و اطمینان حاصل کنید که همه آنها را مدیریت میکنید. این ویژگیها بهطور مفصل در فصل 6 و فصل 19 پوشش داده خواهند شد.
بیایید با یک مثال از عبارت match که در اینجا استفاده کردهایم، آن را بررسی کنیم. فرض کنید کاربر 50 را حدس زده و عدد مخفی که این بار بهطور تصادفی تولید شده 38 است.
وقتی کد 50 را با 38 مقایسه میکند، متد cmp مقدار Ordering::Greater را بازمیگرداند زیرا 50 بزرگتر از 38 است. عبارت match مقدار Ordering::Greater را گرفته و شروع به بررسی هر الگوی شاخه میکند. به الگوی شاخه اول، Ordering::Less نگاه میکند و میبیند که مقدار Ordering::Greater با Ordering::Less تطابق ندارد، بنابراین کد موجود در آن شاخه را نادیده میگیرد و به شاخه بعدی میرود. الگوی شاخه بعدی Ordering::Greater است که با Ordering::Greater تطابق دارد! کد مرتبط با آن شاخه اجرا شده و عبارت Too big! را روی صفحه چاپ میکند. عبارت match پس از اولین تطابق موفقیتآمیز پایان مییابد، بنابراین در این سناریو به شاخه آخر نگاه نمیکند.
با این حال، کد موجود در لیستینگ 2-4 هنوز کامپایل نخواهد شد. بیایید آن را امتحان کنیم:
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/4eb161250e340c8f48f66e2b929ef4a5bed7c181/library/core/src/cmp.rs:964:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
هسته خطا بیان میکند که انواع ناسازگار وجود دارند. Rust دارای یک سیستم نوع قوی و ایستا است. با این حال، همچنین دارای استنباط نوع است. وقتی let mut guess = String::new() نوشتیم، Rust توانست استنباط کند که guess باید یک String باشد و نیازی نبود که نوع را بهصورت صریح بنویسیم. از طرف دیگر، secret_number یک نوع عددی است. چند نوع عددی در Rust میتوانند مقداری بین 1 و 100 داشته باشند: i32، یک عدد 32 بیتی؛ u32، یک عدد بدون علامت 32 بیتی؛ i64، یک عدد 64 بیتی؛ و دیگران. مگر اینکه خلاف آن مشخص شده باشد، Rust بهطور پیشفرض از i32 استفاده میکند، که نوع secret_number است مگر اینکه اطلاعات نوع دیگری اضافه کنید که باعث شود Rust نوع عددی دیگری را استنباط کند. دلیل خطا این است که Rust نمیتواند یک رشته و یک نوع عددی را مقایسه کند.
در نهایت، میخواهیم String که برنامه بهعنوان ورودی میخواند را به یک نوع عددی تبدیل کنیم تا بتوانیم آن را بهصورت عددی با عدد مخفی مقایسه کنیم. این کار را با اضافه کردن این خط به بدنه تابع main انجام میدهیم:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}خط موردنظر این است:
let guess: u32 = guess.trim().parse().expect("Please type a number!");ما یک متغیر به نام guess ایجاد میکنیم. اما صبر کنید، آیا برنامه قبلاً یک متغیر به نام guess ندارد؟ دارد، اما Rust بهطور مفیدی به ما اجازه میدهد مقدار قبلی guess را با یک مقدار جدید پوشش دهیم. پوششدهی به ما اجازه میدهد که از نام متغیر guess دوباره استفاده کنیم، بهجای اینکه مجبور شویم دو متغیر منحصربهفرد مانند guess_str و guess ایجاد کنیم. این موضوع را در فصل 3 با جزئیات بیشتری بررسی خواهیم کرد، اما فعلاً بدانید که این ویژگی اغلب زمانی استفاده میشود که بخواهید مقدار را از یک نوع به نوع دیگری تبدیل کنید.
ما این متغیر جدید را به عبارت guess.trim().parse() متصل میکنیم. guess در این عبارت به متغیر اصلی guess که ورودی بهصورت رشتهای بود اشاره دارد. متد trim روی یک نمونه String تمام فضای سفید در ابتدا و انتهای رشته را حذف میکند، که قبل از تبدیل رشته به u32 که فقط میتواند دادههای عددی داشته باشد، باید این کار را انجام دهیم. کاربر باید کلید enter را فشار دهد تا read_line مقدار ورودی را دریافت کند، که یک کاراکتر newline به رشته اضافه میکند. برای مثال، اگر کاربر کلید 5 را تایپ کند و enter را فشار دهد، guess به این شکل خواهد بود: 5\n. \n نشاندهنده “خط جدید” است. (در ویندوز، فشار دادن enter منجر به carriage return و newline، یعنی \r\n میشود.) متد trim \n یا \r\n را حذف میکند و نتیجه فقط 5 است.
متد parse روی رشتهها یک رشته را به نوع دیگری تبدیل میکند. اینجا از آن برای تبدیل یک رشته به عدد استفاده میکنیم. باید به Rust نوع عدد دقیق موردنظرمان را با استفاده از let guess: u32 بگوییم. علامت : بعد از guess به Rust میگوید که نوع متغیر را مشخص خواهیم کرد. Rust چند نوع عدد داخلی دارد؛ u32 که اینجا دیده میشود، یک عدد صحیح 32 بیتی بدون علامت است. این یک انتخاب پیشفرض خوب برای یک عدد مثبت کوچک است. درباره دیگر انواع عددی در فصل 3 خواهید آموخت.
علاوه بر این، حاشیهنویسی u32 در این برنامه نمونه و مقایسه با secret_number به این معناست که Rust استنباط خواهد کرد که secret_number نیز باید یک u32 باشد. بنابراین اکنون مقایسه بین دو مقدار از یک نوع خواهد بود!
متد parse فقط روی کاراکترهایی کار میکند که منطقی بتوان آنها را به اعداد تبدیل کرد و بنابراین بهراحتی میتواند باعث خطا شود. برای مثال، اگر رشتهای شامل A👍% باشد، هیچ راهی برای تبدیل آن به عدد وجود ندارد. چون ممکن است این عملیات شکست بخورد، متد parse نوع Result را برمیگرداند، دقیقاً مانند متد read_line (که قبلاً در “مدیریت خطای احتمالی با Result” بحث کردیم). ما این Result را همانطور که قبلاً انجام دادیم با استفاده مجدد از متد expect مدیریت خواهیم کرد. اگر parse متغیر Err از نوع Result را برگرداند زیرا نتوانست یک عدد از رشته ایجاد کند، فراخوانی expect بازی را متوقف کرده و پیام مشخصشده را چاپ میکند. اگر parse بتواند با موفقیت رشته را به عدد تبدیل کند، متغیر Ok از نوع Result را برمیگرداند و expect عدد مورد نظر را از مقدار Ok بازمیگرداند.
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
عالی! حتی با اینکه قبل از حدس کاربر فاصلههایی اضافه شده بود، برنامه همچنان تشخیص داد که کاربر عدد 76 را حدس زده است. برنامه را چند بار اجرا کنید تا رفتارهای مختلف را با انواع مختلف ورودی بررسی کنید: عدد را درست حدس بزنید، عددی که خیلی بزرگ است حدس بزنید، و عددی که خیلی کوچک است را حدس بزنید.
اکنون بیشتر بخشهای بازی کار میکند، اما کاربر فقط میتواند یک حدس بزند. بیایید این موضوع را با اضافه کردن یک حلقه تغییر دهیم!
اجازه دادن به چندین حدس با استفاده از حلقه
کلمه کلیدی loop یک حلقه بینهایت ایجاد میکند. ما یک حلقه اضافه میکنیم تا به کاربران فرصتهای بیشتری برای حدس زدن عدد بدهیم:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}همانطور که میبینید، ما همه چیز از درخواست ورودی حدس به بعد را داخل یک حلقه قرار دادهایم. مطمئن شوید که خطوط داخل حلقه را چهار فاصله دیگر تورفتگی (indentation) بدهید و برنامه را دوباره اجرا کنید. اکنون برنامه بهطور بیپایان از شما حدس میخواهد، که در واقع یک مشکل جدید ایجاد میکند. به نظر میرسد که کاربر نمیتواند از برنامه خارج شود!
کاربر همیشه میتواند برنامه را با استفاده از میانبر صفحهکلید ctrl-c متوقف کند. اما راه دیگری برای فرار از این هیولای سیریناپذیر وجود دارد، همانطور که در بحث parse در “مقایسه حدس با عدد مخفی” ذکر شد: اگر کاربر پاسخی غیرعددی وارد کند، برنامه متوقف میشود. میتوانیم از این موضوع استفاده کنیم تا به کاربر اجازه دهیم خارج شود، همانطور که در اینجا نشان داده شده است:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
Please type a number!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
تایپ کردن quit باعث خروج از بازی میشود، اما همانطور که متوجه خواهید شد، وارد کردن هر ورودی غیرعددی دیگر نیز همین کار را انجام میدهد. این رفتار چندان بهینه نیست؛ ما میخواهیم بازی همچنین وقتی عدد درست حدس زده شد متوقف شود.
خروج پس از حدس درست
بیایید برنامه را طوری تنظیم کنیم که وقتی کاربر برنده میشود، با افزودن یک دستور break از بازی خارج شود:
Filename: src/main.rs
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}اضافه کردن خط break بعد از You win! باعث میشود که برنامه وقتی کاربر عدد مخفی را بهدرستی حدس میزند، از حلقه خارج شود. خروج از حلقه همچنین به معنای خروج از برنامه است، زیرا حلقه آخرین بخش از main است.
مدیریت ورودی نامعتبر
برای بهبود بیشتر رفتار بازی، به جای اینکه برنامه هنگام ورود ورودی غیرعددی توسط کاربر متوقف شود، بیایید بازی را طوری تنظیم کنیم که ورودی غیرعددی را نادیده بگیرد تا کاربر بتواند به حدس زدن ادامه دهد. این کار را میتوان با تغییر خطی که در آن guess از یک String به یک u32 تبدیل میشود انجام داد، همانطور که در لیستینگ 2-5 نشان داده شده است.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}ما از یک فراخوانی expect به یک عبارت match تغییر میدهیم تا به جای متوقف کردن برنامه در صورت خطا، خطا را مدیریت کنیم. به یاد داشته باشید که parse یک نوع Result بازمیگرداند و Result یک enum است که دارای متغیرهای Ok و Err است. ما در اینجا از یک عبارت match استفاده میکنیم، همانطور که با نتیجه Ordering از متد cmp انجام دادیم.
اگر parse بتواند رشته را با موفقیت به یک عدد تبدیل کند، یک مقدار Ok بازمیگرداند که عدد تولیدشده را در خود دارد. مقدار Ok با الگوی شاخه اول مطابقت خواهد داشت و عبارت match فقط مقدار num که parse تولید کرده و در داخل مقدار Ok قرار داده است را بازمیگرداند. آن عدد در همان جایی که میخواهیم، در متغیر جدید guess که ایجاد میکنیم، قرار میگیرد.
اگر parse نتواند رشته را به عدد تبدیل کند،
یک مقدار Err بازمیگرداند که اطلاعات بیشتری
دربارهی خطا در خود دارد. مقدار Err با الگوی
Ok(num) در شاخهی اول match تطابق ندارد،
اما با الگوی Err(_) در شاخهی دوم مطابقت دارد.
کاراکتر زیرخط، یعنی _، یک مقدار عمومی است
که همهچیز را شامل میشود؛ در این مثال، ما
میگوییم که میخواهیم تمام مقادیر Err را
صرفنظر از محتوای داخلی آنها، تطبیق دهیم.
در نتیجه، برنامه کد شاخهی دوم یعنی continue
را اجرا میکند، که به برنامه میگوید به دور بعدی
حلقهی loop برود و یک حدس دیگر بگیرد.
در عمل، برنامه تمام خطاهایی را که parse ممکن است
با آن مواجه شود نادیده میگیرد!
حالا همه چیز در برنامه باید طبق انتظار کار کند. بیایید آن را امتحان کنیم:
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
عالی! با یک تغییر کوچک نهایی، بازی حدس زدن را کامل خواهیم کرد. به یاد داشته باشید که برنامه همچنان عدد مخفی را چاپ میکند. این کار برای آزمایش خوب بود، اما بازی را خراب میکند. بیایید دستور println! که عدد مخفی را خروجی میدهد حذف کنیم. لیستینگ 2-6 کد نهایی را نشان میدهد.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}در این مرحله، شما با موفقیت بازی حدس زدن را ساختهاید. تبریک میگویم!
خلاصه
این پروژه یک روش عملی برای معرفی بسیاری از مفاهیم جدید Rust به شما بود: let، match، توابع، استفاده از جعبهها (crates)ی خارجی، و موارد دیگر. در چند فصل بعدی، این مفاهیم را با جزئیات بیشتری یاد خواهید گرفت. فصل 3 مفاهیمی را که بیشتر زبانهای برنامهنویسی دارند، مانند متغیرها، انواع داده و توابع را پوشش میدهد و نشان میدهد چگونه از آنها در Rust استفاده کنید. فصل 4 مالکیت را بررسی میکند، ویژگیای که Rust را از زبانهای دیگر متمایز میکند. فصل 5 ساختارها و نحو متدها را مورد بحث قرار میدهد و فصل 6 توضیح میدهد که enumها چگونه کار میکنند.
مفاهیم رایج برنامهنویسی
این فصل مفاهیمی را پوشش میدهد که در تقریباً هر زبان برنامهنویسی وجود دارند و نحوه کار آنها در Rust را توضیح میدهد. بسیاری از زبانهای برنامهنویسی در هسته خود اشتراکات زیادی دارند. هیچیک از مفاهیم ارائهشده در این فصل مختص Rust نیستند، اما ما آنها را در زمینه Rust مورد بحث قرار میدهیم و قراردادهای مرتبط با استفاده از این مفاهیم را توضیح میدهیم.
به طور خاص، شما با متغیرها، انواع پایه، توابع، نظرات و جریان کنترل آشنا خواهید شد. این مبانی در هر برنامه Rust وجود خواهند داشت و یادگیری آنها در اوایل کار، پایه قویای برای شروع به شما میدهد.
کلمات کلیدی
زبان Rust مجموعهای از کلمات کلیدی دارد که فقط برای استفاده توسط زبان رزرو شدهاند، همانند سایر زبانها. به خاطر داشته باشید که نمیتوانید از این کلمات بهعنوان نام متغیرها یا توابع استفاده کنید. اکثر کلمات کلیدی معانی خاصی دارند و شما از آنها برای انجام وظایف مختلف در برنامههای Rust خود استفاده خواهید کرد؛ تعدادی از آنها در حال حاضر هیچ عملکردی ندارند اما برای قابلیتهایی که ممکن است در آینده به Rust اضافه شوند رزرو شدهاند. شما میتوانید لیست کلمات کلیدی را در ضمیمه الف پیدا کنید.
متغیرها و تغییرپذیری
همانطور که در بخش [“ذخیره مقادیر با استفاده از متغیرها”][storing-values-with-variables] ذکر شد، به طور پیشفرض متغیرها در Rust غیرقابلتغییر هستند. این یکی از راههایی است که Rust شما را به نوشتن کدی که از ایمنی و همزمانی آسان ارائهشده توسط این زبان بهره میبرد، تشویق میکند. با این حال، شما همچنان گزینهای دارید تا متغیرهای خود را قابلتغییر کنید. بیایید بررسی کنیم که چگونه و چرا Rust شما را تشویق به استفاده از غیرقابلتغییر بودن میکند و چرا ممکن است گاهی بخواهید این حالت را تغییر دهید.
وقتی یک متغیر غیرقابلتغییر است، وقتی مقداری به یک نام متصل شد، نمیتوانید آن مقدار را تغییر دهید. برای نشان دادن این موضوع، یک پروژه جدید به نام variables در دایرکتوری projects خود ایجاد کنید با استفاده از دستور cargo new variables.
سپس، در دایرکتوری جدید variables خود، فایل src/main.rs را باز کنید و کد آن را با کد زیر جایگزین کنید، که هنوز کامپایل نخواهد شد:
تام فایل: src/main.rs
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}فایل را ذخیره کنید و برنامه را با استفاده از cargo run اجرا کنید. باید یک پیام خطا در مورد غیرقابلتغییر بودن دریافت کنید، همانطور که در این خروجی نشان داده شده است:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
این مثال نشان میدهد که چگونه کامپایلر به شما کمک میکند تا خطاها را در برنامههای خود پیدا کنید. خطاهای کامپایلر ممکن است ناامیدکننده باشند، اما در واقع به این معنا هستند که برنامه شما هنوز به طور ایمن کاری را که میخواهید انجام نمیدهد؛ این به هیچ وجه به این معنا نیست که شما برنامهنویس خوبی نیستید! حتی برنامهنویسان باتجربه Rust نیز همچنان خطاهای کامپایلر دریافت میکنند.
شما پیام خطای cannot assign twice to immutable variable `x` را دریافت کردید زیرا سعی کردید مقدار دوم را به متغیر غیرقابلتغییر x تخصیص دهید.
این بسیار مهم است که ما خطاهای زمان کامپایل را دریافت کنیم وقتی سعی میکنیم مقدار یک متغیر غیرقابلتغییر را تغییر دهیم زیرا این وضعیت میتواند به باگ منجر شود. اگر یک بخش از کد ما با این فرض عمل کند که یک مقدار هرگز تغییر نمیکند و بخش دیگری از کد آن مقدار را تغییر دهد، ممکن است بخش اول کد کاری که برای انجام آن طراحی شده بود را به درستی انجام ندهد. علت این نوع باگ میتواند بعد از وقوع به سختی قابلردیابی باشد، بهویژه وقتی که بخش دوم کد فقط گاهی اوقات مقدار را تغییر میدهد. کامپایلر Rust تضمین میکند که وقتی بیان میکنید یک مقدار تغییر نخواهد کرد، واقعاً تغییر نخواهد کرد، بنابراین نیازی نیست که خودتان این موضوع را پیگیری کنید. به این ترتیب کد شما راحتتر قابلدرک خواهد بود.
اما قابلیت تغییر میتواند بسیار مفید باشد و نوشتن کد را راحتتر کند. اگرچه متغیرها به طور پیشفرض غیرقابلتغییر هستند، میتوانید با اضافه کردن mut قبل از نام متغیر آنها را قابلتغییر کنید، همانطور که در [فصل ۲][storing-values-with-variables] انجام دادید. اضافه کردن mut همچنین به خوانندگان آینده کد نیت شما را نشان میدهد که قسمتهای دیگر کد مقدار این متغیر را تغییر خواهند داد.
برای مثال، بیایید فایل src/main.rs را به کد زیر تغییر دهیم:
fn main() { let mut x = 5; println!("The value of x is: {x}"); x = 6; println!("The value of x is: {x}"); }
وقتی اکنون برنامه را اجرا میکنیم، این خروجی را دریافت میکنیم:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
ما اجازه داریم مقدار مرتبط با x را از 5 به 6 تغییر دهیم وقتی که از mut استفاده شود. در نهایت، تصمیمگیری در مورد استفاده یا عدم استفاده از قابلیت تغییر به عهده شما است و به این بستگی دارد که در آن موقعیت خاص چه چیزی واضحتر به نظر میرسد.
ثابت ها
مانند متغیرهای غیرقابلتغییر، ثابتها مقادیری هستند که به یک نام متصل میشوند و اجازه تغییر ندارند، اما چند تفاوت بین ثابتها و متغیرها وجود دارد.
اول، شما نمیتوانید از mut با ثابتها استفاده کنید. ثابتها نه تنها به طور پیشفرض غیرقابلتغییر هستند، بلکه همیشه غیرقابلتغییر هستند. شما ثابتها را با استفاده از کلیدواژه const به جای کلیدواژه let تعریف میکنید و نوع مقدار باید مشخص شود. ما در بخش بعدی [“انواع داده”][data-types] درباره انواع و حاشیهنویسی نوع صحبت خواهیم کرد، بنابراین نگران جزئیات آن در حال حاضر نباشید. فقط بدانید که همیشه باید نوع را مشخص کنید.
ثابتها میتوانند در هر دامنهای، از جمله دامنهی جهانی، تعریف شوند، که این ویژگی آنها را برای مقادیری که بخشهای مختلف کد باید بدانند مفید میسازد.
آخرین تفاوت این است که ثابتها فقط میتوانند به یک عبارت ثابت تنظیم شوند، نه نتیجهای که فقط میتواند در زمان اجرا محاسبه شود.
در اینجا یک مثال از تعریف ثابت آورده شده است:
#![allow(unused)] fn main() { const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3; }
نام ثابت THREE_HOURS_IN_SECONDS است و مقدار آن برابر با نتیجه ضرب ۶۰ (تعداد ثانیهها در یک دقیقه) در ۶۰ (تعداد دقیقهها در یک ساعت) در ۳ (تعداد ساعتهایی که میخواهیم در این برنامه شمارش کنیم) تنظیم شده است. قانون نامگذاری ثابتها در Rust استفاده از حروف بزرگ با خط زیر (_) بین کلمات است. کامپایلر قادر است مجموعه محدودی از عملیات را در زمان کامپایل ارزیابی کند، که به ما این امکان را میدهد تا این مقدار را به صورتی بنویسیم که آسانتر قابلدرک و بررسی باشد، به جای تنظیم این ثابت به مقدار ۱۰،۸۰۰. برای اطلاعات بیشتر در مورد اینکه چه عملیاتهایی میتوانند در زمان تعریف ثابتها استفاده شوند، به [بخش ارزیابی ثابتها در مرجع Rust][const-eval] مراجعه کنید.
ثابتها برای تمام مدت اجرای یک برنامه، در دامنهای که در آن تعریف شدهاند، معتبر هستند. این ویژگی، ثابتها را برای مقادیر موجود در دامنه برنامه شما که ممکن است بخشهای مختلف برنامه نیاز به دانستن آنها داشته باشند، مانند حداکثر تعداد امتیازاتی که هر بازیکن یک بازی میتواند کسب کند یا سرعت نور، مفید میسازد.
نامگذاری مقادیر ثابت در سراسر برنامه شما به عنوان ثابتها، در انتقال معنی آن مقدار به نگهدارندگان آینده کد شما مفید است. همچنین این کمک میکند که فقط یک مکان در کد وجود داشته باشد که اگر مقدار ثابت نیاز به بهروزرسانی داشت، باید تغییر کند.
Shadowing
همانطور که در آموزش بازی حدس زدن در [فصل ۲][comparing-the-guess-to-the-secret-number] دیدید، شما میتوانید یک متغیر جدید با همان نام متغیر قبلی تعریف کنید. Rustaceanها میگویند که متغیر اول توسط متغیر دوم سایه انداخته شده است، به این معنا که متغیر دوم چیزی است که کامپایلر وقتی از نام متغیر استفاده میکنید میبیند. در واقع، متغیر دوم متغیر اول را تحتالشعاع قرار میدهد، استفادههای مربوط به نام متغیر را به خود اختصاص میدهد تا زمانی که یا خودش تحتالشعاع قرار بگیرد یا دامنه تمام شود. ما میتوانیم یک متغیر را با استفاده از همان نام متغیر و تکرار استفاده از کلیدواژه let به شرح زیر سایهاندازی کنیم:
Filename: src/main.rs
fn main() { let x = 5; let x = x + 1; { let x = x * 2; println!("The value of x in the inner scope is: {x}"); } println!("The value of x is: {x}"); }
این برنامه ابتدا x را به مقدار ۵ متصل میکند. سپس یک متغیر جدید x با تکرار let x = ایجاد میکند و مقدار اصلی را میگیرد و ۱ اضافه میکند، بنابراین مقدار x به ۶ تغییر میکند. سپس، در یک دامنه داخلی که با آکولادها ایجاد شده است، عبارت سوم let نیز x را سایهاندازی میکند و یک متغیر جدید ایجاد میکند که مقدار قبلی را در ۲ ضرب میکند و به x مقدار ۱۲ میدهد. وقتی آن دامنه تمام میشود، سایهاندازی داخلی پایان مییابد و x به مقدار ۶ بازمیگردد. وقتی این برنامه را اجرا میکنیم، خروجی زیر را دریافت میکنیم:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
سایهاندازی با علامتگذاری متغیر بهعنوان mut متفاوت است، زیرا اگر به طور تصادفی سعی کنید به این متغیر بدون استفاده از کلیدواژه let مقدار جدیدی تخصیص دهید، یک خطای زمان کامپایل دریافت میکنید. با استفاده از let، ما میتوانیم چند تبدیل روی یک مقدار انجام دهیم، اما متغیر بعد از اتمام این تبدیلها غیرقابل تغییر باقی میماند.
تفاوت دیگر بین mut و سایهاندازی این است که به دلیل اینکه ما عملاً یک متغیر جدید ایجاد میکنیم وقتی دوباره از کلیدواژه let استفاده میکنیم، میتوانیم نوع مقدار را تغییر دهیم اما همان نام را دوباره استفاده کنیم. برای مثال، فرض کنید برنامه ما از یک کاربر میخواهد تا نشان دهد که چند فاصله میخواهد بین متنهای خاص داشته باشد با وارد کردن کاراکترهای فاصله، و سپس میخواهیم آن ورودی را بهعنوان یک عدد ذخیره کنیم:
fn main() { let spaces = " "; let spaces = spaces.len(); }
اولین متغیر spaces یک نوع رشته است و دومین متغیر spaces یک نوع عدد است. سایهاندازی در نتیجه ما را از نیاز به یافتن نامهای مختلف، مانند spaces_str و spaces_num نجات میدهد. به جای آن، میتوانیم از نام سادهتر spaces استفاده کنیم. با این حال، اگر سعی کنیم برای این کار از mut استفاده کنیم، همانطور که در اینجا نشان داده شده است، یک خطای زمان کامپایل دریافت میکنیم:
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}خطا میگوید که مجاز نیستیم نوع متغیر را تغییر دهیم:
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
حال که بررسی کردیم متغیرها چگونه کار میکنند، بیایید نگاهی به انواع دادههای بیشتری بیندازیم که متغیرها میتوانند داشته باشند.
انواع دادهها
هر مقدار در زبان راست نوع خاصی از داده را دارد که به راست میگوید چه نوع دادهای مشخص شده است تا بداند چگونه با آن داده کار کند. ما به دو زیرمجموعه از انواع داده نگاه خواهیم کرد: انواع ساده و ترکیبی.
به خاطر داشته باشید که راست یک زبان ایستا-تایپ است، به این معنا که باید نوع تمام متغیرها در زمان کامپایل مشخص باشد. کامپایلر معمولاً میتواند بر اساس مقدار و نحوه استفاده از آن، نوع مورد نظر ما را حدس بزند. در مواردی که انواع متعددی ممکن است، مانند زمانی که یک String را به نوع عددی تبدیل کردیم در بخش “مقایسه حدس با عدد مخفی” در فصل 2، باید یک تعریف نوع اضافه کنیم، مانند این:
#![allow(unused)] fn main() { let guess: u32 = "42".parse().expect("Not a number!"); }
اگر تعریف نوع : u32 را که در کد بالا آمده است اضافه نکنیم، راست خطای زیر را نمایش میدهد، که به معنای این است که کامپایلر به اطلاعات بیشتری از ما نیاز دارد تا بداند کدام نوع را میخواهیم استفاده کنیم:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
شما تعریفهای نوع مختلفی برای انواع دادههای دیگر خواهید دید.
انواع ساده
یک نوع ساده نمایانگر یک مقدار واحد است. راست چهار نوع ساده اصلی دارد: اعداد صحیح، اعداد اعشاری، بولینها و کاراکترها. ممکن است اینها را از زبانهای برنامهنویسی دیگر بشناسید. بیایید ببینیم چگونه در راست کار میکنند.
انواع اعداد صحیح
یک عدد صحیح عددی بدون جزء اعشاری است. ما در فصل 2 از یک نوع عدد صحیح به نام u32 استفاده کردیم. این تعریف نوع نشان میدهد که مقدار مرتبط باید یک عدد صحیح بدون علامت (انواع اعداد صحیح با علامت با i به جای u شروع میشوند) باشد که 32 بیت فضا اشغال میکند. جدول 3-1 انواع اعداد صحیح ساخته شده در راست را نشان میدهد. ما میتوانیم از هر یک از این حالتها برای تعریف نوع یک مقدار عدد صحیح استفاده کنیم.
جدول 3-1: انواع اعداد صحیح در راست
| طول | علامتدار | بدونعلامت |
|---|---|---|
| ۸-بیتی | i8 | u8 |
| ۱۶-بیتی | i16 | u16 |
| ۳۲-بیتی | i32 | u32 |
| ۶۴-بیتی | i64 | u64 |
| ۱۲۸-بیتی | i128 | u128 |
| وابسته به معماری | isize | usize |
هر حالت میتواند یا با علامت یا بدون علامت باشد و اندازه صریحی دارد. با علامت و بدون علامت به این اشاره دارند که آیا ممکن است عدد منفی باشد یا خیر؛ به عبارت دیگر، آیا عدد نیاز به علامت دارد (با علامت) یا اینکه فقط مثبت خواهد بود و بنابراین میتوان آن را بدون علامت نشان داد (بدون علامت). این شبیه به نوشتن اعداد روی کاغذ است: وقتی علامت مهم باشد، عدد با علامت مثبت یا منفی نشان داده میشود؛ اما وقتی فرض مثبت بودن عدد ایمن باشد، بدون علامت نشان داده میشود. اعداد با علامت با استفاده از نمایش دو مکمل ذخیره میشوند.
هر نوع عدد صحیح علامتدار میتواند مقادیری از
−(2n − 1) تا 2n − 1 − 1 را
در بر بگیرد، که در آن n تعداد بیتهای استفادهشده
توسط آن نوع است. بنابراین، یک i8 میتواند
مقادیر بین −(27) تا 27 − 1
را نگه دارد، یعنی از −۱۲۸ تا ۱۲۷.
انواع بدونعلامت (unsigned) میتوانند مقادیر
بین ۰ تا 2n − 1 را نگهداری کنند؛
مثلاً یک u8 میتواند مقادیری از ۰ تا
28 − 1، یعنی از ۰ تا ۲۵۵ را ذخیره کند.
علاوه بر این، نوعهای isize و usize به
معماری سیستمی بستگی دارند که برنامه روی آن
اجرا میشود: اگر معماری ۶۴ بیتی باشد، این نوعها
۶۴ بیتی هستند، و اگر ۳۲ بیتی باشد، ۳۲ بیتی خواهند بود.
شما میتوانید اعداد صحیح را به هر یک از اشکال نشان داده شده در جدول 3-2 بنویسید. توجه داشته باشید که عددهایی که میتوانند به چندین نوع عددی تبدیل شوند، یک پسوند نوع دارند، مانند 57u8، برای تعیین نوع. اعداد همچنین میتوانند از _ به عنوان جداکننده بصری برای خواناتر کردن استفاده کنند، مانند 1_000، که همان مقدار 1000 را دارد.
جدول 3-2: نمایش اعداد صحیح در راست
| نوع اعداد | مثال |
|---|---|
| دهدهی | 98_222 |
| هگزادسیمال | 0xff |
| اکتال | 0o77 |
| باینری | 0b1111_0000 |
بایت (فقط u8) | b'A' |
حال چگونه میدانید که از کدام نوع عدد صحیح استفاده کنید؟ اگر مطمئن نیستید، مقادیر پیشفرض راست معمولاً مکان خوبی برای شروع هستند: نوعهای عدد صحیح پیشفرض به i32 تبدیل میشوند. وضعیت اصلی که در آن ممکن است از isize یا usize استفاده کنید زمانی است که میخواهید به یک نوع مجموعه اشاره کنید.
سرریز عدد صحیح
فرض کنید یک متغیر از نوع u8 دارید که میتواند مقادیر بین 0 و 255 را نگه دارد. اگر تلاش کنید مقدار متغیر را به عددی خارج از این بازه، مانند 256، تغییر دهید، سرریز عدد صحیح رخ خواهد داد که میتواند منجر به یکی از دو رفتار شود. وقتی برنامه خود را در حالت دیباگ کامپایل میکنید، راست شامل بررسیهایی برای سرریز عدد صحیح است که باعث میشود برنامه شما در زمان اجرا پانیک کند اگر این رفتار رخ دهد. راست از اصطلاح پانیک کردن زمانی استفاده میکند که برنامه با یک خطا خارج شود؛ ما در بخش “خطاهای غیرقابل بازیابی با panic!” در فصل 9 به طور عمیقتر درباره پانیکها بحث خواهیم کرد.
وقتی برنامه خود را در حالت انتشار با پرچم --release کامپایل میکنید، راست این بررسیها را برای سرریز عدد صحیح شامل نمیشود. در عوض، اگر سرریز رخ دهد، راست از دو مکمل بستهبندی استفاده میکند. به طور خلاصه، مقادیر بزرگتر از حداکثر مقداری که نوع میتواند نگه دارد به “حداقل مقادیر” بازه نوع بستهبندی میشوند. در مورد یک u8، مقدار 256 به 0 تبدیل میشود، مقدار 257 به 1 و غیره. برنامه پانیک نخواهد کرد، اما متغیر مقدار متفاوتی نسبت به آنچه انتظار میرفت خواهد داشت. اعتماد به رفتار بستهبندی سرریز عدد صحیح یک خطا محسوب میشود.
برای مدیریت صریح امکان سرریز، میتوانید از این خانوادههای روشها استفاده کنید که توسط کتابخانه استاندارد برای نوعهای عددی اولیه ارائه شدهاند:
- در همه حالتها با استفاده از متدهای
wrapping_*مانندwrapping_add، مقدار را wrap میکند. - در صورت بروز overflow، مقدار
Noneرا با متدهایchecked_*بازمیگرداند. - مقدار و یک مقدار Boolean که نشان میدهد overflow رخ داده یا نه، با متدهای
overflowing_*بازمیگردد. - در مقدار حداقل یا حداکثر نوع متوقف میشود (saturate) با استفاده از متدهای
saturating_*.
انواع اعداد اعشاری
راست همچنین دو نوع اولیه برای اعداد اعشاری دارد، که اعدادی با نقطه اعشار هستند. نوعهای اعشاری راست f32 و f64 هستند که به ترتیب 32 بیت و 64 بیت اندازه دارند. نوع پیشفرض f64 است زیرا روی CPUهای مدرن، سرعت آن تقریباً مشابه f32 است اما دقت بیشتری دارد. همه نوعهای اعشاری علامتدار هستند.
در اینجا مثالی که اعداد اعشاری را در عمل نشان میدهد آورده شده است:
Filename: src/main.rs
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
اعداد اعشاری طبق استاندارد IEEE-754 نمایش داده میشوند.
عملیات عددی
راست از عملیات ریاضی پایهای که برای تمام انواع عددی انتظار دارید پشتیبانی میکند: جمع، تفریق، ضرب، تقسیم و باقیمانده. تقسیم اعداد صحیح به نزدیکترین عدد صحیح به سمت صفر گرد میشود. کد زیر نشان میدهد چگونه میتوانید از هر عملیات عددی در یک عبارت let استفاده کنید:
Filename: src/main.rs
fn main() { // addition let sum = 5 + 10; // subtraction let difference = 95.5 - 4.3; // multiplication let product = 4 * 30; // division let quotient = 56.7 / 32.2; let truncated = -5 / 3; // Results in -1 // remainder let remainder = 43 % 5; }
هر عبارت در این دستورات از یک عملگر ریاضی استفاده میکند و به یک مقدار واحد ارزیابی میشود، که سپس به یک متغیر متصل میشود. ضمیمه ب شامل لیستی از تمام عملگرهایی است که راست فراهم میکند.
نوع بولین
مانند اکثر زبانهای برنامهنویسی دیگر، نوع بولین در راست دو مقدار ممکن دارد: true و false. نوع بولین در راست یک بایت اندازه دارد. نوع بولین در راست با استفاده از bool مشخص میشود. برای مثال:
Filename: src/main.rs
fn main() { let t = true; let f: bool = false; // with explicit type annotation }
راه اصلی استفاده از مقادیر بولین از طریق عبارات شرطی، مانند عبارت if است. ما در بخش “جریان کنترل” توضیح میدهیم که چگونه عبارات if در راست کار میکنند.
نوع کاراکتر
نوع char در راست ابتداییترین نوع الفبایی زبان است. در اینجا برخی از مثالهای اعلام مقادیر char آورده شده است:
Filename: src/main.rs
fn main() { let c = 'z'; let z: char = 'ℤ'; // with explicit type annotation let heart_eyed_cat = '😻'; }
توجه داشته باشید که literals نوع char با
نقلقولهای تکی مشخص میشوند، در حالی که literals
رشتهای (string) از نقلقولهای دوتایی استفاده میکنند.
نوع char در Rust اندازهای برابر با چهار بایت
دارد و نمایانگر یک مقدار اسکالر یونیکد است، به این
معنا که میتواند بسیار بیشتر از فقط کاراکترهای
ASCII را نمایش دهد. حروف دارای اعراب، کاراکترهای
چینی، ژاپنی و کرهای، ایموجیها و فضاهای بدون عرض
همگی مقادیر معتبر char در Rust هستند. مقدارهای
اسکالر یونیکد در بازهی U+0000 تا U+D7FF و
U+E000 تا U+10FFFF شامل میشوند. با این حال،
مفهوم “کاراکتر” در یونیکد واقعاً وجود ندارد،
بنابراین تصور انسانی شما از “کاراکتر” ممکن است با
آنچه char در Rust است تفاوت داشته باشد. این موضوع
را در بخش «ذخیره متن کدگذاریشده UTF-8 با رشتهها»
در فصل ۸ بهطور مفصل بررسی خواهیم کرد.
انواع ترکیبی
انواع ترکیبی میتوانند چندین مقدار را در یک نوع گروهبندی کنند. راست دو نوع ترکیبی اولیه دارد: تاپلها و آرایهها.
نوع تاپل
تاپل یک روش کلی برای گروهبندی چند مقدار با انواع مختلف در یک نوع ترکیبی است. تاپلها طول ثابتی دارند: پس از اعلام، نمیتوانند بزرگتر یا کوچکتر شوند.
ما یک تاپل را با نوشتن یک لیست جدا شده با کاما از مقادیر در داخل پرانتز ایجاد میکنیم. هر موقعیت در تاپل یک نوع دارد، و انواع مقادیر مختلف در تاپل نیازی به یکسان بودن ندارند. ما در این مثال حاشیهنویسی نوع اختیاری اضافه کردهایم:
Filename: src/main.rs
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
متغیر tup به کل تاپل متصل میشود زیرا یک تاپل به عنوان یک عنصر ترکیبی واحد در نظر گرفته میشود. برای استخراج مقادیر جداگانه از یک تاپل، میتوانیم از تطابق الگو برای تجزیه مقدار تاپل استفاده کنیم، مانند این:
Filename: src/main.rs
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {y}"); }
این برنامه ابتدا یک تاپل ایجاد کرده و آن را به متغیر tup متصل میکند. سپس از یک الگو با let برای گرفتن tup و تبدیل آن به سه متغیر جداگانه، x، y، و z استفاده میکند. این فرآیند تجزیه نامیده میشود زیرا تاپل واحد را به سه قسمت تقسیم میکند. در نهایت، برنامه مقدار y را که 6.4 است، چاپ میکند.
ما همچنین میتوانیم یک عنصر از تاپل را مستقیماً با استفاده از یک نقطه (.) به دنبال شماره شاخص مقدار مورد نظر دسترسی داشته باشیم. برای مثال:
Filename: src/main.rs
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; }
این برنامه تاپل x را ایجاد کرده و سپس به هر عنصر تاپل با استفاده از شاخصهای مربوطه آنها دسترسی پیدا میکند. همانند اکثر زبانهای برنامهنویسی، اولین شاخص در یک تاپل 0 است.
تاپل بدون هیچ مقداری یک نام خاص دارد، واحد. این مقدار و نوع مربوط به آن هر دو با () نوشته میشوند و یک مقدار خالی یا یک نوع بازگشت خالی را نشان میدهند. عبارات به طور ضمنی مقدار واحد را بازمیگردانند اگر هیچ مقدار دیگری بازنگردانند.
نوع آرایه
روش دیگری برای داشتن مجموعهای از چند مقدار، استفاده از آرایه است. برخلاف تاپل، هر عنصر آرایه باید از یک نوع باشد. برخلاف آرایهها در برخی زبانهای دیگر، آرایهها در راست طول ثابتی دارند.
ما مقادیر یک آرایه را به صورت یک لیست جدا شده با کاما در داخل کروشه مینویسیم:
Filename: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; }
آرایهها زمانی کاربردی هستند که بخواهید دادههایتان روی stack تخصیص یابند، مشابه سایر نوعهایی که تاکنون دیدیم، نه روی heap (که در فصل ۴ بیشتر دربارهی stack و heap صحبت خواهیم کرد) یا زمانی که میخواهید همیشه تعداد ثابتی از عناصر داشته باشید. با این حال، آرایه به اندازهی نوع vector انعطافپذیر نیست. وکتور نوعی مجموعه مشابه است که توسط کتابخانه استاندارد ارائه شده و اجازه دارد اندازهاش تغییر کند، چون محتوای آن روی heap ذخیره میشود. اگر مطمئن نیستید که از آرایه استفاده کنید یا وکتور، احتمالاً بهتر است وکتور را انتخاب کنید. فصل ۸ بهطور دقیقتر دربارهی وکتورها بحث میکند.
با این حال، آرایهها زمانی مفیدتر هستند که بدانید تعداد عناصر نیاز به تغییر ندارد. برای مثال، اگر از نامهای ماه در یک برنامه استفاده میکردید، احتمالاً از یک آرایه به جای یک وکتور استفاده میکردید زیرا میدانید همیشه ۱۲ عنصر خواهد داشت:
#![allow(unused)] fn main() { let months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]; }
شما نوع یک آرایه را با استفاده از کروشهها به همراه نوع هر عنصر، یک نقطه ویرگول، و سپس تعداد عناصر در آرایه مینویسید، مانند این:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
در اینجا، i32 نوع هر عنصر است. پس از نقطه ویرگول، عدد ۵ نشان میدهد که آرایه شامل پنج عنصر است.
شما همچنین میتوانید یک آرایه را طوری مقداردهی اولیه کنید که هر عنصر مقدار یکسانی داشته باشد، با مشخص کردن مقدار اولیه، یک نقطه ویرگول، و سپس طول آرایه در کروشهها، مانند این:
#![allow(unused)] fn main() { let a = [3; 5]; }
آرایهای با نام a شامل ۵ عنصر خواهد بود که همه ابتدا مقدار ۳ دارند. این همان نوشتن let a = [3, 3, 3, 3, 3]; است، اما به شیوهای مختصرتر.
دسترسی به عناصر آرایه
یک آرایه یک بخش واحد از حافظه با اندازهای مشخص و ثابت است که میتواند روی استک تخصیص داده شود. شما میتوانید به عناصر یک آرایه با استفاده از ایندکس دسترسی پیدا کنید، مانند این:
Filename: src/main.rs
fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; let second = a[1]; }
در این مثال، متغیری با نام first مقدار 1 را میگیرد زیرا این مقدار در ایندکس [0] در آرایه قرار دارد. متغیری با نام second مقدار 2 را از ایندکس [1] در آرایه میگیرد.
دسترسی نامعتبر به عنصر آرایه
ببینیم چه اتفاقی میافتد اگر بخواهید به عنصری از آرایه دسترسی پیدا کنید که خارج از محدوده آرایه است. فرض کنید این کد را اجرا کنید که مشابه بازی حدس در فصل ۲ است، تا یک ایندکس آرایه را از کاربر دریافت کند:
Filename: src/main.rs
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}این کد به درستی کامپایل میشود. اگر این کد را با استفاده از cargo run اجرا کنید و مقادیری مانند 0، 1، 2، 3 یا 4 را وارد کنید، برنامه مقدار متناظر در آن ایندکس از آرایه را چاپ میکند. اما اگر به جای آن عددی خارج از محدوده آرایه، مانند 10، وارد کنید، خروجی چیزی شبیه به این خواهد بود:
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
این برنامه در نقطه استفاده از مقدار نامعتبر در عملیات ایندکسگذاری دچار خطای زمان اجرا شد. برنامه با یک پیام خطا خاتمه یافت و دستور نهایی println! را اجرا نکرد. زمانی که شما تلاش میکنید به یک عنصر با استفاده از ایندکس دسترسی پیدا کنید، راست بررسی میکند که ایندکسی که مشخص کردهاید کمتر از طول آرایه باشد. اگر ایندکس بزرگتر یا برابر با طول باشد، راست متوقف میشود (پانیک میکند). این بررسی باید در زمان اجرا انجام شود، بهویژه در این مورد، زیرا کامپایلر نمیتواند بداند که کاربر چه مقداری را هنگام اجرای کد وارد خواهد کرد.
این یک مثال از اصول ایمنی حافظه راست در عمل است. در بسیاری از زبانهای سطح پایین، این نوع بررسی انجام نمیشود و زمانی که شما یک ایندکس اشتباه ارائه میکنید، میتوان به حافظه نامعتبر دسترسی پیدا کرد. راست شما را از این نوع خطا با متوقف کردن فوری برنامه به جای اجازه دسترسی به حافظه و ادامه برنامه محافظت میکند. فصل ۹ خطایابی در راست و نحوه نوشتن کد خوانا و ایمن که نه دچار پانیک شود و نه اجازه دسترسی نامعتبر به حافظه را بدهد، بیشتر بررسی میکند.
توابع
توابع در کدهای راست بسیار رایج هستند. شما تاکنون یکی از مهمترین توابع در این زبان را دیدهاید: تابع main، که نقطه ورود بسیاری از برنامهها است. همچنین با کلمه کلیدی fn آشنا شدید که به شما امکان تعریف توابع جدید را میدهد.
کدهای راست از حالت snake case به عنوان سبک متعارف برای نامگذاری توابع و متغیرها استفاده میکنند، که در آن تمام حروف کوچک هستند و کلمات با زیرخط از یکدیگر جدا میشوند. این یک برنامه است که شامل یک مثال از تعریف تابع میباشد:
Filename: src/main.rs
fn main() { println!("Hello, world!"); another_function(); } fn another_function() { println!("Another function."); }
ما با وارد کردن fn به همراه نام تابع و یک مجموعه پرانتز، یک تابع را در راست تعریف میکنیم. کروشههای باز و بسته به کامپایلر میگویند که بدنه تابع از کجا شروع و پایان مییابد.
ما میتوانیم هر تابعی را که تعریف کردهایم با وارد کردن نام آن به همراه یک مجموعه پرانتز فراخوانی کنیم. از آنجا که another_function در برنامه تعریف شده است، میتوان آن را از داخل تابع main فراخوانی کرد. توجه داشته باشید که ما another_function را بعد از تابع main در کد منبع تعریف کردیم؛ همچنین میتوانستیم آن را قبل از آن تعریف کنیم. راست اهمیتی نمیدهد که توابع شما کجا تعریف شدهاند، فقط باید در محدودهای باشند که توسط فراخوانی کننده قابل مشاهده باشد.
بیایید یک پروژه باینری جدید به نام functions ایجاد کنیم تا توابع را بیشتر بررسی کنیم. مثال another_function را در فایل src/main.rs قرار دهید و آن را اجرا کنید. باید خروجی زیر را مشاهده کنید:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
دستورات به ترتیبی که در تابع main ظاهر شدهاند اجرا میشوند. ابتدا پیام “Hello, world!” چاپ میشود و سپس another_function فراخوانی شده و پیام آن چاپ میشود.
پارامترها
ما میتوانیم توابعی تعریف کنیم که پارامتر داشته باشند، که متغیرهای خاصی هستند که بخشی از امضای تابع محسوب میشوند. وقتی یک تابع پارامتر دارد، شما میتوانید مقادیر مشخصی برای آن پارامترها ارائه دهید. از نظر فنی، به مقادیر مشخص آرگومان گفته میشود، اما در مکالمات معمول، مردم معمولاً از کلمات پارامتر و آرگومان به جای یکدیگر استفاده میکنند، چه برای متغیرهای تعریف شده در یک تابع یا مقادیر مشخص هنگام فراخوانی تابع.
در این نسخه از another_function، ما یک پارامتر اضافه میکنیم:
Filename: src/main.rs
fn main() { another_function(5); } fn another_function(x: i32) { println!("The value of x is: {x}"); }
این برنامه را اجرا کنید؛ باید خروجی زیر را ببینید:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
اعلان another_function دارای یک پارامتر به نام x است. نوع x به عنوان i32 مشخص شده است. وقتی ما مقدار 5 را به another_function میدهیم، ماکروی println! مقدار 5 را در جایی که جفت کروشه حاوی x در رشته فرمت بود، قرار میدهد.
در امضای توابع، شما باید نوع هر پارامتر را اعلام کنید. این یک تصمیم عمدی در طراحی راست است: نیاز به حاشیهنویسی نوع در تعریف توابع به این معنا است که کامپایلر تقریباً هرگز نیازی به استفاده از آنها در جاهای دیگر کد برای فهمیدن نوع مورد نظر شما ندارد. کامپایلر همچنین قادر است پیامهای خطای مفیدتری ارائه دهد اگر بداند تابع چه نوعهایی انتظار دارد.
هنگام تعریف چندین پارامتر، اعلام پارامترها را با کاما جدا کنید، مانند این:
Filename: src/main.rs
fn main() { print_labeled_measurement(5, 'h'); } fn print_labeled_measurement(value: i32, unit_label: char) { println!("The measurement is: {value}{unit_label}"); }
این مثال یک تابع به نام print_labeled_measurement با دو پارامتر ایجاد میکند. پارامتر اول به نام value و از نوع i32 است. پارامتر دوم به نام unit_label و از نوع char است. سپس تابع متنی حاوی هر دو value و unit_label را چاپ میکند.
بیایید این کد را اجرا کنیم. برنامهای که در حال حاضر در فایل src/main.rs پروژه functions شما است را با مثال بالا جایگزین کنید و آن را با استفاده از cargo run اجرا کنید:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
از آنجا که ما تابع را با 5 به عنوان مقدار برای value و 'h' به عنوان مقدار برای unit_label فراخوانی کردیم، خروجی برنامه شامل این مقادیر است.
اظهارات و عبارات
بدنه توابع از یک سری اظهارات تشکیل شده است که به طور اختیاری با یک عبارت پایان مییابند. تاکنون، توابعی که پوشش دادهایم شامل یک عبارت پایانی نبودهاند، اما شما یک عبارت را به عنوان بخشی از یک اظهار دیدهاید. از آنجا که راست یک زبان مبتنی بر عبارات است، این تمایز بسیار مهم است که درک شود. زبانهای دیگر این تمایز را ندارند، بنابراین بیایید نگاهی به اظهارات و عبارات بیندازیم و ببینیم چگونه تفاوتهای آنها بر بدن توابع تأثیر میگذارد.
- دستورات (Statements) دستورالعملهایی هستند که عملی را انجام میدهند و مقداری بازنمیگردانند.
- عبارتها (Expressions) مقداری را ارزیابی و بازمیگردانند.
بیایید چند مثال بررسی کنیم.
ما در واقع قبلاً از اظهارات و عبارات استفاده کردهایم. ایجاد یک متغیر و اختصاص یک مقدار به آن با کلمه کلیدی let یک اظهار است. در لیستینگ ۳-۱، let y = 6; یک اظهار است.
fn main() { let y = 6; }
main که شامل یک اظهار استتعریف توابع نیز از نوع دستورات (statements) است؛ کل مثال قبلی خود یک دستور محسوب میشود. (همانطور که در ادامه خواهیم دید، فراخوانی تابع اما یک دستور نیست.)
اظهارات هیچ مقداری باز نمیگردانند. بنابراین، نمیتوانید یک اظهار let را به یک متغیر دیگر اختصاص دهید، همانطور که کد زیر سعی دارد انجام دهد؛ شما با یک خطا روبرو خواهید شد:
Filename: src/main.rs
fn main() {
let x = (let y = 6);
}وقتی این برنامه را اجرا کنید، خطایی که دریافت خواهید کرد به شکل زیر خواهد بود:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
اظهار let y = 6 هیچ مقداری باز نمیگرداند، بنابراین چیزی برای اتصال به x وجود ندارد. این با آنچه در زبانهای دیگر، مانند C و Ruby رخ میدهد، متفاوت است، جایی که تخصیص مقدار باز میگرداند. در آن زبانها، میتوانید x = y = 6 بنویسید و هر دو x و y مقدار 6 را داشته باشند؛ این حالت در راست وجود ندارد.
عبارات به یک مقدار ارزیابی میشوند و بیشتر بقیه کدی که در راست مینویسید را تشکیل میدهند. به عنوان مثال یک عملیات ریاضی، مانند 5 + 6، که یک عبارت است که به مقدار 11 ارزیابی میشود. عبارات میتوانند بخشی از اظهارات باشند: در لیستینگ ۳-۱، مقدار 6 در اظهار let y = 6; یک عبارت است که به مقدار 6 ارزیابی میشود. فراخوانی یک تابع یک عبارت است. فراخوانی یک ماکرو یک عبارت است. یک بلوک جدید از دامنه که با کروشههای باز و بسته ایجاد شده است نیز یک عبارت است، برای مثال:
Filename: src/main.rs
fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {y}"); }
این عبارت:
{
let x = 3;
x + 1
}یک بلوک است که در این مورد به مقدار 4 ارزیابی میشود. آن مقدار به عنوان بخشی از اظهار let به y متصل میشود. توجه داشته باشید که خط x + 1 در انتها یک نقطه ویرگول ندارد، که برخلاف اکثر خطوطی است که تاکنون دیدهاید. عبارات شامل نقطه ویرگول انتهایی نمیشوند. اگر به انتهای یک عبارت یک نقطه ویرگول اضافه کنید، آن را به یک اظهار تبدیل میکنید و دیگر مقداری باز نمیگرداند. این نکته را در ذهن داشته باشید زیرا در ادامه به بررسی مقادیر بازگشتی توابع و عبارات میپردازیم.
توابع با مقادیر بازگشتی
توابع میتوانند مقادیری را به کدی که آنها را فراخوانی کرده است بازگردانند. ما به مقادیر بازگشتی نام نمیدهیم، اما باید نوع آنها را بعد از یک فلش (->) اعلام کنیم. در راست، مقدار بازگشتی تابع معادل مقدار عبارت نهایی در بلوک بدنه تابع است. شما میتوانید با استفاده از کلمه کلیدی return و مشخص کردن یک مقدار، زودتر از یک تابع بازگردید، اما بیشتر توابع به طور ضمنی مقدار آخرین عبارت را بازمیگردانند. در اینجا یک مثال از یک تابع که مقدار بازمیگرداند آورده شده است:
Filename: src/main.rs
fn five() -> i32 { 5 } fn main() { let x = five(); println!("The value of x is: {x}"); }
هیچ فراخوانی تابع، ماکرو یا حتی اظهار let در تابع five وجود ندارد—فقط عدد 5 به تنهایی. این یک تابع کاملاً معتبر در راست است. توجه کنید که نوع مقدار بازگشتی تابع نیز به صورت -> i32 مشخص شده است. این کد را اجرا کنید؛ خروجی باید به صورت زیر باشد:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
عدد 5 در five مقدار بازگشتی تابع است، به همین دلیل نوع بازگشتی i32 است. بیایید این موضوع را با جزئیات بیشتری بررسی کنیم. دو نکته مهم وجود دارد: اول، خط let x = five(); نشان میدهد که ما از مقدار بازگشتی یک تابع برای مقداردهی یک متغیر استفاده میکنیم. چون تابع five مقدار 5 را بازمیگرداند، این خط مشابه خط زیر است:
#![allow(unused)] fn main() { let x = 5; }
دوم، تابع five هیچ پارامتری ندارد و نوع مقدار بازگشتی را تعریف میکند، اما بدنه تابع یک عدد تنها 5 بدون نقطه ویرگول است زیرا این یک عبارت است که مقدار آن را میخواهیم بازگردانیم.
بیایید به مثال دیگری نگاه کنیم:
Filename: src/main.rs
fn main() { let x = plus_one(5); println!("The value of x is: {x}"); } fn plus_one(x: i32) -> i32 { x + 1 }
اجرای این کد مقدار The value of x is: 6 را چاپ خواهد کرد. اما اگر یک نقطه ویرگول به انتهای خط حاوی x + 1 اضافه کنیم و آن را از یک عبارت به یک اظهار تبدیل کنیم، با خطا مواجه خواهیم شد:
Filename: src/main.rs
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}کامپایل این کد خطایی به شرح زیر تولید میکند:
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
پیام خطای اصلی، mismatched types، مسئله اصلی این کد را آشکار میکند. تعریف تابع plus_one میگوید که این تابع یک i32 بازمیگرداند، اما اظهارات به یک مقدار ارزیابی نمیشوند، که با ()، نوع واحد، نشان داده میشود. بنابراین، چیزی بازگردانده نمیشود که با تعریف تابع تناقض دارد و باعث ایجاد خطا میشود. در این خروجی، راست پیامی ارائه میدهد تا شاید به حل این مشکل کمک کند: پیشنهاد حذف نقطه ویرگول، که این خطا را برطرف میکند.
کامنتها
تمام برنامهنویسان تلاش میکنند کدهایشان را به گونهای بنویسند که به راحتی قابل فهم باشد، اما گاهی اوقات توضیحات اضافی لازم است. در این موارد، برنامهنویسان کامنتهایی را در کد منبع خود میگذارند که کامپایلر آنها را نادیده میگیرد اما ممکن است برای افرادی که کد منبع را میخوانند مفید باشد.
در اینجا یک کامنت ساده آورده شده است:
#![allow(unused)] fn main() { // hello, world }
در راست، سبک متعارف کامنتگذاری با دو اسلش شروع میشود و کامنت تا پایان خط ادامه دارد. برای کامنتهایی که بیشتر از یک خط هستند، باید روی هر خط از // استفاده کنید، به این صورت:
#![allow(unused)] fn main() { // پس ما در اینجا کاری پیچیده انجام میدهیم، بهقدری طولانی // که نیاز به چندین خط توضیح داریم! هُف! امیدوارم این کامنت // آنچه در جریان است را به خوبی توضیح دهد. }
کامنتها همچنین میتوانند در انتهای خطوطی که حاوی کد هستند قرار گیرند:
Filename: src/main.rs
fn main() { let lucky_number = 7; // I'm feeling lucky today }
اما بیشتر مواقع کامنتها را در این قالب خواهید دید، با کامنتی که در خط جداگانهای بالای کدی که توضیح میدهد قرار دارد:
Filename: src/main.rs
fn main() { // I'm feeling lucky today let lucky_number = 7; }
راست همچنین نوع دیگری از کامنتها، کامنتهای مستندات (documentation comments) دارد که آنها را در بخش “انتشار یک کرات در Crates.io” از فصل 14 بررسی خواهیم کرد.
کنترل جریان
توانایی اجرای کدی که وابسته به درست بودن یا نبودن یک شرط است و اجرای مکرر کدی در حالی که یک شرط درست است، از ساختارهای اساسی در بیشتر زبانهای برنامهنویسی محسوب میشود. رایجترین ساختارهایی که به شما امکان کنترل جریان اجرای کد در راست را میدهند، عبارتند از عبارات if و حلقهها.
عبارات if
یک عبارت if به شما امکان میدهد کد خود را بسته به شرایطی شاخهبندی کنید. شما یک شرط مشخص میکنید و سپس میگویید: «اگر این شرط برقرار بود، این بلوک کد اجرا شود. اگر شرط برقرار نبود، این بلوک کد اجرا نشود.»
یک پروژه جدید به نام branches در دایرکتوری projects خود ایجاد کنید تا عبارت if را بررسی کنید. در فایل src/main.rs کد زیر را وارد کنید:
Filename: src/main.rs
fn main() { let number = 3; if number < 5 { println!("condition was true"); } else { println!("condition was false"); } }
تمام عبارات if با کلمه کلیدی if شروع میشوند و سپس یک شرط دنبال میشود. در این مثال، شرط بررسی میکند که آیا مقدار متغیر number کمتر از 5 است یا خیر. بلوک کدی که در صورت درست بودن شرط باید اجرا شود، بلافاصله بعد از شرط و داخل کروشهها قرار میگیرد. بلوکهای کدی که با شرایط در عبارات if مرتبط هستند، گاهی بازو (arm) نامیده میشوند، همانند بازوهای موجود در عبارات match که در بخش “مقایسه حدس با عدد مخفی” از فصل 2 مورد بحث قرار گرفت.
بهصورت اختیاری، میتوانیم یک عبارت else نیز اضافه کنیم، همانطور که اینجا انتخاب کردیم، تا به برنامه یک بلوک کد جایگزین برای اجرا ارائه دهیم، در صورتی که شرط به false ارزیابی شود. اگر عبارت else ارائه ندهید و شرط false باشد، برنامه بلوک if را نادیده گرفته و به بخش بعدی کد میرود.
این کد را اجرا کنید؛ باید خروجی زیر را مشاهده کنید:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
بیایید مقدار number را به مقداری تغییر دهیم که شرط false شود تا ببینیم چه اتفاقی میافتد:
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}برنامه را دوباره اجرا کنید و خروجی را مشاهده کنید:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
همچنین قابل توجه است که شرط در این کد باید یک bool باشد. اگر شرط یک bool نباشد، خطا دریافت خواهیم کرد. به عنوان مثال، این کد را اجرا کنید:
Filename: src/main.rs
fn main() {
let number = 3;
if number {
println!("number was three");
}
}این بار شرط if به مقدار 3 ارزیابی میشود و راست خطا میدهد:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
خطا نشان میدهد که راست انتظار یک bool داشت اما یک عدد صحیح دریافت کرد. برخلاف زبانهایی مانند Ruby و JavaScript، راست بهصورت خودکار تلاش نمیکند انواع غیر bool را به یک bool تبدیل کند. شما باید صریح باشید و همیشه یک bool را بهعنوان شرط به if بدهید. اگر میخواهید بلوک کد if فقط زمانی اجرا شود که یک عدد برابر 0 نباشد، میتوانید عبارت if را به این صورت تغییر دهید:
Filename: src/main.rs
fn main() { let number = 3; if number != 0 { println!("number was something other than zero"); } }
اجرای این کد number was something other than zero را چاپ خواهد کرد.
مدیریت شرایط متعدد با else if
شما میتوانید با ترکیب if و else در یک عبارت else if، شرایط متعددی را مدیریت کنید. به عنوان مثال:
Filename: src/main.rs
fn main() { let number = 6; if number % 4 == 0 { println!("number is divisible by 4"); } else if number % 3 == 0 { println!("number is divisible by 3"); } else if number % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
این برنامه چهار مسیر ممکن برای اجرا دارد. پس از اجرای آن، باید خروجی زیر را مشاهده کنید:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
هنگامی که این برنامه اجرا میشود، هر عبارت if را به ترتیب بررسی کرده و اولین بلوکی که شرط آن به true ارزیابی شود، اجرا میکند. توجه داشته باشید که حتی با وجود اینکه 6 بر 2 بخشپذیر است، خروجی number is divisible by 2 را نمیبینیم و همچنین متن number is not divisible by 4, 3, or 2 از بلوک else را نیز نمیبینیم. این به این دلیل است که راست فقط بلوک مربوط به اولین شرط درست را اجرا میکند و پس از یافتن آن، بقیه را بررسی نمیکند.
استفاده از تعداد زیادی عبارت else if میتواند کد شما را شلوغ کند، بنابراین اگر بیش از یک مورد دارید، ممکن است بخواهید کد خود را بازنویسی کنید. فصل 6 یک ساختار شاخهبندی قدرتمند در راست به نام match را برای این موارد توضیح میدهد.
استفاده از if در یک عبارت let
از آنجایی که if یک عبارت است، میتوانیم از آن در سمت راست یک عبارت let برای تخصیص نتیجه به یک متغیر استفاده کنیم، همانطور که در لیست 3-2 نشان داده شده است.
fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {number}"); }
if به یک متغیرمتغیر number به مقداری بر اساس نتیجه عبارت if متصل خواهد شد. این کد را اجرا کنید تا ببینید چه اتفاقی میافتد:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
به خاطر داشته باشید که بلوکهای کد به آخرین عبارت در آنها ارزیابی میشوند و اعداد به تنهایی نیز عبارات محسوب میشوند. در این حالت، مقدار کل عبارت if بستگی به این دارد که کدام بلوک کد اجرا شود. این بدان معناست که مقادیری که میتوانند نتایج هر بازوی if باشند، باید از یک نوع باشند. در لیست 3-2، نتایج بازوی if و بازوی else هر دو اعداد صحیح i32 بودند. اگر انواع ناسازگار باشند، مانند مثال زیر، خطایی دریافت خواهیم کرد:
Filename: src/main.rs
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}هنگامی که تلاش میکنیم این کد را کامپایل کنیم، خطایی دریافت میکنیم. بازوهای if و else دارای انواع مقداری ناسازگار هستند و راست دقیقاً نشان میدهد که مشکل در برنامه کجاست:
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
عبارت موجود در بلوک if به یک عدد صحیح ارزیابی میشود و عبارت موجود در بلوک else به یک رشته ارزیابی میشود. این کار نمیکند زیرا متغیرها باید یک نوع مشخص داشته باشند و راست باید در زمان کامپایل بداند که نوع متغیر number چیست. دانستن نوع number به کامپایلر این امکان را میدهد که بررسی کند نوع آن در هر جایی که از number استفاده میکنیم معتبر است. راست نمیتوانست این کار را انجام دهد اگر نوع number تنها در زمان اجرا مشخص میشد. کامپایلر پیچیدهتر میشد و تضمینهای کمتری درباره کد ارائه میداد اگر مجبور بود انواع فرضی مختلفی را برای هر متغیر پیگیری کند.
تکرار با حلقهها
اغلب مفید است که یک بلوک کد بیش از یک بار اجرا شود. برای این کار، Rust چندین حلقه ارائه میدهد که کد داخل بدنه حلقه را اجرا کرده و سپس بلافاصله به ابتدای حلقه بازمیگردند. برای آزمایش با حلقهها، یک پروژه جدید به نام loops ایجاد کنید.
Rust سه نوع حلقه دارد: loop، while و for. بیایید هر کدام را امتحان کنیم.
تکرار کد با loop
کلمه کلیدی loop به Rust میگوید که یک بلوک کد را بارها و بارها اجرا کند، تا زمانی که شما به طور صریح به آن بگویید متوقف شود.
به عنوان مثال، فایل src/main.rs را در دایرکتوری loops خود به شکل زیر تغییر دهید:
Filename: src/main.rs
fn main() {
loop {
println!("again!");
}
}وقتی این برنامه را اجرا کنیم، again! بارها و بارها به طور مداوم چاپ میشود تا زمانی که برنامه را به صورت دستی متوقف کنیم. اکثر ترمینالها از میانبر صفحه کلید ctrl-c برای متوقف کردن برنامهای که در یک حلقه بیپایان گیر کرده است، پشتیبانی میکنند. آن را امتحان کنید:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
نماد ^C نشاندهنده جایی است که کلیدهای ctrl-c
را فشار دادهاید.
ممکن است پس از ^C کلمهی again! چاپ شود یا نشود،
بسته به این که کد در کدام قسمت از حلقه هنگام دریافت سیگنال
قطع اجرا قرار داشته باشد.
خوشبختانه، Rust همچنین روشی برای خروج از یک حلقه با استفاده از کد ارائه میدهد. شما میتوانید کلمه کلیدی break را درون حلقه قرار دهید تا به برنامه بگویید که چه زمانی اجرای حلقه را متوقف کند. به یاد داشته باشید که این کار را در بازی حدس عدد در بخش “خروج پس از یک حدس درست” در فصل 2 انجام دادیم تا زمانی که کاربر با حدس درست بازی را برنده شد، برنامه خاتمه یابد.
ما همچنین از continue در بازی حدس عدد استفاده کردیم که در یک حلقه به برنامه میگوید هر کد باقیمانده در این تکرار حلقه را نادیده بگیرد و به تکرار بعدی برود.
بازگرداندن مقادیر از حلقهها
یکی از کاربردهای loop این است که یک عملیات را که ممکن است شکست بخورد دوباره امتحان کنید، مثلاً بررسی کنید که آیا یک نخ (thread) کار خود را تمام کرده است یا نه. همچنین ممکن است نیاز داشته باشید نتیجه این عملیات را از حلقه به بقیه کد خود منتقل کنید. برای انجام این کار، میتوانید مقداری که میخواهید برگردانده شود را پس از عبارت break اضافه کنید. این مقدار از حلقه بازگردانده میشود تا بتوانید از آن استفاده کنید، همانطور که در اینجا نشان داده شده است:
fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); }
قبل از حلقه، یک متغیر به نام counter اعلام میکنیم و مقدار آن را 0 مقداردهی اولیه میکنیم. سپس یک متغیر به نام result اعلام میکنیم تا مقدار بازگشتی از حلقه را نگه دارد. در هر تکرار حلقه، مقدار 1 را به متغیر counter اضافه میکنیم و سپس بررسی میکنیم که آیا مقدار counter برابر با 10 است یا نه. زمانی که این شرط برقرار باشد، از کلمه کلیدی break با مقدار counter * 2 استفاده میکنیم. پس از حلقه، با استفاده از یک سمیکالن، مقدار به result تخصیص داده میشود. در نهایت، مقدار result را چاپ میکنیم که در این مثال برابر با 20 است.
شما همچنین میتوانید از داخل یک حلقه return استفاده کنید. در حالی که break فقط از حلقه جاری خارج میشود، return همیشه از تابع جاری خارج میشود.
برچسب حلقهها برای رفع ابهام بین چندین حلقه
اگر حلقههایی تو در تو داشته باشید، break و continue به حلقه داخلیترین حلقه در آن نقطه اعمال میشوند. به طور اختیاری میتوانید یک برچسب حلقه روی یک حلقه مشخص کنید که سپس میتوانید از آن برچسب با break یا continue استفاده کنید تا مشخص کنید که این کلمات کلیدی به حلقه برچسبدار اعمال میشوند نه حلقه داخلیترین. برچسبهای حلقه باید با یک آپاستروف شروع شوند. در اینجا یک مثال با دو حلقه تو در تو آمده است:
fn main() { let mut count = 0; 'counting_up: loop { println!("count = {count}"); let mut remaining = 10; loop { println!("remaining = {remaining}"); if remaining == 9 { break; } if count == 2 { break 'counting_up; } remaining -= 1; } count += 1; } println!("End count = {count}"); }
حلقه بیرونی دارای برچسب 'counting_up است و از 0 تا 2 شمارش میکند. حلقه داخلی بدون برچسب از 10 تا 9 شمارش معکوس میکند. اولین break که برچسبی مشخص نمیکند فقط از حلقه داخلی خارج میشود. عبارت break 'counting_up; از حلقه بیرونی خارج میشود. این کد موارد زیر را چاپ میکند:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
حلقههای شرطی با while
یک برنامه اغلب نیاز دارد که یک شرط را درون یک حلقه ارزیابی کند. تا زمانی که شرط true باشد، حلقه اجرا میشود. زمانی که شرط دیگر true نباشد، برنامه با فراخوانی break، حلقه را متوقف میکند. امکان پیادهسازی چنین رفتاری با استفاده از ترکیب loop، if، else و break وجود دارد. میتوانید این را اکنون در یک برنامه امتحان کنید، اگر مایل هستید. با این حال، این الگو آنقدر رایج است که Rust یک سازه زبان داخلی برای آن دارد که به آن حلقه while گفته میشود. در Listing 3-3، از while برای اجرای برنامه سه بار، شمارش معکوس در هر بار، و سپس چاپ یک پیام و خروج از حلقه استفاده میکنیم.
fn main() { let mut number = 3; while number != 0 { println!("{number}!"); number -= 1; } println!("LIFTOFF!!!"); }
while برای اجرای کد تا زمانی که شرط مقدار true داشته باشداین سازه مقدار زیادی از تو در تویی که در صورت استفاده از loop، if، else و break لازم بود را حذف میکند و واضحتر است. تا زمانی که یک شرط به مقدار true ارزیابی شود، کد اجرا میشود؛ در غیر این صورت، حلقه متوقف میشود.
تکرار از طریق یک مجموعه با for
میتوانید از ساختار while برای تکرار روی عناصر
یک مجموعه، مانند آرایه، استفاده کنید. بهعنوان مثال،
حلقهی موجود در فهرست 3-4، هر عنصر موجود در آرایه
a را چاپ میکند.
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index += 1; } }
whileدر اینجا، کد از طریق عناصر آرایه شمارش میکند. از اندیس (index)0 شروع میکند و سپس تا زمانی که به آخرین اندیس (index)در آرایه برسد (یعنی وقتی که index < 5 دیگر true نباشد) حلقه میزند. اجرای این کد هر عنصر در آرایه را چاپ میکند:
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
همه پنج مقدار آرایه همانطور که انتظار میرود در ترمینال ظاهر میشوند. حتی اگر index در نهایت به مقدار 5 برسد، حلقه قبل از تلاش برای گرفتن مقدار ششم از آرایه متوقف میشود.
با این حال، این روش مستعد خطاست؛ ما میتوانیم باعث شویم برنامه در صورت اشتباه بودن مقدار اندیس (index)یا شرط آزمایشی متوقف شود. به عنوان مثال، اگر تعریف آرایه a را به چهار عنصر تغییر دهید اما فراموش کنید شرط را به while index < 4 بهروزرسانی کنید، کد متوقف خواهد شد. همچنین این روش کند است، زیرا کامپایلر کد زمان اجرا را برای انجام بررسی شرطی در مورد اینکه آیا اندیس (index)در محدوده آرایه است یا نه در هر تکرار حلقه اضافه میکند.
به عنوان یک جایگزین مختصرتر، میتوانید از حلقه for استفاده کنید و برای هر مورد در یک مجموعه، کدی اجرا کنید. یک حلقه for شبیه کدی در Listing 3-5 است.
fn main() { let a = [10, 20, 30, 40, 50]; for element in a { println!("the value is: {element}"); } }
forوقتی این کد را اجرا کنیم، خروجی مشابه فهرست 3-4
را خواهیم دید. مهمتر اینکه، اکنون ایمنی کد افزایش
یافته و احتمال بروز خطاهایی که ممکن است از دسترسی
فراتر از انتهای آرایه یا عدم پیمایش کامل عناصر
نشأت بگیرند، حذف شده است. همچنین، کد ماشینی که
از حلقههای for تولید میشود میتواند کارآمدتر
باشد، زیرا در هر تکرار نیازی به مقایسهی اندیس با
طول آرایه نیست.
با استفاده از حلقه for، نیازی به به خاطر سپردن تغییر کد دیگری ندارید اگر تعداد مقادیر در آرایه را تغییر دهید، همانطور که با روش استفاده شده در Listing 3-4 باید انجام میدادید.
ایمنی و مختصر بودن حلقههای for آنها را به رایجترین سازه حلقهای در Rust تبدیل کرده است. حتی در موقعیتهایی که میخواهید کدی را تعداد مشخصی از دفعات اجرا کنید، مانند مثال شمارش معکوس که از حلقه while در Listing 3-3 استفاده میکرد، اکثر برنامهنویسان Rust از حلقه for استفاده میکنند. روش انجام این کار استفاده از Range، که توسط کتابخانه استاندارد ارائه میشود، است که تمام اعداد را به ترتیب از یک عدد شروع کرده و قبل از عدد دیگری به پایان میرساند.
این چیزی است که شمارش معکوس با استفاده از یک حلقه for و روش دیگری که هنوز در مورد آن صحبت نکردهایم، یعنی rev برای معکوس کردن محدوده، به نظر میرسد:
Filename: src/main.rs
fn main() { for number in (1..4).rev() { println!("{number}!"); } println!("LIFTOFF!!!"); }
این کد کمی بهتر نیست؟
خلاصه
شما موفق شدید! این یک فصل بزرگ بود: شما درباره متغیرها، انواع داده اسکالر و مرکب، توابع، نظرات، عبارات if و حلقهها یاد گرفتید! برای تمرین با مفاهیم مطرحشده در این فصل، سعی کنید برنامههایی برای انجام موارد زیر بسازید:
- تبدیل دما بین فارنهایت و سلسیوس.
- تولید عدد nام دنباله فیبوناچی.
- چاپ متن سرود کریسمس “The Twelve Days of Christmas”، با استفاده از تکرار موجود در این آهنگ.
وقتی آماده شدید تا به مرحله بعد بروید، ما درباره مفهومی در Rust صحبت خواهیم کرد که معمولاً در زبانهای برنامهنویسی دیگر وجود ندارد: مالکیت.
درک مالکیت
مالکیت یکی از ویژگیهای منحصر به فرد Rust است و تأثیرات عمیقی بر سایر بخشهای زبان دارد. این ویژگی به Rust اجازه میدهد تا بدون نیاز به یک جمعآوری زباله (garbage collector)، تضمینهای ایمنی حافظه را فراهم کند، بنابراین درک چگونگی کارکرد مالکیت بسیار مهم است. در این فصل، ما درباره مالکیت و چند ویژگی مرتبط دیگر صحبت خواهیم کرد: قرض گرفتن (borrowing)، برشها (slices) و نحوه چیدمان دادهها در حافظه توسط Rust.
مالکیت چیست؟
مالکیت مجموعهای از قوانین است که نحوه مدیریت حافظه را در برنامههای Rust تعیین میکند. همه برنامهها باید نحوه استفاده از حافظه کامپیوتر را در هنگام اجرا مدیریت کنند. برخی زبانها از جمعآوری زباله استفاده میکنند که به طور منظم حافظهای را که دیگر استفاده نمیشود بررسی میکند؛ در دیگر زبانها، برنامهنویس باید حافظه را به صورت صریح تخصیص داده و آزاد کند. Rust از یک روش سوم استفاده میکند: حافظه از طریق سیستمی از مالکیت با مجموعهای از قوانین مدیریت میشود که کامپایلر آنها را بررسی میکند. اگر هر یک از این قوانین نقض شود، برنامه کامپایل نخواهد شد. هیچیک از ویژگیهای مالکیت برنامه شما را در هنگام اجرا کند نمیکند.
از آنجا که مالکیت یک مفهوم جدید برای بسیاری از برنامهنویسان است، زمان میبرد تا به آن عادت کنید. خبر خوب این است که هر چه بیشتر با Rust و قوانین سیستم مالکیت آن آشنا شوید، نوشتن کدی که امن و کارآمد باشد برایتان آسانتر خواهد شد. به تلاش ادامه دهید!
وقتی مالکیت را درک کنید، پایهای محکم برای درک ویژگیهایی که Rust را منحصر به فرد میکنند خواهید داشت. در این فصل، مالکیت را با کار بر روی چند مثال که بر یک ساختار داده بسیار رایج تمرکز دارند یاد خواهید گرفت: رشتهها.
استک (Stack) و هیپ (Heap)
بسیاری از زبانهای برنامهنویسی نیاز ندارند که شما زیاد دربارهی استک و هیپ فکر کنید. اما در زبانهای برنامهنویسی سیستمی مانند Rust، محل قرارگیری مقدار روی استک یا هیپ روی رفتار زبان و تصمیماتی که باید بگیرید تأثیر میگذارد. بخشهایی از مالکیت (ownership) در ارتباط با استک و هیپ در ادامهی این فصل شرح داده خواهند شد، بنابراین در اینجا توضیح کوتاهی در آمادهسازی برای آن ارائه میدهیم.
استک و هیپ هر دو بخشهایی از حافظه هستند که در زمان اجرا برای کد شما در دسترساند، اما ساختار متفاوتی دارند. استک مقادیر را به ترتیبی که دریافت میکند ذخیره کرده و آنها را به ترتیب معکوس حذف میکند. به این مدل آخرین وارد شده، اولین خارج شده (last in, first out) گفته میشود. تصور کنید یک دسته بشقاب: زمانی که بشقاب جدیدی اضافه میکنید، آن را روی بالای دسته قرار میدهید و وقتی بخواهید بشقابی بردارید، از بالای دسته برمیدارید. اضافه یا حذف کردن بشقاب از وسط یا پایین دسته به خوبی کار نخواهد کرد! افزودن داده به استک را push کردن روی استک و حذف داده را pop کردن از استک مینامند. تمامی دادههای ذخیرهشده روی استک باید اندازهای مشخص و ثابت داشته باشند. دادههایی که اندازه آنها هنگام کامپایل مشخص نیست یا ممکن است تغییر کند، باید روی هیپ ذخیره شوند.
هیپ ساختار کمتری دارد: وقتی دادهای را روی هیپ میگذارید، فضایی مشخص درخواست میکنید. تخصیصدهندهی حافظه (memory allocator) محلی خالی در هیپ پیدا میکند که بهاندازه کافی بزرگ باشد، آن را بهعنوان فضای استفادهشده علامتگذاری میکند و یک اشارهگر که آدرس آن مکان است بازمیگرداند. این فرایند را تخصیص در هیپ مینامند و گاهی بهسادگی تخصیص خوانده میشود (push کردن روی استک بهعنوان تخصیص محسوب نمیشود). چون اندازه اشارهگر روی هیپ ثابت و مشخص است، میتوانید اشارهگر را روی استک ذخیره کنید، اما وقتی به دادهی واقعی نیاز دارید، باید از طریق آن اشارهگر مراجعه کنید. این موضوع را میتوان به نشستن در رستوران تشبیه کرد: وقتی وارد میشوید، تعداد افراد گروه را میگویید، میزبان میز خالیای پیدا میکند که همه را در خود جای دهد و شما را به آنجا هدایت میکند. اگر کسی دیر برسد، میتواند بپرسد شما کجا نشستهاید تا شما را پیدا کند.
افزودن داده به استک سریعتر از تخصیص در هیپ است، زیرا تخصیصدهنده نیازی به جستجوی جای خالی برای داده جدید ندارد؛ این مکان همیشه بالای استک است. در مقایسه، تخصیص فضای هیپ نیازمند کار بیشتری است، چون ابتدا باید فضای کافی پیدا شود و سپس اقدامات لازم برای مدیریت تخصیص بعدی انجام شود.
دسترسی به دادههای روی هیپ معمولاً کندتر از دادههای روی استک است، چون باید اشارهگر را دنبال کنید. پردازندههای امروزی زمانی سریعتر کار میکنند که پرش کمتری در حافظه داشته باشند. با ادامهی تشبیه، فرض کنید یک پیشخدمت در رستوران سفارشهای میزهای مختلف را میگیرد. کارآمدترین روش این است که همه سفارشهای یک میز را کامل دریافت کند و سپس به میز بعدی برود. گرفتن سفارش از میز A، سپس میز B، دوباره میز A و سپس میز B، روندی بسیار کندتر خواهد بود. به همین ترتیب، پردازنده معمولاً بهتر کار میکند اگر روی دادههایی کار کند که به دادههای دیگر نزدیک باشند (مثل دادههای روی استک) نه دادههایی که دورتر هستند (مثل دادههای روی هیپ).
وقتی کد شما تابعی را فراخوانی میکند، مقادیری که به تابع داده میشوند (شامل اشارهگرهایی به دادههای روی هیپ) و متغیرهای محلی تابع روی استک قرار میگیرند. وقتی تابع به پایان رسید، این دادهها از استک حذف میشوند.
پیگیری اینکه کدام بخشهای کد از کدام دادهها روی هیپ استفاده میکنند، کمینهسازی دادههای تکراری روی هیپ، و پاکسازی دادههای استفادهنشده روی هیپ تا فضای کافی باقی بماند، همه مسائلی هستند که مالکیت (ownership) به آنها میپردازد. وقتی مالکیت را درک کنید، نیاز نیست زیاد دربارهی استک و هیپ فکر کنید، اما دانستن اینکه هدف اصلی مالکیت مدیریت دادههای روی هیپ است، میتواند توضیح دهد چرا مالکیت اینگونه عمل میکند.
قوانین مالکیت
ابتدا، بیایید نگاهی به قوانین مالکیت بیندازیم. این قوانین را در ذهن داشته باشید زیرا با مثالهایی که آنها را نشان میدهند کار میکنیم:
- هر مقدار در Rust یک مالک دارد.
- در یک زمان فقط میتواند یک مالک وجود داشته باشد.
- زمانی که مالک از دامنه خارج شود، مقدار حذف خواهد شد.
دامنه متغیر
حال که از سینتکس پایه Rust گذشتهایم، در مثالها کد کامل fn main() { را نخواهیم آورد. بنابراین، اگر دنبال میکنید، مطمئن شوید که مثالهای زیر را به صورت دستی داخل یک تابع main قرار دهید. در نتیجه، مثالهای ما کمی مختصرتر خواهند بود و میتوانیم بر روی جزئیات واقعی به جای کد ابتدایی تمرکز کنیم.
به عنوان اولین مثال از مالکیت، به دامنه برخی متغیرها نگاه میکنیم. دامنه محدودهای است که در آن یک آیتم در یک برنامه معتبر است. به متغیر زیر توجه کنید:
#![allow(unused)] fn main() { let s = "hello"; }
متغیر s به یک رشتهی ثابت اشاره دارد، جایی که مقدار رشته به صورت ثابت در متن برنامه ما کدنویسی شده است. این متغیر از نقطهای که اعلام شده معتبر است تا انتهای دامنه جاری. لیست 4-1 برنامهای را با توضیحاتی که نشان میدهند متغیر s در کجا معتبر است، نمایش میدهد.
fn main() { { // s is not valid here, since it's not yet declared let s = "hello"; // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no longer valid }
به عبارت دیگر، در اینجا دو نقطهی مهم زمانی وجود دارد:
- وقتی
sوارد دامنه میشود، معتبر است. - تا زمانی که از دامنه خارج شود معتبر باقی میماند.
در این نقطه، رابطه بین دامنهها و زمانهایی که متغیرها معتبر هستند مشابه با زبانهای برنامهنویسی دیگر است. حالا بر اساس این درک، نوع String را معرفی میکنیم.
نوع String
برای نشان دادن قوانین مالکیت، به نوع دادهای نیاز داریم که پیچیدهتر از آنهایی باشد که در بخش “انواع داده” فصل ۳ بررسی کردیم. انواعی که قبلاً پوشش داده شد، اندازهی مشخصی دارند، میتوانند در استک ذخیره شوند و وقتی دامنهشان تمام شد از استک برداشته شوند و میتوانند به سرعت و به سادگی برای ساختن یک نمونهی جدید و مستقل کپی شوند اگر قسمت دیگری از کد بخواهد همان مقدار را در دامنهی دیگری استفاده کند. اما ما میخواهیم به دادههایی نگاه کنیم که در هیپ ذخیره شدهاند و بررسی کنیم چگونه Rust میداند چه زمانی باید این دادهها را پاکسازی کند، و نوع String یک مثال عالی است.
ما روی بخشهایی از String تمرکز خواهیم کرد که به مالکیت مربوط میشوند. این جنبهها همچنین به سایر انواع دادههای پیچیده اعمال میشوند، چه آنهایی که توسط کتابخانه استاندارد ارائه شدهاند و چه آنهایی که خودتان ایجاد کردهاید. ما String را در فصل ۸ با جزئیات بیشتری بررسی خواهیم کرد.
قبلاً رشتههای ثابت را دیدهایم، جایی که مقدار رشته در کد ما به صورت ثابت قرار گرفته است. رشتههای ثابت راحت هستند، اما برای هر موقعیتی که ممکن است بخواهیم از متن استفاده کنیم مناسب نیستند. یکی از دلایل این است که آنها تغییرناپذیر هستند. دلیل دیگر این است که نمیتوان هر مقدار رشته را هنگام نوشتن کد خود دانست: به عنوان مثال، اگر بخواهیم ورودی کاربر را بگیریم و ذخیره کنیم چه؟ برای این شرایط، Rust یک نوع رشتهی دیگر به نام String دارد. این نوع دادههای تخصیصیافته در هیپ را مدیریت میکند و به همین دلیل میتواند مقدار متنی را ذخیره کند که اندازهی آن در زمان کامپایل برای ما ناشناخته است. شما میتوانید یک String را از یک رشتهی ثابت با استفاده از تابع from ایجاد کنید، به این صورت:
#![allow(unused)] fn main() { let s = String::from("hello"); }
عملگر :: به ما اجازه میدهد این تابع from خاص را تحت نوع String نامگذاری کنیم به جای استفاده از نوعی نام مانند string_from. این سینتکس را بیشتر در بخش “سینتکس متد” فصل ۵ و هنگامی که در مورد نامگذاری با ماژولها صحبت میکنیم در بخش “مسیرها برای ارجاع به یک آیتم در درخت ماژول” فصل ۷ بررسی خواهیم کرد.
این نوع رشته میتواند تغییر کند:
fn main() { let mut s = String::from("hello"); s.push_str(", world!"); // push_str() appends a literal to a String println!("{s}"); // this will print `hello, world!` }
پس، تفاوت اینجا چیست؟ چرا String میتواند تغییر کند اما رشتههای ثابت نمیتوانند؟ تفاوت در نحوهی مدیریت حافظه توسط این دو نوع است.
حافظه و تخصیص
در مورد یک رشتهی ثابت، ما محتوا را در زمان کامپایل میدانیم، بنابراین متن به طور مستقیم در فایل اجرایی نهایی کدنویسی شده است. به همین دلیل رشتههای ثابت سریع و کارآمد هستند. اما این ویژگیها فقط از تغییرناپذیری رشتهی ثابت ناشی میشوند. متأسفانه، نمیتوانیم یک تکه حافظه را برای هر قطعه متنی که اندازهی آن در زمان کامپایل ناشناخته است و ممکن است در حین اجرای برنامه تغییر کند، در فایل باینری قرار دهیم.
با نوع String، برای پشتیبانی از یک متن قابل تغییر و قابل رشد، ما نیاز داریم مقداری حافظه را در هیپ تخصیص دهیم که در زمان کامپایل ناشناخته است تا محتوا را نگه داریم. این به این معناست که:
- حافظه باید در زمان اجرا از تخصیصدهنده حافظه درخواست شود.
- ما نیاز داریم راهی برای بازگرداندن این حافظه به تخصیصدهنده زمانی که کارمان با
Stringتمام شد، داشته باشیم.
قسمت اول توسط ما انجام میشود: وقتی که String::from را فراخوانی میکنیم، پیادهسازی آن حافظهای را که نیاز دارد درخواست میکند. این تقریباً در تمام زبانهای برنامهنویسی رایج است.
اما قسمت دوم متفاوت است. در زبانهایی که دارای جمعکننده زباله (GC) هستند، GC حافظهای را که دیگر استفاده نمیشود پیگیری و پاکسازی میکند و ما نیازی به فکر کردن در مورد آن نداریم. در بیشتر زبانهایی که GC ندارند، این مسئولیت بر عهده ماست که مشخص کنیم چه زمانی حافظه دیگر استفاده نمیشود و کدی را برای آزادسازی صریح آن فراخوانی کنیم، دقیقاً همانطور که آن را درخواست کردهایم. انجام درست این کار در تاریخ برنامهنویسی یک مشکل دشوار بوده است. اگر فراموش کنیم، حافظه هدر میرود. اگر خیلی زود این کار را انجام دهیم، یک متغیر نامعتبر خواهیم داشت. اگر دو بار این کار را انجام دهیم، این هم یک باگ است. ما نیاز داریم دقیقاً یک allocate را با دقیقاً یک free جفت کنیم.
Rust مسیر متفاوتی را طی میکند: حافظه به طور خودکار وقتی که متغیری که مالک آن است از دامنه خارج میشود بازگردانده میشود. در اینجا نسخهای از مثال دامنه ما از فهرست ۴-۱ وجود دارد که از یک String به جای یک رشتهی ثابت استفاده میکند:
fn main() { { let s = String::from("hello"); // s is valid from this point forward // do stuff with s } // this scope is now over, and s is no // longer valid }
یک نقطه طبیعی وجود دارد که میتوانیم حافظهای را که String ما نیاز دارد به تخصیصدهنده بازگردانیم: وقتی s از دامنه خارج میشود. وقتی یک متغیر از دامنه خارج میشود، Rust یک تابع خاص را برای ما فراخوانی میکند. این تابع drop نامیده میشود، و اینجا جایی است که نویسنده String میتواند کدی برای بازگرداندن حافظه قرار دهد. Rust به طور خودکار drop را در زمان بستن آکولاد فراخوانی میکند.
نکته: در C++، این الگو که منابع در انتهای دوره عمر یک آیتم آزاد میشوند گاهی اوقات Resource Acquisition Is Initialization (RAII) نامیده میشود. تابع
dropدر Rust برای کسانی که از الگوهای RAII استفاده کردهاند آشنا خواهد بود.
این الگو تأثیر عمیقی بر نحوه نوشتن کد در Rust دارد. ممکن است اکنون ساده به نظر برسد، اما رفتار کد میتواند در موقعیتهای پیچیدهتر که میخواهیم متغیرهای متعددی از دادههایی که در هیپ تخصیص دادهایم استفاده کنند، غیرمنتظره باشد. اکنون به بررسی برخی از این موقعیتها میپردازیم.
تعامل متغیرها و دادهها با انتقال (Move)
متغیرهای مختلف میتوانند در Rust به روشهای مختلفی با دادهها تعامل داشته باشند. بیایید به مثالی با استفاده از یک عدد صحیح در فهرست ۴-۲ نگاه کنیم.
fn main() { let x = 5; let y = x; }
x به yما احتمالاً میتوانیم حدس بزنیم این کد چه میکند: “مقدار 5 را به x اختصاص بده؛ سپس یک کپی از مقدار x بگیر و آن را به y اختصاص بده.” اکنون دو متغیر داریم، x و y، و هر دو برابر 5 هستند. این دقیقاً همان چیزی است که اتفاق میافتد، زیرا اعداد صحیح مقادیر سادهای با اندازهی مشخص هستند، و این دو مقدار 5 به استک اضافه میشوند.
اکنون بیایید به نسخه String نگاه کنیم:
fn main() { let s1 = String::from("hello"); let s2 = s1; }
این بسیار مشابه به نظر میرسد، بنابراین ممکن است فرض کنیم که نحوه عملکرد آن نیز مشابه است: یعنی، خط دوم یک کپی از مقدار موجود در s1 میگیرد و آن را به s2 اختصاص میدهد. اما این دقیقاً چیزی نیست که اتفاق میافتد.
به شکل ۴-۱ نگاه کنید تا ببینید که در پشت صحنه با String چه اتفاقی میافتد. یک String از سه بخش تشکیل شده است که در سمت چپ نشان داده شدهاند: یک اشارهگر (Pointer) به حافظهای که محتوای رشته را نگه میدارد، یک طول، و یک ظرفیت. این گروه دادهها روی استک ذخیره میشوند. در سمت راست، حافظه روی هیپ قرار دارد که محتوای رشته را نگه میدارد.

شکل ۴-۱: نمایش در حافظه یک String که مقدار "hello" به s1 متصل است
طول مشخص میکند که محتوای String در حال حاضر چقدر حافظه به بایت استفاده میکند. ظرفیت مقدار کل حافظهای است که String از تخصیصدهنده دریافت کرده است. تفاوت بین طول و ظرفیت اهمیت دارد، اما نه در این زمینه، بنابراین در حال حاضر میتوان ظرفیت را نادیده گرفت.
وقتی s1 را به s2 اختصاص میدهیم، دادههای String کپی میشوند، به این معنی که اشارهگر (Pointer)، طول، و ظرفیت موجود روی استک را کپی میکنیم. ما دادههای روی هیپ را که اشارهگر (Pointer) به آن اشاره میکند، کپی نمیکنیم. به عبارت دیگر، نمایش دادهها در حافظه به شکل ۴-۲ به نظر میرسد.

شکل ۴-۲: نمایش در حافظه متغیر s2 که یک کپی از اشارهگر (Pointer)، طول، و ظرفیت s1 دارد
نمایش دادهها به این شکل نیست که در شکل ۴-۳ آمده است، که نشان میدهد حافظه به گونهای باشد که Rust همچنین دادههای هیپ را کپی کند. اگر Rust این کار را انجام میداد، عملیات s2 = s1 میتوانست از نظر عملکرد زمان اجرا بسیار گران باشد اگر دادههای روی هیپ بزرگ بودند.

شکل ۴-۳: یک امکان دیگر برای آنچه که s2 = s1 ممکن است انجام دهد اگر Rust دادههای هیپ را نیز کپی کند
قبلاً گفتیم که وقتی یک متغیر از دامنه خارج میشود، Rust به طور خودکار تابع drop را فراخوانی میکند و حافظه هیپ را برای آن متغیر پاکسازی میکند. اما شکل ۴-۲ نشان میدهد که هر دو اشارهگر (Pointer) دادهها به یک مکان اشاره میکنند. این یک مشکل است: وقتی s2 و s1 از دامنه خارج میشوند، هر دو سعی میکنند همان حافظه را آزاد کنند. این به عنوان یک خطای آزادسازی دوباره شناخته میشود و یکی از مشکلات ایمنی حافظه است که قبلاً ذکر کردیم. آزادسازی حافظه دو بار میتواند منجر به خراب شدن حافظه شود، که به طور بالقوه میتواند منجر به آسیبپذیریهای امنیتی شود.
برای اطمینان از ایمنی حافظه، پس از خط let s2 = s1;، Rust متغیر s1 را دیگر معتبر نمیداند. بنابراین، Rust نیازی به آزادسازی هیچ چیزی ندارد وقتی s1 از دامنه خارج میشود. بررسی کنید که وقتی سعی میکنید s1 را پس از ایجاد s2 استفاده کنید، چه اتفاقی میافتد؛ این کار جواب نمیدهد:
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}شما خطایی مشابه این دریافت خواهید کرد زیرا Rust از استفاده از مرجع نامعتبر جلوگیری میکند:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:15
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
اگر اصطلاحات کپی سطحی و کپی عمیق را هنگام کار با زبانهای دیگر شنیدهاید، مفهوم کپی کردن اشارهگر (Pointer)، طول، و ظرفیت بدون کپی کردن داده احتمالاً شبیه به انجام یک کپی سطحی است. اما به دلیل اینکه Rust همچنین متغیر اول را نامعتبر میکند، به جای اینکه آن را کپی سطحی بنامند، به عنوان یک انتقال شناخته میشود. در این مثال، میتوانیم بگوییم که s1 به s2 منتقل شده است. بنابراین، آنچه در واقع اتفاق میافتد در شکل ۴-۴ نشان داده شده است.

شکل ۴-۴: نمایش در حافظه پس از اینکه s1 نامعتبر شده است
این مشکل ما را حل میکند! با تنها s2 که معتبر است، وقتی از دامنه خارج میشود، تنها آن حافظه را آزاد خواهد کرد و کار ما تمام است.
علاوه بر این، یک انتخاب طراحی وجود دارد که از این نتیجهگیری میشود: Rust هرگز به طور خودکار “کپی عمیق” دادههای شما را ایجاد نمیکند. بنابراین، هر گونه کپی خودکار میتواند بهعنوان عملی ارزان از نظر عملکرد زمان اجرا در نظر گرفته شود.
دامنه و انتساب
عکس این رابطه بین دامنهبندی، مالکیت، و آزادسازی حافظه از طریق تابع drop نیز صحیح است. وقتی یک مقدار کاملاً جدید به یک متغیر موجود اختصاص میدهید، Rust تابع drop را فراخوانی میکند و حافظه مقدار اصلی را بلافاصله آزاد میکند. به این کد توجه کنید:
fn main() { let mut s = String::from("hello"); s = String::from("ahoy"); println!("{s}, world!"); }
ابتدا یک متغیر s را اعلان میکنیم و آن را به یک String با مقدار "hello" اختصاص میدهیم. سپس بلافاصله یک String جدید با مقدار "ahoy" ایجاد میکنیم و آن را به s اختصاص میدهیم. در این نقطه، هیچ چیزی به مقدار اصلی روی هیپ اشاره نمیکند.

شکل ۴-۵: نمایش در حافظه پس از اینکه مقدار اولیه به طور کامل جایگزین شده است.
رشته اصلی بلافاصله از دامنه خارج میشود. Rust تابع drop را روی آن اجرا میکند و حافظه آن بلافاصله آزاد میشود. وقتی مقدار را در انتها چاپ میکنیم، مقدار "ahoy, world!" خواهد بود.
تعامل متغیرها و دادهها با Clone
اگر بخواهیم دادههای هیپ String را عمیقاً کپی کنیم، نه فقط دادههای استک، میتوانیم از یک متد معمول به نام clone استفاده کنیم. ما نحو متدها را در فصل ۵ بررسی خواهیم کرد، اما از آنجا که متدها یک ویژگی رایج در بسیاری از زبانهای برنامهنویسی هستند، احتمالاً قبلاً آنها را دیدهاید.
در اینجا یک مثال از روش clone در عمل آورده شده است:
fn main() { let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {s1}, s2 = {s2}"); }
این کد به خوبی کار میکند و به وضوح رفتار نشان داده شده در شکل ۴-۳ را تولید میکند، جایی که دادههای هیپ کپی میشوند.
وقتی یک فراخوانی به clone میبینید، میدانید که کدی دلخواه اجرا میشود و ممکن است این کد هزینهبر باشد. این یک شاخص بصری است که نشان میدهد چیزی متفاوت در حال رخ دادن است.
دادههای فقط استک: Copy
یک نکته دیگر وجود دارد که هنوز درباره آن صحبت نکردهایم. این کد که از اعداد صحیح استفاده میکند - بخشی از آن در لیستینگ ۴-۲ نشان داده شده است - کار میکند و معتبر است:
fn main() { let x = 5; let y = x; println!("x = {x}, y = {y}"); }
اما این کد به نظر میرسد با آنچه که به تازگی یاد گرفتیم تناقض دارد: ما یک فراخوانی به clone نداریم، اما x همچنان معتبر است و به y منتقل نشده است.
دلیل این است که انواعی مانند اعداد صحیح که اندازه مشخصی در زمان کامپایل دارند، به طور کامل روی استک ذخیره میشوند، بنابراین کپی کردن مقادیر واقعی سریع است. این به این معناست که هیچ دلیلی وجود ندارد که بخواهیم x پس از ایجاد متغیر y نامعتبر شود. به عبارت دیگر، در اینجا تفاوتی بین کپی عمیق و کپی سطحی وجود ندارد، بنابراین فراخوانی clone کاری متفاوت از کپی سطحی معمول انجام نمیدهد و میتوانیم آن را حذف کنیم.
Rust دارای یک نشانهگذاری ویژه به نام ویژگی Copy است که میتوانیم روی انواعی که روی استک ذخیره میشوند (مانند اعداد صحیح) اعمال کنیم (ما در فصل ۱۰ بیشتر درباره ویژگیها صحبت خواهیم کرد). اگر یک نوع ویژگی Copy را پیادهسازی کند، متغیرهایی که از آن استفاده میکنند جابهجا نمیشوند، بلکه به سادگی کپی میشوند و پس از اختصاص به متغیر دیگری همچنان معتبر باقی میمانند.
Rust به ما اجازه نمیدهد یک نوع را با Copy نشانهگذاری کنیم اگر نوع یا هر یک از اجزای آن ویژگی Drop را پیادهسازی کرده باشند. اگر نوع به چیزی خاص نیاز داشته باشد تا زمانی که مقدار از دامنه خارج شود و ما ویژگی Copy را به آن نوع اضافه کنیم، یک خطای زمان کامپایل دریافت خواهیم کرد. برای یادگیری نحوه افزودن ویژگی Copy به نوع خود برای پیادهسازی این ویژگی، به “ویژگیهای قابل اشتقاق” در ضمیمه ج مراجعه کنید.
پس، چه نوعهایی ویژگی Copy را پیادهسازی میکنند؟ میتوانید برای اطمینان، مستندات نوع داده شده را بررسی کنید، اما به عنوان یک قانون کلی، هر گروه از مقادیر ساده و اسکالر میتوانند ویژگی Copy را پیادهسازی کنند و هیچ چیزی که نیاز به تخصیص یا نوعی منبع داشته باشد نمیتواند ویژگی Copy را پیادهسازی کند. در اینجا تعدادی از انواعی که ویژگی Copy را پیادهسازی میکنند آورده شده است:
- تمام انواع اعداد صحیح، مانند
u32. - نوع بولی،
bool، با مقادیرtrueوfalse. - تمام انواع اعشاری، مانند
f64. - نوع کاراکتر،
char. - تاپلها، اگر تنها شامل انواعی باشند که ویژگی
Copyرا نیز پیادهسازی میکنند. برای مثال،(i32, i32)ویژگیCopyرا پیادهسازی میکند، اما(i32, String)این کار را نمیکند.
مالکیت و توابع
مکانیزمهای انتقال یک مقدار به یک تابع مشابه زمانی است که مقداری را به یک متغیر اختصاص میدهیم. انتقال یک متغیر به یک تابع به همان صورت که تخصیص انجام میشود، جابهجا یا کپی میشود. لیستینگ ۴-۳ مثالی با برخی حاشیهنویسیها دارد که نشان میدهد متغیرها کجا وارد و از دامنه خارج میشوند.
fn main() { let s = String::from("hello"); // s comes into scope takes_ownership(s); // s's value moves into the function... // ... and so is no longer valid here let x = 5; // x comes into scope makes_copy(x); // Because i32 implements the Copy trait, // x does NOT move into the function, // so it's okay to use x afterward. } // Here, x goes out of scope, then s. However, because s's value was moved, // nothing special happens. fn takes_ownership(some_string: String) { // some_string comes into scope println!("{some_string}"); } // Here, some_string goes out of scope and `drop` is called. The backing // memory is freed. fn makes_copy(some_integer: i32) { // some_integer comes into scope println!("{some_integer}"); } // Here, some_integer goes out of scope. Nothing special happens.
اگر بخواهیم از s پس از فراخوانی به takes_ownership استفاده کنیم، Rust یک خطای زمان کامپایل صادر میکند. این بررسیهای استاتیک ما را از اشتباهات محافظت میکنند. سعی کنید کدی به main اضافه کنید که از s و x استفاده کند تا ببینید کجا میتوانید از آنها استفاده کنید و کجا قوانین مالکیت مانع شما میشوند.
مقادیر بازگشتی و دامنه
بازگرداندن مقادیر نیز میتواند مالکیت را منتقل کند. لیستینگ ۴-۴ مثالی از یک تابع که مقداری را بازمیگرداند نشان میدهد، با حاشیهنویسیهایی مشابه آنچه در لیستینگ ۴-۳ وجود داشت.
fn main() { let s1 = gives_ownership(); // gives_ownership moves its return // value into s1 let s2 = String::from("hello"); // s2 comes into scope let s3 = takes_and_gives_back(s2); // s2 is moved into // takes_and_gives_back, which also // moves its return value into s3 } // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing // happens. s1 goes out of scope and is dropped. fn gives_ownership() -> String { // gives_ownership will move its // return value into the function // that calls it let some_string = String::from("yours"); // some_string comes into scope some_string // some_string is returned and // moves out to the calling // function } // This function takes a String and returns a String. fn takes_and_gives_back(a_string: String) -> String { // a_string comes into // scope a_string // a_string is returned and moves out to the calling function }
مالکیت یک متغیر همیشه از یک الگوی یکسان پیروی میکند: تخصیص یک مقدار به متغیر دیگر آن را جابهجا میکند. زمانی که یک متغیر شامل دادههایی در هیپ از دامنه خارج میشود، مقدار با استفاده از drop پاکسازی میشود مگر اینکه مالکیت دادهها به متغیر دیگری منتقل شده باشد.
در حالی که این روش کار میکند، گرفتن مالکیت و سپس بازگرداندن آن با هر تابع کمی خستهکننده است. اگر بخواهیم اجازه دهیم یک تابع از یک مقدار استفاده کند اما مالکیت آن را نگیرد، چه میشود؟ این که هر چیزی که به تابع ارسال میکنیم باید بازگردانده شود تا بتوانیم دوباره از آن استفاده کنیم، علاوه بر هر دادهای که از بدنه تابع ممکن است بخواهیم بازگردانیم، کمی آزاردهنده است.
Rust به ما اجازه میدهد مقادیر متعددی را با استفاده از یک tuple بازگردانیم، همانطور که در لیستینگ ۴-۵ نشان داده شده است.
fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{s2}' is {len}."); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // len() returns the length of a String (s, length) }
اما این کار بسیار رسمی و زمانبر است برای مفهومی که باید رایج باشد. خوشبختانه، Rust ویژگیای برای استفاده از یک مقدار بدون انتقال مالکیت دارد که ارجاعات نامیده میشود.
ارجاعات و قرض گرفتن (References and Borrowing)
مشکل کدی که در لیستینگ 4-5 با استفاده از تاپل وجود دارد این است که باید
String را به تابع فراخوانیکننده بازگردانیم تا بعد از فراخوانی
calculate_length بتوانیم همچنان از
String استفاده کنیم، زیرا
String به
calculate_length منتقل شده است. در عوض، میتوانیم یک ارجاع به مقدار
String ارائه دهیم. یک ارجاع مشابه یک اشارهگر (Pointer) است، به این معنا که یک آدرس است که میتوانیم از آن پیروی کنیم تا به دادههایی که در آن آدرس ذخیره شدهاند دسترسی پیدا کنیم؛ این دادهها متعلق به متغیر دیگری هستند. برخلاف اشارهگر (Pointer)، یک ارجاع تضمین میکند که به یک مقدار معتبر از نوع خاصی در طول عمر آن ارجاع اشاره میکند.
در اینجا نحوه تعریف و استفاده از یک تابع
calculate_length آورده شده است که به جای گرفتن مالکیت مقدار، یک ارجاع به یک شی به عنوان پارامتر دارد:
Filename: src/main.rs
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { s.len() }
اول، توجه کنید که تمام کد مربوط به تاپل در اعلام متغیر و مقدار بازگشتی تابع حذف شده است. دوم، دقت کنید که ما
&s1 را به
calculate_length میدهیم و در تعریف آن،
&String میگیریم به جای
String. این علامتهای & نمایندهی ارجاعات هستند و به شما اجازه میدهند تا به مقداری اشاره کنید بدون اینکه مالکیت آن را بگیرید. شکل 4-6 این مفهوم را نشان میدهد.

شکل 4-6: نمودار &String s که به String s1 اشاره میکند
توجه: متضاد ارجاع دادن با استفاده از
&، عدم ارجاع است که با عملگر عدم ارجاع، یعنی*، انجام میشود. برخی از موارد استفاده از عملگر عدم ارجاع را در فصل 8 خواهیم دید و جزئیات مربوط به عدم ارجاع را در فصل 15 بحث خواهیم کرد.
بیایید نگاهی دقیقتر به فراخوانی تابع بیندازیم:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { s.len() }
سینتکس &s1 به ما اجازه میدهد یک ارجاع ایجاد کنیم که به مقدار
s1 اشاره میکند اما مالک آن نیست. از آنجایی که ارجاع مالک آن نیست، مقداری که به آن اشاره میکند زمانی که ارجاع استفاده نمیشود حذف نخواهد شد.
به همین ترتیب، امضای تابع از & استفاده میکند تا نشان دهد که نوع پارامتر s یک ارجاع است. بیایید برخی توضیحات اضافه کنیم:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{s1}' is {len}."); } fn calculate_length(s: &String) -> usize { // s is a reference to a String s.len() } // Here, s goes out of scope. But because s does not have ownership of what // it refers to, the String is not dropped.
دامنهای که متغیر s در آن معتبر است، مشابه دامنهی هر پارامتر تابع است، اما مقدار اشارهشده توسط ارجاع زمانی که s استفاده نمیشود حذف نمیشود، زیرا s مالکیت ندارد. وقتی توابع ارجاعات را به جای مقادیر واقعی به عنوان پارامتر دارند، نیازی نخواهیم داشت مقادیر را بازگردانیم تا مالکیت را بازگردانیم، زیرا هرگز مالکیتی نداشتهایم.
ما عمل ایجاد یک ارجاع را قرض گرفتن مینامیم. همانند زندگی واقعی، اگر شخصی چیزی را مالک باشد، شما میتوانید آن را از او قرض بگیرید. وقتی کارتان تمام شد، باید آن را بازگردانید. شما مالک آن نیستید.
پس چه اتفاقی میافتد اگر بخواهیم چیزی که قرض گرفتهایم را تغییر دهیم؟ کد موجود در لیستینگ 4-6 را امتحان کنید. هشدار: این کار نمیکند!
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}در اینجا خطا آورده شده است:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
همانطور که متغیرها به صورت پیشفرض غیرقابل تغییر هستند، ارجاعات نیز به همین صورت هستند. ما اجازه نداریم چیزی که به آن ارجاع داریم را تغییر دهیم.
ارجاعات متغیر
ما میتوانیم کد موجود در لیستینگ 4-6 را طوری اصلاح کنیم که به ما اجازه دهد یک مقدار قرض گرفته شده را تغییر دهیم، با چند تغییر کوچک که به جای آن از ارجاع متغیر استفاده کنیم:
fn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); }
ابتدا s را به mut تغییر میدهیم. سپس یک ارجاع متغیر با &mut s ایجاد میکنیم، جایی که تابع change را فراخوانی میکنیم، و امضای تابع را بهروزرسانی میکنیم تا یک ارجاع متغیر با some_string: &mut String بپذیرد. این بسیار واضح میکند که تابع change مقدار قرض گرفته شده را تغییر خواهد داد.
ارجاعات متغیر یک محدودیت بزرگ دارند: اگر یک ارجاع متغیر به یک مقدار داشته باشید، نمیتوانید هیچ ارجاع دیگری به آن مقدار داشته باشید. این کد که تلاش میکند دو ارجاع متغیر به s ایجاد کند، ناموفق خواهد بود:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}در اینجا خطا آورده شده است:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| ---- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
این خطا میگوید که این کد نامعتبر است زیرا نمیتوانیم s را به طور همزمان بیش از یک بار به صورت متغیر قرض بگیریم. اولین قرض متغیر در r1 است و باید تا زمانی که در println! استفاده شود باقی بماند، اما بین ایجاد آن ارجاع متغیر و استفاده از آن، ما سعی کردیم یک ارجاع متغیر دیگر در r2 ایجاد کنیم که همان دادهای را قرض میگیرد که r1 نیز قرض گرفته است.
محدودیتی که از ایجاد چند ارجاع متغیر به دادههای یکسان به طور همزمان جلوگیری میکند، امکان تغییر دادهها را فراهم میکند اما به صورت بسیار کنترل شده. این چیزی است که تازهکاران زبان Rust ممکن است با آن مشکل داشته باشند زیرا اکثر زبانها به شما اجازه میدهند هر زمان که بخواهید دادهها را تغییر دهید. مزیت این محدودیت این است که Rust میتواند از مسابقات داده (data race) در زمان کامپایل جلوگیری کند. یک مسابقه داده مشابه یک شرایط مسابقه (race condition) است و زمانی رخ میدهد که این سه رفتار اتفاق بیفتند:
- دو یا چند اشارهگر (Pointer) به طور همزمان به دادههای یکسان دسترسی پیدا میکنند.
- حداقل یکی از اشارهگر (Pointer)ها برای نوشتن در دادهها استفاده میشود.
- هیچ مکانیزمی برای هماهنگ کردن دسترسی به دادهها استفاده نمیشود.
مسابقات داده باعث رفتار نامشخص میشوند و در زمان اجرای برنامه ممکن است یافتن و رفع آنها دشوار باشد؛ Rust با عدم کامپایل کدهای دارای مسابقات داده از این مشکل جلوگیری میکند!
همانطور که همیشه، میتوانیم از آکولادها برای ایجاد یک اسکوپ جدید استفاده کنیم که امکان وجود ارجاعات متغیر متعدد را فراهم میکند، اما نه به صورت همزمان:
fn main() { let mut s = String::from("hello"); { let r1 = &mut s; } // r1 goes out of scope here, so we can make a new reference with no problems. let r2 = &mut s; }
Rust یک قانون مشابه برای ترکیب ارجاعات متغیر و غیرمتغیر اعمال میکند. این کد منجر به خطا میشود:
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{r1}, {r2}, and {r3}");
}در اینجا خطا آورده شده است:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, and {r3}");
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
ای وای! ما همچنین نمیتوانیم یک ارجاع متغیر داشته باشیم در حالی که یک ارجاع غیرمتغیر به همان مقدار داریم.
کاربرانی که از یک ارجاع غیرمتغیر استفاده میکنند، انتظار ندارند که مقدار به طور ناگهانی تغییر کند! با این حال، چندین ارجاع غیرمتغیر مجاز هستند زیرا هیچکسی که فقط دادهها را میخواند، نمیتواند خواندن دیگران را تحت تأثیر قرار دهد.
توجه داشته باشید که اسکوپ یک ارجاع از جایی که معرفی میشود شروع شده و تا آخرین باری که از آن استفاده میشود ادامه دارد. به عنوان مثال، این کد کامپایل میشود زیرا آخرین استفاده از ارجاعات غیرمتغیر در println! است، قبل از اینکه ارجاع متغیر معرفی شود:
fn main() { let mut s = String::from("hello"); let r1 = &s; // no problem let r2 = &s; // no problem println!("{r1} and {r2}"); // Variables r1 and r2 will not be used after this point. let r3 = &mut s; // no problem println!("{r3}"); }
اسکوپهای ارجاعات غیرمتغیر r1 و r2 بعد از println! که در آنجا آخرین بار استفاده شدهاند به پایان میرسند، که این قبل از ایجاد ارجاع متغیر r3 است. این اسکوپها همپوشانی ندارند، بنابراین این کد مجاز است: کامپایلر میتواند تشخیص دهد که ارجاع دیگر در نقطهای قبل از پایان اسکوپ استفاده نمیشود.
حتی اگر خطاهای قرض گرفتن ممکن است گاهی اوقات ناامیدکننده باشند، به یاد داشته باشید که این کامپایلر Rust است که به شما نشان میدهد یک باگ بالقوه در اوایل (در زمان کامپایل به جای زمان اجرا) وجود دارد و دقیقا به شما میگوید مشکل کجاست. سپس نیازی نیست که پیگیری کنید چرا دادههای شما آن چیزی نیست که فکر میکردید.
ارجاعات آویزان
در زبانهایی که از اشارهگر (Pointer)ها استفاده میکنند، ایجاد اشتباه یک اشارهگر (Pointer) آویزان آسان است—اشارهگر (Pointer)ی که به مکانی در حافظه اشاره میکند که ممکن است به شخص دیگری داده شده باشد—با آزاد کردن مقداری حافظه در حالی که اشارهگر (Pointer) به آن حافظه را حفظ میکنید. در Rust، برعکس، کامپایلر تضمین میکند که ارجاعات هرگز ارجاعات آویزان نخواهند بود: اگر به دادههایی ارجاع دارید، کامپایلر اطمینان میدهد که دادهها قبل از ارجاع به دادهها از محدوده خارج نمیشوند.
بیایید سعی کنیم یک ارجاع آویزان ایجاد کنیم تا ببینیم چگونه Rust با یک خطای زمان کامپایل از این اتفاق جلوگیری میکند:
Filename: src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}در اینجا خطا آورده شده است:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
error[E0515]: cannot return reference to local variable `s`
--> src/main.rs:8:5
|
8 | &s
| ^^ returns a reference to data owned by the current function
Some errors have detailed explanations: E0106, E0515.
For more information about an error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 2 previous errors
این پیام خطا به ویژگیای اشاره دارد که هنوز پوشش ندادهایم: طول عمرها (lifetimes). ما طول عمرها را به طور مفصل در فصل 10 مورد بحث قرار خواهیم داد. اما، اگر بخشهای مربوط به طول عمرها را نادیده بگیرید، پیام کلید مشکل این کد را بیان میکند:
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
بیایید نگاهی دقیقتر به آنچه که در هر مرحله از کد dangle اتفاق میافتد بیندازیم:
Filename: src/main.rs
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a reference to a String
let s = String::from("hello"); // s is a new String
&s // we return a reference to the String, s
} // Here, s goes out of scope and is dropped, so its memory goes away.
// Danger!از آنجا که s داخل dangle ایجاد میشود، زمانی که کد dangle تمام میشود، s از محدوده خارج میشود و آزاد میگردد. اما ما سعی کردیم یک ارجاع به آن برگردانیم. این بدان معناست که این ارجاع به یک String نامعتبر اشاره میکند. این خوب نیست! Rust اجازه نمیدهد این کار را انجام دهیم.
راهحل در اینجا این است که به جای آن String را به طور مستقیم برگردانید:
fn main() { let string = no_dangle(); } fn no_dangle() -> String { let s = String::from("hello"); s }
این بدون هیچ مشکلی کار میکند. مالکیت به بیرون منتقل میشود و هیچ چیزی آزاد نمیشود.
قوانین ارجاعات
بیایید آنچه درباره ارجاعات بحث کردیم را مرور کنیم:
- در هر زمان مشخص، میتوانید یا یک ارجاع متغیر داشته باشید یا هر تعداد ارجاع غیرمتغیر.
- ارجاعات باید همیشه معتبر باشند.
در مرحله بعد، به نوع دیگری از ارجاع خواهیم پرداخت: بخشها (slices).
نوع Slice
Slices به شما اجازه میدهند که به یک دنبالهی متوالی از عناصر در یک مجموعه ارجاع دهید. اسلایس نوعی ارجاع است، بنابراین مالکیت ندارد.
یک مسئلهی کوچک برنامهنویسی داریم: تابعی بنویسید که یک رشته شامل کلمات جداشده با فاصله دریافت کند و اولین کلمهای را که در آن رشته پیدا میکند بازگرداند. اگر تابع فاصلهای در رشته نیابد، کل رشته یک کلمه محسوب میشود و باید کل رشته بازگردانده شود.
نکته: برای معرفی اسلایسهای رشتهای در این بخش، فرض بر این است که تنها با ASCII سروکار داریم؛ بحث جامعتر دربارهی مدیریت UTF-8 در بخش «ذخیره متن کدگذاریشده UTF-8 با رشتهها» در فصل ۸ ارائه شده است.
بیایید بررسی کنیم چگونه امضای این تابع را بدون استفاده از اسلایسها مینویسیم تا مشکلهایی که اسلایسها حل میکنند را درک کنیم:
fn first_word(s: &String) -> ?تابع first_word یک پارامتر از نوع &String دریافت میکند.
ما نیازی به مالکیت نداریم، پس این کار درست است.
(در Rust ایدئومیک، توابع معمولاً مالکیت آرگومانهای
خود را نمیگیرند مگر اینکه واقعاً لازم باشد، و دلایل
این موضوع با پیش رفتن توضیح داده خواهد شد.) اما
چه چیزی باید بازگردانیم؟ در واقع راهی برای اشاره به
بخشی از رشته نداریم. با این حال، میتوانیم اندیس
پایان کلمه را که با یک فاصله مشخص میشود، بازگردانیم.
بیایید این روش را امتحان کنیم، همانطور که در فهرست 4-7
نشان داده شده است.
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() {}
first_word که یک مقدار شاخص بایت در String پارامتر را برمیگرداندزیرا ما نیاز داریم عنصر به عنصر از String عبور کنیم و بررسی کنیم که آیا یک مقدار فاصله است یا خیر، رشته خود را به یک آرایه از بایتها با استفاده از متد as_bytes تبدیل میکنیم.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}در مرحله بعد، یک iterator روی آرایه بایتها با استفاده از متد iter ایجاد میکنیم:
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}ما در فصل 13 بیشتر درباره iterators بحث خواهیم کرد. فعلاً بدانید که iter یک متد است که هر عنصر در یک مجموعه را برمیگرداند و enumerate نتیجه iter را میپیچد و هر عنصر را به عنوان بخشی از یک tuple برمیگرداند. اولین عنصر tuple برگردانده شده از enumerate شاخص است و دومین عنصر ارجاع به عنصر است. این کار کمی راحتتر از محاسبه شاخص به صورت دستی است.
زیرا متد enumerate یک tuple برمیگرداند، میتوانیم از الگوها برای جدا کردن این tuple استفاده کنیم. ما در فصل 6 بیشتر درباره الگوها صحبت خواهیم کرد. در حلقه for، الگویی مشخص میکنیم که i برای شاخص در tuple و &item برای بایت منفرد در tuple باشد. زیرا ما یک ارجاع به عنصر از .iter().enumerate() دریافت میکنیم، از & در الگو استفاده میکنیم.
داخل حلقه for، به دنبال بایتی که نماینده فاصله باشد میگردیم با استفاده از نحوه نوشتن بایت به صورت literale. اگر یک فاصله پیدا کردیم، موقعیت را برمیگردانیم. در غیر این صورت، طول رشته را با استفاده از s.len() برمیگردانیم.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}اکنون راهی برای یافتن شاخص انتهای اولین کلمه در رشته داریم، اما مشکلی وجود دارد. ما یک usize به تنهایی برمیگردانیم، اما این تنها یک عدد معنادار در زمینه &String است. به عبارت دیگر، زیرا این مقدار از String جدا است، هیچ تضمینی وجود ندارد که در آینده همچنان معتبر باشد. برنامهای که در لیستینگ 4-8 استفاده میشود و از تابع first_word از لیستینگ 4-7 استفاده میکند را در نظر بگیرید.
fn first_word(s: &String) -> usize { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return i; } } s.len() } fn main() { let mut s = String::from("hello world"); let word = first_word(&s); // word will get the value 5 s.clear(); // this empties the String, making it equal to "" // word still has the value 5 here, but s no longer has any content that we // could meaningfully use with the value 5, so word is now totally invalid! }
first_word و سپس تغییر محتوای Stringاین برنامه بدون هیچ خطایی کامپایل میشود و حتی اگر word را بعد از فراخوانی s.clear() استفاده کنیم، همچنان درست کار خواهد کرد. زیرا word اصلاً به حالت s متصل نیست، word همچنان مقدار 5 را دارد. ما میتوانیم از مقدار 5 همراه با متغیر s استفاده کنیم تا تلاش کنیم اولین کلمه را استخراج کنیم، اما این یک باگ خواهد بود زیرا محتوای s از زمانی که 5 را در word ذخیره کردیم، تغییر کرده است.
نگران هماهنگ نگه داشتن شاخص در word با دادههای موجود در s بودن، خستهکننده و مستعد خطاست! مدیریت این شاخصها حتی شکنندهتر میشود اگر بخواهیم یک تابع second_word بنویسیم. امضای آن باید به این صورت باشد:
fn second_word(s: &String) -> (usize, usize) {حالا ما یک شاخص شروع و یک شاخص پایان را دنبال میکنیم و مقادیر بیشتری داریم که از دادهها در یک وضعیت خاص محاسبه شدهاند اما اصلاً به آن وضعیت مرتبط نیستند. ما سه متغیر نامرتبط داریم که باید همگام نگه داشته شوند.
خوشبختانه، Rust یک راهحل برای این مشکل دارد: برشهای رشتهای.
برشهای رشتهای
string slice یک ارجاع به دنبالهای متوالی از عناصر
یک String است و به این صورت نمایش داده میشود:
fn main() { let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11]; }
بهجای یک رفرنس به کل String، مقدار hello یک رفرنس به بخشی از String است
که در بخش اضافی [0..5] مشخص شده است.
برای ساختن slice، از یک بازه در داخل براکتها استفاده میکنیم
و آن را به صورت [starting_index..ending_index] مینویسیم؛
که در آن، starting_index اولین موقعیت در slice است
و ending_index یکی بیشتر از آخرین موقعیت در slice است.
درونیسازی ساختار دادهی slice، موقعیت شروع و طول slice را ذخیره میکند
که این طول برابر است با ending_index منهای starting_index.
پس در مورد دستور let world = &s[6..11];، متغیر world یک slice خواهد بود
که اشارهگری به بایت در اندیس ۶ از s دارد، به همراه یک مقدار طول برابر با 5.
شکل 4-7 این موضوع را در یک نمودار نشان میدهد.

شکل 4-7: برش رشتهای اشاره به بخشی از یک String
با استفاده از نحوی محدوده .. در Rust، اگر میخواهید از شاخص 0 شروع کنید، میتوانید مقدار قبل از دو نقطه را حذف کنید. به عبارت دیگر، این دو معادل هستند:
#![allow(unused)] fn main() { let s = String::from("hello"); let slice = &s[0..2]; let slice = &s[..2]; }
به همین ترتیب، اگر برش شما شامل آخرین بایت String باشد، میتوانید عدد پایانی را حذف کنید. این به این معناست که این دو معادل هستند:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[3..len]; let slice = &s[3..]; }
شما همچنین میتوانید هر دو مقدار را حذف کنید تا یک برش از کل رشته بگیرید. بنابراین این دو معادل هستند:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..]; }
توجه: اندیسهای بازهی slice برای
Stringباید در مرزهای معتبر کاراکترهای UTF-8 قرار داشته باشند. اگر سعی کنید یک slice از رشته را در میانهی یک کاراکتر چندبایتی ایجاد کنید، برنامهی شما با خطا متوقف خواهد شد.
با در نظر گرفتن این اطلاعات، بیایید first_word را بازنویسی کنیم تا یک برش برگرداند. نوعی که نشاندهنده “برش رشتهای” است به صورت &str نوشته میشود:
fn first_word(s: &String) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() {}
ما شاخص پایان کلمه را به همان روشی که در لیستینگ 4-7 انجام دادیم، پیدا میکنیم، یعنی با جستجوی اولین فضای خالی. وقتی یک فضای خالی پیدا میکنیم، یک برش رشتهای با استفاده از شروع رشته و شاخص فضای خالی بهعنوان شاخصهای شروع و پایان برمیگردانیم.
اکنون وقتی first_word را فراخوانی میکنیم، یک مقدار واحد دریافت میکنیم که به دادههای پایه متصل است. این مقدار شامل یک ارجاع به نقطه شروع برش و تعداد عناصر موجود در برش است.
بازگرداندن یک برش برای یک تابع second_word نیز کار میکند:
fn second_word(s: &String) -> &str {اکنون یک API ساده داریم که بسیار سختتر است اشتباه شود زیرا کامپایلر اطمینان حاصل میکند که ارجاعها به داخل String معتبر باقی میمانند. به یاد دارید خطای منطقی برنامه در لیستینگ 4-8، وقتی شاخص انتهای اولین کلمه را به دست آوردیم اما سپس رشته را پاک کردیم، بنابراین شاخص ما نامعتبر شد؟ آن کد منطقی نادرست بود اما هیچ خطای فوری نشان نمیداد. مشکلات بعداً وقتی تلاش میکردیم از شاخص اولین کلمه با یک رشته خالی استفاده کنیم، ظاهر میشد. برشها این خطا را غیرممکن میکنند و به ما اطلاع میدهند که مشکلی در کد ما وجود دارد خیلی زودتر. استفاده از نسخه برش first_word یک خطای زمان کامپایل ایجاد میکند:
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {word}");
}این هم خطای کامپایلر:
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ------ immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
به یاد بیاورید از قوانین وام گرفتن که اگر ما یک ارجاع غیرقابل تغییر به چیزی داشته باشیم، نمیتوانیم یک ارجاع قابل تغییر نیز بگیریم. از آنجایی که clear نیاز دارد که String را کوتاه کند، نیاز دارد یک ارجاع قابل تغییر بگیرد. println! بعد از فراخوانی به clear از ارجاع در word استفاده میکند، بنابراین ارجاع غیرقابل تغییر باید هنوز در آن نقطه فعال باشد. Rust ارجاع قابل تغییر در clear و ارجاع غیرقابل تغییر در word را از همزمان وجود داشتن ممنوع میکند و کامپایل شکست میخورد. نه تنها Rust API ما را آسانتر کرده، بلکه یک دسته کامل از خطاها را در زمان کامپایل حذف کرده است!
رشتههای متنی به عنوان برش
به یاد بیاورید که ما درباره ذخیره رشتههای متنی در داخل باینری صحبت کردیم. اکنون که درباره برشها میدانیم، میتوانیم رشتههای متنی را به درستی درک کنیم:
#![allow(unused)] fn main() { let s = "Hello, world!"; }
نوع s در اینجا &str است: این یک برش است که به یک نقطه خاص از باینری اشاره میکند. این همچنین دلیل غیرقابل تغییر بودن رشتههای متنی است؛ &str یک ارجاع غیرقابل تغییر است.
برشهای رشتهای به عنوان پارامترها
دانستن اینکه میتوانید برشهایی از رشتههای متنی و مقادیر String بگیرید ما را به یک بهبود دیگر در first_word میرساند، و آن امضای آن است:
fn first_word(s: &String) -> &str {یک برنامهنویس باتجربهتر Rust امضای نشان داده شده در لیستینگ 4-9 را مینویسد زیرا این اجازه را میدهد که از همان تابع برای مقادیر &String و &str استفاده کنیم.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on references to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}first_word با استفاده از برش رشتهای برای نوع پارامتر sاگر ما یک برش رشتهای داشته باشیم، میتوانیم آن را مستقیماً ارسال کنیم. اگر یک String داشته باشیم، میتوانیم یک برش از String یا یک ارجاع به String ارسال کنیم. این انعطافپذیری از ویژگی دریف کوئرسین استفاده میکند، که در بخش “Implicit Deref Coercions with Functions and Methods” در فصل 15 به آن خواهیم پرداخت.
تعریف یک تابع برای گرفتن یک برش رشتهای به جای یک ارجاع به String، API ما را عمومیتر و مفیدتر میکند بدون اینکه هیچ کاربردی از دست برود:
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // `first_word` works on slices of `String`s, whether partial or whole. let word = first_word(&my_string[0..6]); let word = first_word(&my_string[..]); // `first_word` also works on references to `String`s, which are equivalent // to whole slices of `String`s. let word = first_word(&my_string); let my_string_literal = "hello world"; // `first_word` works on slices of string literals, whether partial or // whole. let word = first_word(&my_string_literal[0..6]); let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
برشهای دیگر
برشهای رشتهای، همانطور که تصور میکنید، مختص رشتهها هستند. اما یک نوع برش عمومیتر نیز وجود دارد. این آرایه را در نظر بگیرید:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; }
همانطور که ممکن است بخواهیم به بخشی از یک رشته ارجاع دهیم، ممکن است بخواهیم به بخشی از یک آرایه نیز ارجاع دهیم. این کار را میتوانیم به این شکل انجام دهیم:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
این برش دارای نوع &[i32] است. این دقیقاً همانطور که برشهای رشتهای کار میکنند، با ذخیره یک ارجاع به اولین عنصر و یک طول عمل میکند. شما از این نوع برش برای انواع دیگر مجموعهها نیز استفاده خواهید کرد. ما این مجموعهها را به تفصیل وقتی درباره وکتورها در فصل 8 صحبت کنیم، بررسی خواهیم کرد.
خلاصه
مفاهیم مالکیت، وام گرفتن، و برشها، ایمنی حافظه را در برنامههای Rust در زمان کامپایل تضمین میکنند. زبان Rust به شما همان کنترلی بر استفاده از حافظه میدهد که سایر زبانهای برنامهنویسی سیستم ارائه میدهند، اما این واقعیت که مالک داده به طور خودکار آن داده را هنگامی که مالک از حوزه خارج میشود، پاکسازی میکند، به این معنی است که نیازی به نوشتن و اشکالزدایی کد اضافی برای دستیابی به این کنترل ندارید.
مالکیت بر نحوه عملکرد بسیاری از بخشهای دیگر Rust تأثیر میگذارد، بنابراین در طول بقیه کتاب این مفاهیم را بیشتر بررسی خواهیم کرد. بیایید به فصل 5 برویم و نگاهی به گروهبندی قطعات داده در یک struct بیندازیم.
استفاده از Structها برای سازماندهی دادههای مرتبط
یک struct یا ساختار، نوع دادهای سفارشی است که به شما اجازه میدهد چندین مقدار مرتبط را به صورت گروهی در کنار هم بستهبندی و نامگذاری کنید. اگر با یک زبان برنامهنویسی شیءگرا آشنا باشید، یک struct شبیه به ویژگیهای دادهای یک شیء است. در این فصل، ما ساختارها را با تاپلها مقایسه و مقایسه خواهیم کرد تا نشان دهیم چه زمانی ساختارها روش بهتری برای گروهبندی دادهها هستند.
ما نحوه تعریف و نمونهسازی ساختارها را نشان خواهیم داد. همچنین بحث خواهیم کرد که چگونه توابع مرتبط، بهویژه نوعی از توابع مرتبط به نام متدها را تعریف کنیم تا رفتار مرتبط با یک نوع ساختار را مشخص کنیم. ساختارها و Enumها (که در فصل ۶ مورد بحث قرار گرفتهاند) بلوکهای سازندهای برای ایجاد انواع جدید در حوزه برنامه شما هستند که از بررسی نوع در زمان کامپایل در Rust به طور کامل استفاده میکنند.
تعریف و نمونهسازی Structها
ساختارها مشابه تاپلها هستند که در بخش «نوع Tuple» مورد بحث قرار گرفتند، به این معنا که هر دو شامل مقادیر مرتبط متعددی هستند. مانند تاپلها، اجزای یک ساختار میتوانند از انواع مختلفی باشند. اما برخلاف تاپلها، در یک ساختار شما برای هر جزء داده نام تعیین میکنید تا معنای مقادیر روشنتر شود. افزودن این نامها باعث میشود که ساختارها از تاپلها انعطافپذیرتر باشند: شما مجبور نیستید برای مشخص کردن یا دسترسی به مقادیر یک نمونه به ترتیب دادهها تکیه کنید.
برای تعریف یک ساختار، کلمه کلیدی struct را وارد کرده و نام کل ساختار را تعیین میکنیم. نام یک ساختار باید توصیفکننده اهمیت اجزای دادهای باشد که با هم گروهبندی میشوند. سپس، داخل آکولادها، نامها و انواع اجزای دادهای را که به آنها فیلد میگوییم، تعریف میکنیم. برای مثال، لیست ۵-۱ یک ساختار را نشان میدهد که اطلاعات مربوط به یک حساب کاربری را ذخیره میکند.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() {}
Userبرای استفاده از یک struct پس از تعریف آن، باید یک instance از آن ایجاد کنیم
با مشخص کردن مقادیر مشخص برای هر یک از فیلدها.
برای ساختن یک instance، نام struct را مینویسیم
و سپس داخل کروشهها جفتهای کلید: مقدار قرار میدهیم؛
که در آنها، کلیدها نام فیلدها هستند و مقادیر، دادههایی هستند که میخواهیم در آن فیلدها ذخیره کنیم.
لازم نیست فیلدها را به همان ترتیبی بنویسیم که در تعریف struct آمدهاند.
به عبارت دیگر، تعریف struct مانند یک الگوی کلی برای نوع داده است
و instanceها آن الگو را با دادههای مشخص پر میکنند تا مقادیر آن نوع را بسازند.
برای نمونه، میتوانیم یک کاربر خاص را همانطور که در لیست ۵-۲ نشان داده شده تعریف کنیم.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let user1 = User { active: true, username: String::from("someusername123"), email: String::from("[email protected]"), sign_in_count: 1, }; }
Userبرای بهدستآوردن مقدار خاصی از یک ساختار، از نشانهگذاری نقطه استفاده میکنیم. به عنوان مثال، برای دسترسی به آدرس ایمیل این کاربر، از user1.email استفاده میکنیم. اگر نمونه قابل تغییر باشد، میتوانیم مقدار را با استفاده از نشانهگذاری نقطه تغییر داده و در یک فیلد خاص مقداردهی کنیم. لیست ۵-۳ نشان میدهد که چگونه مقدار در فیلد email یک نمونه قابل تغییر User را تغییر دهیم.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let mut user1 = User { active: true, username: String::from("someusername123"), email: String::from("[email protected]"), sign_in_count: 1, }; user1.email = String::from("[email protected]"); }
email یک نمونه Userتوجه داشته باشید که کل نمونه باید قابل تغییر باشد؛ Rust به ما اجازه نمیدهد که فقط برخی از فیلدها را به صورت قابل تغییر علامتگذاری کنیم. مانند هر عبارت دیگری، میتوانیم یک نمونه جدید از ساختار را به عنوان آخرین عبارت در بدنه یک تابع بسازیم تا به طور ضمنی آن نمونه جدید را بازگردانیم.
لیست ۵-۴ یک تابع build_user را نشان میدهد که یک نمونه از User را با ایمیل و نام کاربری مشخص برمیگرداند. فیلد active مقدار true میگیرد و sign_in_count مقدار 1 دریافت میکند.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username: username, email: email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("[email protected]"), String::from("someusername123"), ); }
build_user که یک ایمیل و نام کاربری میگیرد و یک نمونه User را بازمیگرداندنوشتن نام پارامترهای تابع با همان نام فیلدهای ساختار منطقی است، اما تکرار نامهای email و username برای هر دو فیلد و متغیرها کمی خستهکننده است. اگر ساختار فیلدهای بیشتری داشت، تکرار هر نام حتی آزاردهندهتر میشد. خوشبختانه، یک راه میانبر راحت وجود دارد!
استفاده از میانبر مقداردهی فیلد
از آنجا که نام پارامترها و نام فیلدهای ساختار دقیقاً یکسان هستند، میتوانیم از نحو میانبر مقداردهی فیلد برای بازنویسی build_user استفاده کنیم تا همان رفتار را داشته باشد اما تکرار username و email را نداشته باشد، همانطور که در لیست ۵-۵ نشان داده شده است.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn build_user(email: String, username: String) -> User { User { active: true, username, email, sign_in_count: 1, } } fn main() { let user1 = build_user( String::from("[email protected]"), String::from("someusername123"), ); }
build_user که از میانبر مقداردهی فیلد استفاده میکند زیرا پارامترهای username و email همان نام فیلدهای ساختار را دارنداینجا، ما یک نمونه جدید از ساختار User میسازیم که فیلدی به نام email دارد. ما میخواهیم مقدار فیلد email را به مقداری که در پارامتر email تابع build_user وجود دارد تنظیم کنیم. از آنجا که فیلد email و پارامتر email نام یکسانی دارند، فقط نیاز داریم email بنویسیم، نه email: email.
ایجاد نمونهها از نمونههای دیگر با استفاده از نحو بهروزرسانی Struct
اغلب مفید است که یک instance جدید از یک struct ایجاد کنیم
که بیشتر مقادیر آن از یک instance دیگر با همان نوع گرفته شده باشد،
اما برخی از مقادیر آن تغییر کرده باشند.
برای انجام این کار میتوانید از syntax بهروزرسانی struct استفاده کنید.
ابتدا، در لیست ۵-۶ نشان داده شده است که چگونه میتوان یک نمونه جدید User در user2 ایجاد کرد، بدون استفاده از نحو بهروزرسانی. ما یک مقدار جدید برای email تنظیم میکنیم اما در غیر این صورت از همان مقادیر در user1 که قبلاً در لیست ۵-۲ ایجاد شده است، استفاده میکنیم.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("[email protected]"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { active: user1.active, username: user1.username, email: String::from("[email protected]"), sign_in_count: user1.sign_in_count, }; }
User با استفاده از تمام مقادیر به جز یکی از user1با استفاده از نحو بهروزرسانی Struct، میتوانیم همان نتیجه را با کد کمتری به دست آوریم، همانطور که در لیست ۵-۷ نشان داده شده است. نحو .. مشخص میکند که فیلدهای باقیماندهای که به صورت صریح تنظیم نشدهاند باید همان مقادیری را داشته باشند که در نمونه داده شده هستند.
struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { // --snip-- let user1 = User { email: String::from("[email protected]"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { email: String::from("[email protected]"), ..user1 }; }
email برای یک نمونه User اما استفاده از مقادیر باقیمانده از user1کد در لیست ۵-۷ همچنین نمونهای در user2 ایجاد میکند که مقدار متفاوتی برای email دارد اما دارای مقادیر مشابهی برای فیلدهای username، active و sign_in_count از user1 است. ..user1 باید در انتها بیاید تا مشخص کند که فیلدهای باقیمانده باید مقادیر خود را از فیلدهای مربوطه در user1 دریافت کنند، اما میتوانیم مقادیر را برای هر تعداد فیلدی که میخواهیم به هر ترتیبی مشخص کنیم، بدون توجه به ترتیب فیلدها در تعریف ساختار.
توجه داشته باشید که نحو بهروزرسانی struct از = مانند عمل انتساب استفاده میکند؛
زیرا داده را منتقل میکند، همانطور که در بخش «تعامل متغیرها و دادهها با Move» دیدیم.
در این مثال، پس از ایجاد user2 دیگر نمیتوانیم از user1 استفاده کنیم
چون String موجود در فیلد username از user1 به user2 منتقل شده است.
اگر برای user2 مقادیر جدیدی از نوع String برای هر دو فیلد email و username مشخص کرده بودیم
و تنها از مقادیر active و sign_in_count از user1 استفاده کرده بودیم،
آنگاه user1 پس از ساختن user2 همچنان معتبر باقی میماند.
زیرا active و sign_in_count از نوعهایی هستند که Copy trait را پیادهسازی میکنند،
و بنابراین رفتاری که در بخش «دادههای فقط-پشته: Copy» توضیح دادیم، اعمال میشود.
در این مثال، همچنان میتوانیم از user1.email استفاده کنیم،
چون مقدار آن از user1 خارج نشده است.
استفاده از ساختارهای Tuple بدون فیلدهای نامگذاریشده برای ایجاد انواع مختلف
Rust همچنین از ساختارهایی که شبیه تاپلها هستند پشتیبانی میکند که به آنها ساختارهای Tuple میگویند. ساختارهای Tuple به دلیل نام ساختار معنای بیشتری دارند اما نامهایی برای فیلدهای خود ندارند؛ بلکه فقط نوع فیلدها را دارند. ساختارهای Tuple زمانی مفید هستند که بخواهید به کل تاپل یک نام بدهید و آن را به عنوان نوعی متفاوت از تاپلهای دیگر مشخص کنید، و وقتی نامگذاری هر فیلد مانند یک ساختار معمولی طولانی یا زائد باشد.
برای تعریف یک ساختار Tuple، با کلمه کلیدی struct و نام ساختار شروع کنید و سپس نوعهای موجود در تاپل را مشخص کنید. به عنوان مثال، در اینجا ما دو ساختار Tuple به نامهای Color و Point تعریف و استفاده کردهایم:
struct Color(i32, i32, i32); struct Point(i32, i32, i32); fn main() { let black = Color(0, 0, 0); let origin = Point(0, 0, 0); }
توجه داشته باشید که مقادیر black و origin از انواع متفاوتی هستند
چون آنها instanceهای دو tuple struct مختلفاند.
هر structای که تعریف میکنید، نوع خاص خود را دارد،
حتی اگر فیلدهای داخل آن struct نوعهای یکسانی داشته باشند.
برای مثال، یک تابع که پارامتری از نوع Color میگیرد،
نمیتواند یک Point را به عنوان آرگومان دریافت کند،
حتی اگر هر دو نوع از سه مقدار i32 تشکیل شده باشند.
به جز این مورد، tuple structها شبیه به tupleها هستند
از این جهت که میتوانید آنها را به اجزای منفردشان destructure کنید،
و با استفاده از . و اندیس، به مقدار خاصی دسترسی پیدا کنید.
برخلاف tupleها، tuple structها نیاز دارند که هنگام destructure کردن،
نام نوع struct را مشخص کنید.
برای مثال، برای destructure کردن مقادیر موجود در origin به متغیرهای x، y و z،
باید بنویسیم: let Point(x, y, z) = origin;
ساختارهای شبیه به Unit بدون هیچ فیلدی
شما همچنین میتوانید ساختارهایی تعریف کنید که هیچ فیلدی ندارند! اینها به عنوان ساختارهای شبیه Unit شناخته میشوند زیرا شبیه به نوع ()، نوع Unit، رفتار میکنند که در بخش «نوع Tuple» مورد اشاره قرار گرفت. ساختارهای شبیه Unit زمانی مفید هستند که نیاز به پیادهسازی یک ویژگی بر روی یک نوع داشته باشید اما هیچ دادهای برای ذخیره در خود نوع نداشته باشید. ما ویژگیها را در فصل ۱۰ بحث خواهیم کرد. در اینجا مثالی از اعلام و نمونهسازی یک ساختار شبیه Unit به نام AlwaysEqual آورده شده است:
struct AlwaysEqual; fn main() { let subject = AlwaysEqual; }
برای تعریف AlwaysEqual، از کلمه کلیدی struct، نام دلخواه و سپس یک نقطه ویرگول استفاده میکنیم. نیازی به آکولاد یا پرانتز نیست! سپس میتوانیم یک نمونه از AlwaysEqual را در متغیر subject با استفاده از همان نامی که تعریف کردهایم، بدون هیچ آکولاد یا پرانتزی دریافت کنیم. تصور کنید که در آینده رفتاری را برای این نوع پیادهسازی خواهیم کرد که همه نمونههای AlwaysEqual همیشه با تمام نمونههای دیگر برابر باشند، شاید برای داشتن نتیجهای مشخص برای اهداف آزمایشی. برای پیادهسازی آن رفتار نیازی به هیچ دادهای نداریم! شما در فصل ۱۰ خواهید دید که چگونه میتوانید ویژگیها را تعریف و آنها را بر روی هر نوعی، از جمله ساختارهای شبیه به Unit، پیادهسازی کنید.
مالکیت دادههای Struct
در تعریف ساختار User در لیست ۵-۱، ما از نوع مالک String به جای نوع برش رشته &str استفاده کردیم. این یک انتخاب عمدی است زیرا ما میخواهیم هر نمونه از این ساختار همه دادههای خود را مالک باشد و این دادهها به مدت زمانی که کل ساختار معتبر است، معتبر باقی بمانند.
همچنین ممکن است ساختارهایی وجود داشته باشند که به دادههای متعلق به چیز دیگری ارجاع میدهند، اما برای انجام این کار نیاز به استفاده از طول عمرها داریم، یک ویژگی از Rust که ما در فصل ۱۰ مورد بحث قرار خواهیم داد. طول عمرها اطمینان حاصل میکنند که دادههایی که توسط یک ساختار ارجاع داده شدهاند تا زمانی که ساختار معتبر است، معتبر باقی میمانند. بیایید بگوییم شما سعی دارید یک ارجاع را در یک ساختار ذخیره کنید بدون اینکه طول عمرها را مشخص کنید، مانند مثال زیر؛ این کار نخواهد کرد:
struct User {
active: bool,
username: &str,
email: &str,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: "someusername123",
email: "[email protected]",
sign_in_count: 1,
};
}کامپایلر شکایت خواهد کرد که به مشخصکنندههای طول عمر نیاز دارد:
$ cargo run
Compiling structs v0.1.0 (file:///projects/structs)
error[E0106]: missing lifetime specifier
--> src/main.rs:3:15
|
3 | username: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | active: bool,
3 ~ username: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:4:12
|
4 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | active: bool,
3 | username: &str,
4 ~ email: &'a str,
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `structs` (bin "structs") due to 2 previous errors
در فصل ۱۰، ما بحث خواهیم کرد که چگونه این خطاها را برطرف کنید تا بتوانید ارجاعها را در ساختارها ذخیره کنید، اما در حال حاضر، ما این خطاها را با استفاده از انواع مالک مانند String به جای ارجاعها مانند &str برطرف خواهیم کرد.
یک برنامه نمونه با استفاده از Structها
برای درک بهتر زمانی که ممکن است بخواهیم از ساختارها استفاده کنیم، بیایید یک برنامه بنویسیم که مساحت یک مستطیل را محاسبه کند. ما ابتدا با استفاده از متغیرهای جداگانه شروع میکنیم و سپس برنامه را بازنویسی میکنیم تا از ساختارها استفاده کند.
بیایید یک پروژه باینری جدید با Cargo به نام rectangles ایجاد کنیم که عرض و ارتفاع یک مستطیل را بر حسب پیکسل مشخص کرده و مساحت آن را محاسبه کند. لیست ۵-۸ یک برنامه کوتاه نشان میدهد که دقیقاً همین کار را در فایل src/main.rs پروژه ما انجام میدهد.
fn main() { let width1 = 30; let height1 = 50; println!( "The area of the rectangle is {} square pixels.", area(width1, height1) ); } fn area(width: u32, height: u32) -> u32 { width * height }
اکنون، این برنامه را با استفاده از دستور cargo run اجرا کنید:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
این کد با فراخوانی تابع area با هر یک از ابعاد موفق به محاسبه مساحت مستطیل میشود، اما میتوانیم این کد را خواناتر و قابل درکتر کنیم.
مشکل این کد در امضای تابع area مشخص است:
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}تابع area قرار است مساحت یک مستطیل را محاسبه کند، اما تابعی که نوشتیم دو پارامتر دارد و هیچکجا در برنامه مشخص نیست که این پارامترها به هم مرتبط هستند. بهتر است عرض و ارتفاع را به صورت گروهی تعریف کنیم تا خوانایی و مدیریت کد بهتر شود. یکی از روشهایی که قبلاً در بخش «نوع Tuple» فصل ۳ بحث کردیم این است که از تاپلها استفاده کنیم.
بازنویسی با استفاده از Tupleها
لیست ۵-۹ نسخه دیگری از برنامه ما را نشان میدهد که از تاپلها استفاده میکند.
fn main() { let rect1 = (30, 50); println!( "The area of the rectangle is {} square pixels.", area(rect1) ); } fn area(dimensions: (u32, u32)) -> u32 { dimensions.0 * dimensions.1 }
از یک منظر، این برنامه بهتر است. تاپلها کمی ساختار اضافه میکنند و اکنون ما فقط یک آرگومان ارسال میکنیم. اما از منظر دیگر، این نسخه کمتر واضح است: تاپلها اجزای خود را نامگذاری نمیکنند، بنابراین باید به بخشهای تاپل با استفاده از ایندکسها دسترسی پیدا کنیم که محاسبات ما را کمتر شفاف میکند.
اگر بخواهیم مستطیل را روی صفحه نمایش بکشیم، جابهجایی عرض و ارتفاع اهمیتی ندارد، اما برای رسم آن اهمیت پیدا میکند! ما باید به خاطر داشته باشیم که width ایندکس 0 تاپل و height ایندکس 1 تاپل است. این کار حتی برای کسی که از کد ما استفاده میکند سختتر خواهد بود و به اشتباهات بیشتری منجر میشود. چون معنای دادههای ما در کد مشخص نشده است، احتمال خطا بیشتر میشود.
بازنویسی با استفاده از Structها: افزودن معنای بیشتر
ما از ساختارها استفاده میکنیم تا با نامگذاری دادهها، معنای بیشتری به آنها بدهیم. میتوانیم تاپلی که استفاده میکنیم را به یک ساختار تبدیل کنیم که برای کل دادهها یک نام و همچنین برای بخشهای مختلف آن نامهایی مشخص کنیم، همانطور که در لیست ۵-۱۰ نشان داده شده است.
struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", area(&rect1) ); } fn area(rectangle: &Rectangle) -> u32 { rectangle.width * rectangle.height }
Rectangleدر اینجا یک struct تعریف کردهایم و نام آن را Rectangle گذاشتهایم.
درون آکولادها، فیلدهایی با نامهای width و height تعریف کردهایم
که هر دو دارای نوع u32 هستند. سپس، در تابع main، یک نمونه خاص از Rectangle ایجاد کردهایم
که width آن برابر با 30 و height آن برابر با 50 است.
تابع area ما اکنون با یک پارامتر تعریف شده است که آن را rectangle نامیدهایم و نوع آن یک ارجاع غیرقابل تغییر به یک نمونه از ساختار Rectangle است. همانطور که در فصل ۴ اشاره شد، ما میخواهیم ساختار را قرض بگیریم نه اینکه مالکیت آن را بگیریم. به این ترتیب، main مالکیت خود را حفظ میکند و میتواند همچنان از rect1 استفاده کند. به همین دلیل است که از & در امضای تابع و در جایی که تابع را فراخوانی میکنیم استفاده میکنیم.
تابع area به فیلدهای width و height در نمونه Rectangle دسترسی پیدا میکند (توجه داشته باشید که دسترسی به فیلدهای یک نمونه قرضگرفتهشده باعث انتقال مقادیر فیلدها نمیشود، به همین دلیل است که اغلب قرضگیری ساختارها را مشاهده میکنید). امضای تابع area ما اکنون دقیقاً همان چیزی را میگوید که منظور ماست: مساحت Rectangle را با استفاده از فیلدهای width و height آن محاسبه کن. این کار نشان میدهد که عرض و ارتفاع به یکدیگر مرتبط هستند و نامهای توصیفی به مقادیر میدهد، به جای استفاده از مقادیر ایندکس تاپلها مانند 0 و 1. این یک پیروزی برای شفافیت است.
افزودن قابلیتهای مفید با Traits مشتقشده
زمانی که در حال اشکالزدایی برنامه خود هستیم، مفید است که بتوانیم نمونهای از Rectangle را چاپ کرده و مقادیر تمام فیلدهای آن را ببینیم. لیست ۵-۱۱ تلاش میکند با استفاده از ماکروی println! که در فصلهای قبلی استفاده کردهایم، این کار را انجام دهد. با این حال، این کار موفق نخواهد بود.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1}");
}Rectangleوقتی این کد را کامپایل میکنیم، با خطایی مواجه میشویم که پیام اصلی آن به این صورت است:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
ماکروی println! میتواند بسیاری از انواع فرمتبندی را انجام دهد، و به صورت پیشفرض، آکولادها به println! میگویند که از فرمتبندیای که به نام Display شناخته میشود استفاده کند: خروجیای که برای مصرف مستقیم کاربر نهایی در نظر گرفته شده است. انواع ابتدایی که تاکنون دیدهایم به صورت پیشفرض ویژگی Display را پیادهسازی میکنند زیرا تنها یک روش برای نمایش یک مقدار مانند 1 یا هر نوع ابتدایی دیگری به کاربر وجود دارد. اما با ساختارها، روش فرمتبندی خروجی کمتر واضح است زیرا امکانات بیشتری برای نمایش وجود دارد: آیا میخواهید از ویرگول استفاده شود یا خیر؟ آیا میخواهید آکولادها چاپ شوند؟ آیا تمام فیلدها باید نشان داده شوند؟ به دلیل این ابهام، Rust سعی نمیکند حدس بزند که ما چه میخواهیم، و ساختارها پیادهسازیای برای Display ندارند که بتوان با println! و جایگزین {} استفاده کرد.
اگر به خواندن خطاها ادامه دهیم، به این یادداشت مفید خواهیم رسید:
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
بیایید آن را امتحان کنیم! اکنون فراخوانی ماکروی println! به صورت println!("rect1 is {rect1:?}"); خواهد بود. قرار دادن مشخصکننده :? داخل آکولادها به println! میگوید که میخواهیم از یک فرمت خروجی به نام Debug استفاده کنیم. ویژگی Debug به ما اجازه میدهد تا ساختار خود را به روشی که برای توسعهدهندگان مفید است چاپ کنیم تا مقدار آن را هنگام اشکالزدایی کد خود ببینیم.
کد را با این تغییر کامپایل کنید. خب، باز هم یک خطا دریافت میکنیم:
error[E0277]: `Rectangle` doesn't implement `Debug`
اما باز هم کامپایلر یادداشتی مفید به ما میدهد:
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
Rust در واقع قابلیت چاپ اطلاعات اشکالزدایی را دارد، اما باید به صورت صریح این قابلیت را برای ساختار خود فعال کنیم. برای انجام این کار، ویژگی بیرونی #[derive(Debug)] را دقیقاً قبل از تعریف ساختار اضافه میکنیم، همانطور که در لیست ۵-۱۲ نشان داده شده است.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!("rect1 is {rect1:?}"); }
Debug و چاپ نمونه Rectangle با استفاده از فرمت اشکالزداییاکنون وقتی برنامه را اجرا میکنیم، هیچ خطایی دریافت نخواهیم کرد و خروجی زیر را خواهیم دید:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
عالی! این خروجی ممکن است زیباترین نباشد، اما مقادیر تمام فیلدها را برای این نمونه نشان میدهد که قطعاً در هنگام اشکالزدایی کمک میکند. زمانی که ساختارهای بزرگتری داریم، مفید است که خروجی کمی آسانتر خوانده شود؛ در چنین مواردی میتوانیم به جای {:?} از {:#?} در رشته println! استفاده کنیم. در این مثال، استفاده از سبک {:#?} خروجی زیر را ایجاد خواهد کرد:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
روش دیگر برای چاپ مقدار با استفاده از فرمت Debug، استفاده از ماکروی dbg! است که مالکیت یک عبارت را میگیرد (برخلاف println!، که ارجاع میگیرد)، فایل و شماره خطی که فراخوانی dbg! در آن اتفاق میافتد همراه با مقدار حاصل از آن عبارت را چاپ میکند و مالکیت مقدار را بازمیگرداند.
Here is the continuation of the translation for “ch05-02-example-structs.md” into Persian:
در اینجا مثالی آورده شده است که در آن ما به مقدار اختصاص داده شده به فیلد width و همچنین مقدار کل ساختار در rect1 علاقهمند هستیم:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let scale = 2; let rect1 = Rectangle { width: dbg!(30 * scale), height: 50, }; dbg!(&rect1); }
ما میتوانیم dbg! را در اطراف عبارت 30 * scale قرار دهیم و چون dbg! مالکیت مقدار عبارت را بازمیگرداند، فیلد width همان مقداری را خواهد داشت که اگر فراخوانی dbg! در آنجا وجود نداشت. ما نمیخواهیم dbg! مالکیت rect1 را بگیرد، بنابراین از یک ارجاع به rect1 در فراخوانی بعدی استفاده میکنیم. در اینجا خروجی این مثال آورده شده است:
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
میتوانیم ببینیم که اولین بخش خروجی از خط ۱۰ در src/main.rs آمده است، جایی که ما در حال اشکالزدایی عبارت 30 * scale هستیم، و مقدار حاصل آن 60 است (فرمتبندی Debug که برای اعداد صحیح پیادهسازی شده است فقط مقدار آنها را چاپ میکند). فراخوانی dbg! در خط ۱۴ از src/main.rs مقدار &rect1 را چاپ میکند که ساختار Rectangle است. این خروجی از فرمتبندی زیبا و مفید Debug برای نوع Rectangle استفاده میکند. ماکروی dbg! میتواند در هنگام تلاش برای درک رفتار کدتان بسیار مفید باشد!
علاوه بر ویژگی Debug، Rust تعدادی ویژگی برای ما فراهم کرده است که میتوانیم با استفاده از ویژگی derive آنها را به نوعهای سفارشی خود اضافه کنیم و رفتار مفیدی ارائه دهند. این ویژگیها و رفتار آنها در ضمیمه ج فهرست شدهاند. ما در فصل ۱۰ به نحوه پیادهسازی این ویژگیها با رفتار سفارشی و همچنین نحوه ایجاد ویژگیهای خود میپردازیم. همچنین بسیاری از ویژگیهای دیگر به غیر از derive وجود دارند؛ برای اطلاعات بیشتر، به بخش «ویژگیها» در مرجع Rust مراجعه کنید.
تابع area ما بسیار خاص است: فقط مساحت مستطیلها را محاسبه میکند. مفید خواهد بود اگر این رفتار را به صورت نزدیکتر با ساختار Rectangle مرتبط کنیم، زیرا این تابع با هیچ نوع دیگری کار نخواهد کرد. بیایید ببینیم که چگونه میتوانیم با تبدیل تابع area به یک متد که برای نوع Rectangle تعریف شده است، این کد را بازنویسی کنیم.
متد
متدها شبیه به توابع هستند: آنها را با کلیدواژهی fn و یک نام تعریف میکنیم،
میتوانند پارامتر و مقدار بازگشتی داشته باشند، و شامل مقداری کد هستند
که هنگام فراخوانی متد از جایی دیگر اجرا میشود. برخلاف توابع،
متدها در بستر یک struct (یا یک enum یا یک trait object که به ترتیب در فصل ۶ و فصل ۱۸ بررسی میشوند) تعریف میشوند،
و اولین پارامتر آنها همیشه self است، که نشاندهندهی نمونهای از struct است
که متد روی آن فراخوانی شده است.
تعریف متدها
بیایید تابع area که یک نمونه از Rectangle را به عنوان پارامتر میگیرد، تغییر دهیم و به جای آن، یک متد area تعریف کنیم که روی ساختار Rectangle تعریف شده است، همانطور که در لیست ۵-۱۳ نشان داده شده است.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!( "The area of the rectangle is {} square pixels.", rect1.area() ); }
area روی ساختار Rectangleبرای تعریف تابع در زمینه Rectangle، یک بلوک impl (پیادهسازی) برای Rectangle شروع میکنیم. هر چیزی در این بلوک impl با نوع Rectangle مرتبط خواهد بود. سپس، تابع area را به درون آکولادهای impl منتقل کرده و اولین (و در اینجا تنها) پارامتر آن را در امضا و در هر جایی در بدنه به self تغییر میدهیم. در main، جایی که تابع area را فراخوانی میکردیم و rect1 را به عنوان آرگومان ارسال میکردیم، اکنون میتوانیم از نحو متد برای فراخوانی متد area روی نمونه Rectangle خود استفاده کنیم. نحو متد بعد از یک نمونه قرار میگیرد: نقطهای اضافه میکنیم و به دنبال آن نام متد، پرانتزها و هر آرگومان دیگری قرار میدهیم.
در امضای area، از &self به جای rectangle: &Rectangle استفاده میکنیم. &self در واقع معادل کوتاهشدهای از self: &Self است. درون یک بلوک impl، نوع Self نام مستعاری برای نوعی است که بلوک impl برای آن تعریف شده است. متدها باید به عنوان پارامتر اول خود یک پارامتری به نام self از نوع Self داشته باشند، بنابراین Rust به شما اجازه میدهد این عبارت را با فقط نوشتن self در محل اولین پارامتر کوتاه کنید. توجه داشته باشید که همچنان باید از & در مقابل اختصار self استفاده کنیم تا نشان دهیم که این متد نمونه Self را قرض میگیرد، دقیقاً همانطور که در rectangle: &Rectangle استفاده میکردیم. متدها میتوانند مالکیت self را بگیرند، self را به صورت غیرقابل تغییر قرض بگیرند، همانطور که در اینجا انجام دادهایم، یا self را به صورت قابل تغییر قرض بگیرند، دقیقاً مانند هر پارامتر دیگری.
ما در اینجا &self را انتخاب کردهایم به همان دلیلی که در نسخه تابع از &Rectangle استفاده کردیم: ما نمیخواهیم مالکیت را بگیریم و فقط میخواهیم دادهها را در ساختار بخوانیم، نه اینکه آنها را تغییر دهیم. اگر بخواهیم نمونهای که متد روی آن فراخوانی شده است را به عنوان بخشی از کاری که متد انجام میدهد تغییر دهیم، به عنوان پارامتر اول از &mut self استفاده میکنیم. داشتن متدی که مالکیت نمونه را میگیرد با استفاده از فقط self به عنوان پارامتر اول به ندرت اتفاق میافتد؛ این تکنیک معمولاً زمانی استفاده میشود که متد self را به چیز دیگری تبدیل کند و شما بخواهید از استفاده از نمونه اصلی پس از تبدیل جلوگیری کنید.
دلیل اصلی استفاده از متدها به جای توابع، علاوه بر ارائه نحو متد و عدم نیاز به تکرار نوع self در امضای هر متد، سازماندهی است. ما تمام کارهایی که میتوانیم با یک نمونه از یک نوع انجام دهیم را در یک بلوک impl قرار دادهایم، به جای اینکه کاربران آینده کد ما به دنبال قابلیتهای Rectangle در مکانهای مختلف در کتابخانهای که ارائه میدهیم بگردند.
توجه داشته باشید که میتوانیم تصمیم بگیریم متدی با همان نام یک فیلد ساختار تعریف کنیم. برای مثال، میتوانیم متدی روی Rectangle تعریف کنیم که نام آن نیز width باشد:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn width(&self) -> bool { self.width > 0 } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; if rect1.width() { println!("The rectangle has a nonzero width; it is {}", rect1.width); } }
Here is the continuation of the translation for “ch05-03-method-syntax.md” into Persian:
در اینجا ما تصمیم گرفتهایم متد width را طوری تعریف کنیم که اگر مقدار در فیلد width نمونه بزرگتر از 0 باشد مقدار true و در غیر این صورت مقدار false برگرداند: ما میتوانیم از یک فیلد درون یک متد با همان نام برای هر منظوری استفاده کنیم. در main، وقتی که ما rect1.width را با پرانتز دنبال میکنیم، Rust میداند که منظور ما متد width است. وقتی از پرانتز استفاده نمیکنیم، Rust میداند که منظور ما فیلد width است.
اغلب، اما نه همیشه، زمانی که به یک متد نامی مشابه یک فیلد میدهیم، میخواهیم که این متد تنها مقدار موجود در فیلد را بازگرداند و هیچ کار دیگری انجام ندهد. متدهایی مانند اینها getter نامیده میشوند، و Rust آنها را به صورت خودکار برای فیلدهای ساختار پیادهسازی نمیکند، همانطور که برخی از زبانهای دیگر انجام میدهند. Getterها مفید هستند زیرا میتوانید فیلد را خصوصی کنید اما متد را عمومی کنید و به این ترتیب دسترسی فقط-خواندنی به آن فیلد را به عنوان بخشی از API عمومی نوع فعال کنید. ما در فصل ۷ در مورد عمومی و خصوصی بودن و چگونگی تعیین عمومی یا خصوصی بودن یک فیلد یا متد بحث خواهیم کرد.
کجاست عملگر ->؟
در C و C++، دو عملگر مختلف برای فراخوانی متدها استفاده میشود: شما از . استفاده میکنید اگر متد را روی خود شیء فراخوانی میکنید و از -> اگر متد را روی یک اشارهگر (Pointer) به شیء فراخوانی میکنید و نیاز دارید ابتدا اشارهگر (Pointer) را اشارهبرداری کنید. به عبارت دیگر، اگر object یک اشارهگر (Pointer) باشد، object->something() شبیه به (*object).something() است.
Rust معادل عملگر -> را ندارد؛ به جای آن، Rust یک ویژگی به نام ارجاعدهی و اشارهبرداری خودکار دارد. فراخوانی متدها یکی از معدود مکانهایی در Rust است که این رفتار را دارد.
اینگونه کار میکند: وقتی یک متد را با object.something() فراخوانی میکنید، Rust به طور خودکار &، &mut یا * را اضافه میکند تا object با امضای متد مطابقت داشته باشد. به عبارت دیگر، موارد زیر یکسان هستند:
#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }
اولین مورد خیلی تمیزتر به نظر میرسد. این رفتار ارجاعدهی خودکار کار میکند زیرا متدها یک گیرنده واضح دارند—نوع self. با توجه به گیرنده و نام یک متد، Rust میتواند به طور قطعی تعیین کند که آیا متد در حال خواندن (&self)، تغییر (&mut self) یا مصرف (self) است. این واقعیت که Rust قرضگیری را برای گیرندههای متد ضمنی میکند، بخش بزرگی از راحتی کار با مالکیت در عمل است.
متدهایی با پارامترهای بیشتر
بیایید با تعریف یک متد دیگر روی ساختار Rectangle تمرین کنیم. این بار میخواهیم یک نمونه از Rectangle نمونه دیگری از Rectangle را بگیرد و مقدار true برگرداند اگر Rectangle دوم کاملاً در self (اولین Rectangle) جای گیرد؛ در غیر این صورت مقدار false برگرداند. به عبارت دیگر، پس از تعریف متد can_hold، میخواهیم بتوانیم برنامهای بنویسیم که در لیست ۵-۱۴ نشان داده شده است.
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}can_hold که هنوز نوشته نشده استخروجی مورد انتظار به صورت زیر خواهد بود زیرا هر دو بُعد rect2 کوچکتر از ابعاد rect1 هستند، اما rect3 از rect1 عریضتر است:
Can rect1 hold rect2? true
Can rect1 hold rect3? false
ما میدانیم که میخواهیم یک متد تعریف کنیم، بنابراین این متد در بلوک impl Rectangle خواهد بود. نام متد can_hold خواهد بود و یک قرض غیرقابل تغییر از یک Rectangle دیگر به عنوان پارامتر خواهد گرفت. میتوانیم نوع پارامتر را با نگاه به کدی که متد را فراخوانی میکند تشخیص دهیم: rect1.can_hold(&rect2) مقدار &rect2 را ارسال میکند، که یک قرض غیرقابل تغییر به rect2، یک نمونه از Rectangle است. این منطقی است زیرا ما فقط نیاز به خواندن rect2 داریم (نه نوشتن، که به یک قرض قابل تغییر نیاز داشت) و میخواهیم مالکیت rect2 در main باقی بماند تا بتوانیم پس از فراخوانی متد can_hold دوباره از آن استفاده کنیم. مقدار بازگشتی can_hold یک مقدار بولی خواهد بود و پیادهسازی بررسی میکند که آیا عرض و ارتفاع self به ترتیب بزرگتر از عرض و ارتفاع Rectangle دیگر هستند. بیایید متد جدید can_hold را به بلوک impl از لیست ۵-۱۳ اضافه کنیم، همانطور که در لیست ۵-۱۵ نشان داده شده است.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
can_hold روی Rectangle که یک نمونه دیگر از Rectangle را به عنوان پارامتر میگیردHere is the continuation of the translation for “ch05-03-method-syntax.md” into Persian:
وقتی این کد را با تابع main موجود در لیست ۵-۱۴ اجرا میکنیم، خروجی دلخواه را دریافت خواهیم کرد. متدها میتوانند چندین پارامتر بگیرند که ما آنها را پس از پارامتر self به امضا اضافه میکنیم، و این پارامترها همانند پارامترهای توابع عمل میکنند.
توابع مرتبط
تمام توابعی که در یک بلوک impl تعریف شدهاند توابع مرتبط نامیده میشوند، زیرا با نوعی که بعد از impl نامگذاری شده است، مرتبط هستند. ما میتوانیم توابع مرتبطی را تعریف کنیم که self را به عنوان اولین پارامتر خود ندارند (و بنابراین متد نیستند) زیرا نیازی به کار با یک نمونه از نوع ندارند. ما قبلاً از یک تابع مشابه استفاده کردهایم: تابع String::from که روی نوع String تعریف شده است.
توابع مرتبطی که متد نیستند اغلب برای سازندهها استفاده میشوند که نمونه جدیدی از ساختار را بازمیگردانند. این توابع معمولاً new نامیده میشوند، اما new یک نام خاص نیست و در زبان به صورت داخلی تعریف نشده است. برای مثال، ما میتوانیم تصمیم بگیریم تابع مرتبطی به نام square ارائه دهیم که یک پارامتر برای ابعاد بگیرد و از آن به عنوان عرض و ارتفاع استفاده کند، بنابراین ایجاد یک Rectangle مربعی را آسانتر میکند به جای اینکه مجبور باشیم مقدار یکسان را دو بار مشخص کنیم:
Filename: src/main.rs
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn square(size: u32) -> Self { Self { width: size, height: size, } } } fn main() { let sq = Rectangle::square(3); }
کلمات کلیدی Self در نوع بازگشتی و در بدنه تابع، نام مستعاری برای نوعی هستند که بعد از کلمه کلیدی impl ظاهر میشود، که در اینجا Rectangle است.
برای فراخوانی این تابع مرتبط، از نحو :: همراه با نام ساختار استفاده میکنیم؛ برای مثال: let sq = Rectangle::square(3);. این تابع با ساختار فضای نامگذاری شده است: نحو :: برای توابع مرتبط و فضای نامهای ایجاد شده توسط ماژولها استفاده میشود. ما ماژولها را در فصل ۷ بررسی خواهیم کرد.
بلوکهای متعدد impl
هر ساختار اجازه دارد چندین بلوک impl داشته باشد. برای مثال، لیست ۵-۱۵ معادل کدی است که در لیست ۵-۱۶ نشان داده شده است، که هر متد در بلوک impl خود قرار دارد.
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } impl Rectangle { fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; let rect2 = Rectangle { width: 10, height: 40, }; let rect3 = Rectangle { width: 60, height: 45, }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
implهیچ دلیلی برای جدا کردن این متدها به بلوکهای متعدد impl در اینجا وجود ندارد، اما این یک نحو معتبر است. ما در فصل ۱۰ موردی را خواهیم دید که در آن بلوکهای متعدد impl مفید هستند، جایی که ما نوعهای عمومی و ویژگیها را بررسی خواهیم کرد.
خلاصه
ساختارها به شما اجازه میدهند تا نوعهای سفارشی ایجاد کنید که برای حوزه کاری شما معنادار باشند. با استفاده از ساختارها، میتوانید قطعات دادهای مرتبط را به هم متصل کنید و برای هر قطعه نامی تعیین کنید تا کد شما شفاف شود. در بلوکهای impl، شما میتوانید توابعی را تعریف کنید که با نوع شما مرتبط هستند، و متدها نوعی از توابع مرتبط هستند که به شما اجازه میدهند رفتار نمونههای ساختارهایتان را مشخص کنید.
اما ساختارها تنها راه ایجاد نوعهای سفارشی نیستند: بیایید به ویژگی Enum در Rust بپردازیم تا ابزار دیگری به جعبه ابزار شما اضافه کنیم.
شمارندهها و تطابق الگو
در این فصل، به شمارندهها که همچنین به عنوان enums شناخته میشوند، میپردازیم. شمارندهها به شما اجازه میدهند
یک نوع را با شمردن مقادیر ممکن آن تعریف کنید. ابتدا، یک شمارنده تعریف کرده و از آن استفاده میکنیم تا نشان دهیم چگونه
شمارنده میتواند معنی را همراه با داده کدگذاری کند. سپس، به شمارندهای بسیار مفید به نام Option خواهیم پرداخت که
بیان میکند یک مقدار میتواند چیزی باشد یا هیچ چیز. بعد، بررسی خواهیم کرد که چگونه تطابق الگو در عبارت match
باعث میشود اجرای کد مختلف برای مقادیر مختلف یک شمارنده آسان شود. در نهایت، پوشش خواهیم داد که ساختار if let چگونه
ایدهآل و مختصر برای مدیریت شمارندهها در کد شما است.
تعریف یک Enum
در حالی که ساختارها (Structs) روشی برای گروهبندی فیلدها و دادههای مرتبط فراهم میکنند، Enumها به شما امکان میدهند که بگویید یک مقدار یکی از مجموعه مقادیر ممکن است. به عنوان مثال، ممکن است بخواهیم بگوییم که Rectangle یکی از مجموعه اشکالی است که همچنین شامل Circle و Triangle میشود. برای انجام این کار، زبان Rust به ما اجازه میدهد تا این امکانها را بهعنوان یک Enum کدگذاری کنیم.
بیایید نگاهی به یک موقعیت بیندازیم که ممکن است بخواهیم در کد بیان کنیم و ببینیم چرا Enumها مفیدتر و مناسبتر از Structها هستند. فرض کنید باید با آدرسهای IP کار کنیم. در حال حاضر، دو استاندارد اصلی برای آدرسهای IP وجود دارد: نسخه چهار و نسخه شش. از آنجا که این تنها حالتهای ممکن برای آدرسهای IP هستند که برنامه ما با آنها مواجه خواهد شد، میتوانیم تمام حالتهای ممکن را شمارش کنیم، که همین موضوع اساس نامگذاری Enumها است.
هر آدرس IP میتواند یا نسخه چهار یا نسخه شش باشد، اما نمیتواند بهطور همزمان هر دو باشد. این ویژگی آدرسهای IP استفاده از ساختار داده Enum را مناسب میکند زیرا مقدار یک Enum میتواند فقط یکی از حالتهایش باشد. هر دو آدرس نسخه چهار و نسخه شش همچنان اساساً آدرس IP هستند، بنابراین باید هنگام کار با کدی که به هر نوع آدرس IP اعمال میشود، بهعنوان یک نوع یکسان رفتار شوند.
ما میتوانیم این مفهوم را در کد با تعریف یک Enumeration به نام IpAddrKind و فهرست کردن انواع ممکن یک آدرس IP، یعنی V4 و V6، بیان کنیم. اینها حالتهای Enum هستند:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
اکنون IpAddrKind یک نوع داده سفارشی است که میتوانیم در قسمتهای دیگر کد خود استفاده کنیم.
مقادیر Enum
میتوانیم نمونههایی از هر یک از دو حالت IpAddrKind را به این صورت ایجاد کنیم:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
توجه داشته باشید که حالتهای Enum تحت شناسه آن نامگذاری شدهاند و برای جدا کردن دو حالت از یکدیگر از دو نقطه استفاده میکنیم. این ویژگی مفید است زیرا اکنون هر دو مقدار IpAddrKind::V4 و IpAddrKind::V6 از نوع یکسان IpAddrKind هستند. سپس میتوانیم به عنوان مثال یک تابع تعریف کنیم که هر نوع IpAddrKind را به عنوان ورودی بپذیرد:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
و میتوانیم این تابع را با هر دو حالت فراخوانی کنیم:
enum IpAddrKind { V4, V6, } fn main() { let four = IpAddrKind::V4; let six = IpAddrKind::V6; route(IpAddrKind::V4); route(IpAddrKind::V6); } fn route(ip_kind: IpAddrKind) {}
استفاده از Enumها مزایای بیشتری دارد. اگر بیشتر به نوع آدرس IP خود فکر کنیم، متوجه میشویم که در حال حاضر راهی برای ذخیره دادههای واقعی آدرس IP نداریم؛ فقط میدانیم که چه نوعی است. با توجه به اینکه بهتازگی درباره Structها در فصل 5 یاد گرفتهاید، ممکن است وسوسه شوید این مشکل را با Structها همانطور که در فهرست 6-1 نشان داده شده است، حل کنید.
fn main() { enum IpAddrKind { V4, V6, } struct IpAddr { kind: IpAddrKind, address: String, } let home = IpAddr { kind: IpAddrKind::V4, address: String::from("127.0.0.1"), }; let loopback = IpAddr { kind: IpAddrKind::V6, address: String::from("::1"), }; }
IpAddrKind یک آدرس IP با استفاده از یک structدر اینجا ما یک Struct به نام IpAddr تعریف کردهایم که دو فیلد دارد: یک فیلد kind که از نوع IpAddrKind است (همان Enum که قبلاً تعریف کردیم) و یک فیلد address از نوع String. ما دو نمونه از این Struct داریم. اولین مورد home نام دارد و مقدار IpAddrKind::V4 بهعنوان kind با دادههای آدرس مرتبط 127.0.0.1 دارد. نمونه دوم loopback نام دارد. این نمونه حالت دیگر Enum یعنی V6 را بهعنوان مقدار kind دارد و آدرس مرتبط ::1 است. ما از یک Struct برای بستهبندی مقادیر kind و address با هم استفاده کردهایم، بنابراین اکنون حالت با مقدار مرتبط شده است.
با این حال، نمایش همان مفهوم با استفاده از فقط یک Enum مختصرتر است: بهجای استفاده از Enum داخل یک Struct، میتوانیم دادهها را مستقیماً به هر حالت Enum متصل کنیم. این تعریف جدید Enum IpAddr نشان میدهد که هر دو حالت V4 و V6 مقادیر String مرتبط دارند:
fn main() { enum IpAddr { V4(String), V6(String), } let home = IpAddr::V4(String::from("127.0.0.1")); let loopback = IpAddr::V6(String::from("::1")); }
ما دادهها را مستقیماً به هر حالت Enum متصل کردهایم، بنابراین نیازی به یک Struct اضافی نیست. در اینجا همچنین میتوان جزئیات دیگری از نحوه عملکرد Enumها را مشاهده کرد: نام هر حالت Enum که تعریف میکنیم بهصورت یک تابع تبدیل میشود که نمونهای از Enum ایجاد میکند. یعنی IpAddr::V4() یک فراخوانی تابع است که یک آرگومان از نوع String میگیرد و نمونهای از نوع IpAddr برمیگرداند. این تابع سازنده بهطور خودکار بهعنوان نتیجه تعریف Enum تعریف میشود.
یک مزیت دیگر استفاده از Enum بهجای Struct این است که هر حالت میتواند انواع و مقادیر داده مرتبط متفاوتی داشته باشد. آدرسهای IP نسخه چهار همیشه چهار مؤلفه عددی خواهند داشت که مقادیرشان بین 0 و 255 است. اگر بخواهیم آدرسهای V4 را بهصورت چهار مقدار u8 ذخیره کنیم اما همچنان آدرسهای V6 را بهصورت یک مقدار String بیان کنیم، با یک Struct نمیتوانیم این کار را انجام دهیم. Enumها بهراحتی این حالت را مدیریت میکنند:
fn main() { enum IpAddr { V4(u8, u8, u8, u8), V6(String), } let home = IpAddr::V4(127, 0, 0, 1); let loopback = IpAddr::V6(String::from("::1")); }
ما چندین روش مختلف برای تعریف ساختارهای داده برای ذخیره آدرسهای IP نسخه چهار و نسخه شش نشان دادهایم. با این حال، همانطور که مشخص است، ذخیره آدرسهای IP و کدگذاری نوع آنها بهقدری رایج است که کتابخانه استاندارد تعریفی برای این کار ارائه میدهد! بیایید نگاهی به نحوه تعریف IpAddr در کتابخانه استاندارد بیندازیم: این کتابخانه دارای همان Enum و حالتهایی است که ما تعریف کرده و استفاده کردهایم، اما دادههای آدرس را بهصورت داخلی در حالتها در قالب دو Struct مختلف تعبیه کرده است، که بهطور متفاوت برای هر حالت تعریف شدهاند:
#![allow(unused)] fn main() { struct Ipv4Addr { // --snip-- } struct Ipv6Addr { // --snip-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
این کد نشان میدهد که شما میتوانید هر نوع دادهای مانند رشتهها، انواع عددی، یا Structها را داخل حالتهای Enum قرار دهید. حتی میتوانید یک Enum دیگر را نیز شامل کنید! همچنین، انواع استاندارد کتابخانه معمولاً خیلی پیچیدهتر از چیزی نیستند که ممکن است خودتان ارائه دهید.
توجه داشته باشید که با وجود اینکه کتابخانه استاندارد تعریفی برای IpAddr دارد، ما همچنان میتوانیم تعریف خودمان را ایجاد و استفاده کنیم بدون اینکه تضادی پیش بیاید زیرا تعریف کتابخانه استاندارد را به محدوده خود وارد نکردهایم. ما در فصل 7 درباره وارد کردن انواع به محدوده بیشتر صحبت خواهیم کرد.
بیایید به مثال دیگری از یک Enum در فهرست 6-2 نگاه کنیم: این مورد دارای انواع متنوعی از دادههای جاسازیشده در حالتهای خود است.
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() {}
Message که هر یک از حالتهای آن مقادیر متفاوتی ذخیره میکننداین Enum دارای چهار حالت با انواع مختلف است:
Quit: هیچ دادهای همراه خود نداردMove: دارای فیلدهای نامگذاریشده است، مانند یکstructWrite: شامل یکStringواحد استChangeColor: شامل سه مقدار از نوعi32است
تعریف یک Enum با حالتهایی مانند حالتهای فهرست 6-2 مشابه تعریف انواع مختلف ساختارها است، با این تفاوت که Enum از کلمه کلیدی struct استفاده نمیکند و تمام حالتها تحت نوع Message گروهبندی شدهاند. ساختارهای زیر میتوانند همان دادههایی را نگه دارند که حالتهای Enum قبلی نگه میدارند:
struct QuitMessage; // unit struct struct MoveMessage { x: i32, y: i32, } struct WriteMessage(String); // tuple struct struct ChangeColorMessage(i32, i32, i32); // tuple struct fn main() {}
اما اگر از ساختارهای مختلفی استفاده کنیم که هر یک نوع خاص خود را دارند، نمیتوانیم بهراحتی یک تابع تعریف کنیم که بتواند هر یک از این انواع پیامها را مانند چیزی که با Enum Message تعریفشده در فهرست 6-2 امکانپذیر است، دریافت کند.
یک شباهت دیگر بین Enumها و ساختارها این است: همانطور که میتوانیم متدها را با استفاده از impl برای ساختارها تعریف کنیم، میتوانیم متدها را برای Enumها نیز تعریف کنیم. اینجا یک متد به نام call است که میتوانیم برای Enum Message خود تعریف کنیم:
fn main() { enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } impl Message { fn call(&self) { // method body would be defined here } } let m = Message::Write(String::from("hello")); m.call(); }
بدنه این متد از self برای دسترسی به مقداری که متد روی آن فراخوانی شده است استفاده میکند. در این مثال، ما یک متغیر به نام m ایجاد کردهایم که مقدار Message::Write(String::from("hello")) را دارد و این همان چیزی است که self در بدن متد call هنگام اجرای m.call() خواهد بود.
بیایید به یک Enum دیگر در کتابخانه استاندارد که بسیار متداول و مفید است نگاهی بیندازیم: Option.
Enum Option و مزایای آن نسبت به مقادیر Null
این بخش به مطالعه موردی Option میپردازد که یکی دیگر از Enumهای تعریف شده در کتابخانه استاندارد است. نوع Option سناریوی بسیار رایجی را نشان میدهد که در آن یک مقدار میتواند وجود داشته باشد یا هیچ مقداری وجود نداشته باشد.
به عنوان مثال، اگر اولین مورد را در یک لیست غیر خالی درخواست کنید، مقداری دریافت خواهید کرد. اگر اولین مورد را در یک لیست خالی درخواست کنید، هیچ مقداری دریافت نخواهید کرد. بیان این مفهوم در قالب سیستم نوع به کامپایلر امکان میدهد تا بررسی کند آیا تمام مواردی که باید مدیریت شوند را در نظر گرفتهاید؛ این ویژگی میتواند از بروز باگهایی که در دیگر زبانهای برنامهنویسی بسیار رایج هستند جلوگیری کند.
طراحی زبانهای برنامهنویسی اغلب از نظر ویژگیهایی که شامل میشوند بررسی میشود، اما ویژگیهایی که کنار گذاشته میشوند نیز مهم هستند. Rust ویژگی null را که بسیاری از زبانهای دیگر دارند، ندارد. Null یک مقدار است که به معنای وجود نداشتن مقدار میباشد. در زبانهایی که دارای null هستند، متغیرها میتوانند همیشه در یکی از دو حالت باشند: null یا not-null.
در ارائهی سال ۲۰۰۹ خود با عنوان «ارجاعات تهی: اشتباه میلیارد دلاری»(Null References: The Billion Dollar Mistake,”)، تونی هوار،
مخترع null، این سخن را بیان کرد:
من آن را اشتباه میلیارد دلاری خود مینامم. در آن زمان، من در حال طراحی اولین سیستم نوع جامع برای مراجع در یک زبان شیءگرا بودم. هدف من اطمینان از این بود که تمام استفادههای از مراجع کاملاً امن باشند، با بررسیهایی که بهطور خودکار توسط کامپایلر انجام میشوند. اما نتوانستم در برابر وسوسه قرار دادن یک مرجع null مقاومت کنم، فقط به این دلیل که پیادهسازی آن بسیار آسان بود. این منجر به خطاها، آسیبپذیریها، و خرابیهای سیستمهای بیشماری شده است که احتمالاً باعث یک میلیارد دلار درد و ضرر در چهل سال گذشته شدهاند.
مشکل مقادیر null این است که اگر بخواهید از یک مقدار null بهعنوان یک مقدار not-null استفاده کنید، نوعی خطا دریافت خواهید کرد. از آنجا که خاصیت null یا not-null فراگیر است، بسیار آسان است که این نوع خطا را مرتکب شوید.
با این حال، مفهومی که null سعی در بیان آن دارد همچنان مفید است: null یک مقدار است که در حال حاضر به دلایلی نامعتبر یا غایب است.
مشکل واقعاً با مفهوم نیست، بلکه با پیادهسازی خاص است. به این ترتیب، Rust مقادیر null ندارد، اما یک Enum دارد که میتواند مفهوم وجود داشتن یا نداشتن یک مقدار را کدگذاری کند. این Enum Option<T> است که به صورت زیر توسط کتابخانه استاندارد تعریف شده است:
#![allow(unused)] fn main() { enum Option<T> { None, Some(T), } }
Enum Option<T> آنقدر مفید است که حتی در بخش پیشفرض (Prelude) گنجانده شده است؛ نیازی نیست که بهطور صریح آن را به محدوده بیاورید. حالتهای آن نیز در بخش پیشفرض هستند: میتوانید مستقیماً از Some و None بدون پیشوند Option:: استفاده کنید. Enum Option<T> همچنان یک Enum معمولی است، و Some(T) و None همچنان حالتهایی از نوع Option<T> هستند.
سینتکس <T> یک ویژگی از Rust است که هنوز درباره آن صحبت نکردهایم. این یک پارامتر نوع عمومی (Generic) است و ما در فصل 10 به جزئیات بیشتری درباره آن خواهیم پرداخت. برای حالا، تنها چیزی که باید بدانید این است که <T> به این معنا است که حالت Some از Enum Option میتواند یک قطعه داده از هر نوعی را نگه دارد، و هر نوع مشخصی که به جای T استفاده شود، کل نوع Option<T> را به یک نوع متفاوت تبدیل میکند. در اینجا چند مثال از استفاده از مقادیر Option برای نگهداری انواع عددی و کاراکتری آورده شده است:
fn main() { let some_number = Some(5); let some_char = Some('e'); let absent_number: Option<i32> = None; }
نوع some_number برابر با Option<i32> است. نوع some_char برابر با Option<char> است که یک نوع متفاوت است. Rust میتواند این انواع را تشخیص دهد زیرا ما مقداری را در حالت Some مشخص کردهایم. برای absent_number، Rust از ما میخواهد که نوع کلی Option را مشخص کنیم: کامپایلر نمیتواند نوعی را که حالت Some مرتبط نگه خواهد داشت فقط با نگاه کردن به یک مقدار None تشخیص دهد. در اینجا، ما به Rust میگوییم که منظور ما این است که absent_number از نوع Option<i32> باشد.
هنگامی که ما یک مقدار Some داریم، میدانیم که یک مقدار وجود دارد و این مقدار درون Some نگهداری میشود. هنگامی که ما یک مقدار None داریم، از یک نظر، این همان معنای null را دارد: ما یک مقدار معتبر نداریم. پس چرا داشتن Option<T> بهتر از داشتن null است؟
به طور خلاصه، به این دلیل که Option<T> و T (جایی که T میتواند هر نوعی باشد) انواع متفاوتی هستند، کامپایلر به ما اجازه نمیدهد که یک مقدار Option<T> را بهعنوان یک مقدار قطعاً معتبر استفاده کنیم. به عنوان مثال، این کد کامپایل نخواهد شد، زیرا سعی در جمع یک i8 با یک Option<i8> دارد:
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}اگر این کد را اجرا کنیم، پیام خطایی شبیه به این دریافت میکنیم:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
شدید است! در واقع، این پیام خطا به این معنا است که Rust نمیداند چگونه یک i8 و یک Option<i8> را جمع کند، زیرا آنها انواع مختلفی هستند. هنگامی که یک مقدار از نوعی مانند i8 در Rust داریم، کامپایلر اطمینان میدهد که همیشه یک مقدار معتبر داریم. میتوانیم با اطمینان ادامه دهیم بدون اینکه مجبور باشیم قبل از استفاده از آن مقدار، null را بررسی کنیم. فقط زمانی که یک Option<i8> (یا هر نوع مقداری که با آن کار میکنیم) داریم باید نگران احتمال عدم وجود مقدار باشیم، و کامپایلر اطمینان میدهد که ما آن حالت را قبل از استفاده از مقدار مدیریت کردهایم.
به عبارت دیگر، شما باید یک مقدار Option<T> را به یک مقدار T تبدیل کنید قبل از اینکه بتوانید عملیات T را با آن انجام دهید. به طور کلی، این به جلوگیری از یکی از شایعترین مشکلات null کمک میکند: فرض غلط که چیزی null نیست در حالی که واقعاً null است.
از بین بردن خطر فرض نادرست درباره یک مقدار not-null به شما کمک میکند تا در کد خود اطمینان بیشتری داشته باشید. برای داشتن مقداری که ممکن است null باشد، باید صریحاً با تعیین نوع آن مقدار بهعنوان Option<T> به آن رضایت دهید. سپس، هنگامی که از آن مقدار استفاده میکنید، موظف هستید که بهطور صریح حالتی را که مقدار null است مدیریت کنید. هر جا که مقداری از نوعی است که Option<T> نیست، میتوانید با خیال راحت فرض کنید که مقدار null نیست. این تصمیم طراحی برای محدود کردن شیوع null و افزایش ایمنی کدهای Rust بود.
پس چگونه مقدار T را از حالت Some وقتی که یک مقدار از نوع Option<T> دارید استخراج میکنید تا بتوانید از آن مقدار استفاده کنید؟ Enum Option<T> تعداد زیادی متد دارد که در موقعیتهای مختلف مفید هستند؛ میتوانید آنها را در مستندات آن بررسی کنید. آشنایی با متدهای موجود در Option<T> در مسیر یادگیری Rust بسیار مفید خواهد بود.
به طور کلی، برای استفاده از یک مقدار Option<T>، میخواهید کدی داشته باشید که هر حالت را مدیریت کند. میخواهید کدی داشته باشید که تنها زمانی اجرا شود که یک مقدار Some(T) دارید، و این کد اجازه دارد از مقدار داخلی T استفاده کند. همچنین، میخواهید کدی داشته باشید که فقط در صورت وجود مقدار None اجرا شود، و این کد به هیچ مقدار T دسترسی ندارد. عبارت match یک سازه جریان کنترلی است که وقتی با Enumها استفاده میشود دقیقاً این کار را انجام میدهد: این عبارت کد متفاوتی را بسته به اینکه کدام حالت از Enum موجود است اجرا میکند، و آن کد میتواند از داده داخل مقدار منطبق شده استفاده کند.
سازه جریان کنترلی match
زبان Rust دارای یک سازه جریان کنترلی بسیار قدرتمند به نام match است که به شما اجازه میدهد تا یک مقدار را با یک سری الگوها مقایسه کنید و سپس بر اساس الگویی که مطابقت دارد، کد مربوطه را اجرا کنید. الگوها میتوانند شامل مقادیر ثابت، نام متغیرها، wildcardها و چیزهای دیگر باشند. فصل 19 انواع مختلف الگوها و عملکرد آنها را پوشش میدهد. قدرت match از بیانپذیری الگوها و این واقعیت ناشی میشود که کامپایلر تأیید میکند که همه حالتهای ممکن مدیریت شدهاند.
میتوانید یک عبارت match را مانند یک دستگاه مرتبکننده سکه تصور کنید: سکهها در یک مسیر با سوراخهایی با اندازههای مختلف قرار میگیرند و هر سکه از اولین سوراخی که در آن جا میشود عبور میکند. به همین ترتیب، مقادیر از هر الگو در یک match عبور میکنند و در اولین الگویی که مقدار “جا میشود”، مقدار به بلوک کد مرتبط میافتد و برای اجرا استفاده میشود.
حال بیایید از یک مثال واقعی با سکهها استفاده کنیم! میتوانیم تابعی بنویسیم که یک سکه ناشناخته از ایالات متحده را بگیرد و به شیوهای مشابه دستگاه شمارنده سکهها، تعیین کند که آن سکه کدام نوع است و ارزش آن را به سنت برگرداند، همانطور که در فهرست 6-3 نشان داده شده است.
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
match که حالتهای enum را به عنوان الگوهای خود داردبازبینی تابع value_in_cents
ابتدا کلمه کلیدی match و سپس یک عبارت را فهرست میکنیم که در این مورد مقدار coin است. این کار بسیار مشابه یک عبارت شرطی که با if استفاده میشود به نظر میرسد، اما تفاوت بزرگی دارد: با if، شرط باید به یک مقدار بولین ارزیابی شود، اما اینجا میتواند هر نوعی باشد. نوع coin در این مثال enum Coin است که در اولین خط تعریف کردیم.
بازوهای match دو قسمت دارند: یک الگو و مقداری کد. اولین بازو در اینجا دارای الگویی است که مقدار Coin::Penny است و سپس اپراتور => که الگو و کد اجرایی را از هم جدا میکند. کد در اینجا فقط مقدار 1 است. هر بازو با یک کاما از بازوی بعدی جدا میشود.
هنگامی که عبارت match اجرا میشود، مقدار حاصل را با الگوی هر بازو به ترتیب مقایسه میکند. اگر الگویی با مقدار مطابقت داشته باشد، کدی که با آن الگو مرتبط است اجرا میشود. اگر آن الگو با مقدار مطابقت نداشته باشد، اجرا به بازوی بعدی ادامه مییابد، همانطور که در یک دستگاه مرتبکننده سکهها عمل میکند. ما میتوانیم به هر تعداد بازو که نیاز داریم داشته باشیم: در فهرست 6-3، match ما چهار بازو دارد.
کد مرتبط با هر بازو یک عبارت است و مقدار حاصل از عبارت در بازوی منطبق شده، مقداری است که برای کل عبارت match بازگردانده میشود.
معمولاً اگر کد بازوی match کوتاه باشد، از آکولاد استفاده نمیکنیم، همانطور که در فهرست 6-3 که هر بازو فقط یک مقدار را برمیگرداند. اگر بخواهید چندین خط کد را در یک بازو اجرا کنید، باید از آکولاد استفاده کنید، و در این صورت کاما پس از بازو اختیاری است. به عنوان مثال، کد زیر هر بار که متد با یک Coin::Penny فراخوانی میشود، “Lucky penny!” را چاپ میکند، اما همچنان آخرین مقدار بلوک یعنی 1 را بازمیگرداند:
enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 } Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } fn main() {}
الگوهایی که به مقادیر متصل میشوند
یکی دیگر از ویژگیهای مفید بازوهای match این است که میتوانند به بخشهایی از مقادیر که با الگو مطابقت دارند متصل شوند. این همان روشی است که میتوانیم مقادیر را از حالتهای enum استخراج کنیم.
به عنوان مثال، بیایید یکی از حالتهای enum خود را تغییر دهیم تا دادههایی را درون خود نگه دارد. از سال 1999 تا 2008، ایالات متحده ربعهایی با طرحهای مختلف برای هر یک از 50 ایالت در یک طرف ضرب کرد. هیچ سکه دیگری طرح ایالتی نداشت، بنابراین فقط ربعها این مقدار اضافی را دارند. میتوانیم این اطلاعات را به enum خود با تغییر حالت Quarter به گونهای که یک مقدار UsState درون آن ذخیره شود اضافه کنیم، همانطور که در فهرست 6-4 انجام دادیم.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() {}
Coin که حالت Quarter آن همچنین یک مقدار UsState را نگه میداردبیایید تصور کنیم که یک دوست ما سعی دارد تمام 50 ربع ایالتی را جمعآوری کند. در حالی که ما پولهای خود را بر اساس نوع سکه مرتب میکنیم، همچنین نام ایالتی که با هر ربع مرتبط است را اعلام میکنیم تا اگر این یکی از آنهایی باشد که دوست ما ندارد، بتوانند آن را به مجموعه خود اضافه کنند.
در عبارت match برای این کد، یک متغیر به نام state به الگو اضافه میکنیم که مقادیری از حالت Coin::Quarter را تطبیق میدهد. وقتی که یک مقدار Coin::Quarter منطبق میشود، متغیر state به مقدار ایالت آن ربع متصل خواهد شد. سپس میتوانیم از state در کد بازوی آن استفاده کنیم، به این صورت:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter(state) => { println!("State quarter from {state:?}!"); 25 } } } fn main() { value_in_cents(Coin::Quarter(UsState::Alaska)); }
اگر ما value_in_cents(Coin::Quarter(UsState::Alaska)) را فراخوانی کنیم، مقدار coin برابر با Coin::Quarter(UsState::Alaska) خواهد بود. هنگامی که آن مقدار را با هر بازوی match مقایسه میکنیم، هیچکدام از آنها مطابقت ندارند تا اینکه به Coin::Quarter(state) برسیم. در این نقطه، اتصال برای state مقدار UsState::Alaska خواهد بود. سپس میتوانیم از آن اتصال در عبارت println! استفاده کنیم و به این ترتیب مقدار داخلی ایالت را از حالت Quarter enum Coin استخراج کنیم.
تطبیق با Option<T>
در بخش قبلی، ما میخواستیم مقدار داخلی T را از حالت Some استخراج کنیم زمانی که از Option<T> استفاده میکردیم؛ همچنین میتوانیم با استفاده از match حالتهای Option<T> را مدیریت کنیم، همانطور که با enum Coin انجام دادیم! به جای مقایسه سکهها، حالتهای Option<T> را مقایسه میکنیم، اما روش کار عبارت match همان باقی میماند.
بیایید فرض کنیم که میخواهیم تابعی بنویسیم که یک Option<i32> بگیرد و اگر یک مقدار درون آن باشد، مقدار 1 را به آن اضافه کند. اگر هیچ مقداری درون آن نباشد، تابع باید مقدار None را بازگرداند و هیچ عملیاتی را انجام ندهد.
نوشتن این تابع با استفاده از match بسیار آسان است و به این صورت خواهد بود:
fn main() { fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
اجازه دهید اولین اجرای plus_one را با جزئیات بیشتری بررسی کنیم. وقتی که plus_one(five) را فراخوانی میکنیم، متغیر x در بدنه plus_one مقدار Some(5) خواهد داشت. سپس آن را با هر بازوی match مقایسه میکنیم:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}مقدار Some(5) با الگوی None مطابقت ندارد، بنابراین به بازوی بعدی میرویم:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}آیا Some(5) با Some(i) مطابقت دارد؟ بله! ما همان حالت را داریم. مقدار i به مقدار داخل Some متصل میشود، بنابراین i مقدار 5 میگیرد. سپس کد موجود در بازوی match اجرا میشود، بنابراین مقدار 1 به مقدار i اضافه میکنیم و یک مقدار جدید Some با مقدار کل 6 ایجاد میکنیم.
حالا اجازه دهید اجرای دوم plus_one را در فهرست 6-5 در نظر بگیریم، جایی که مقدار x برابر با None است. ما وارد match میشویم و آن را با اولین بازو مقایسه میکنیم:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}این بار مطابقت دارد! هیچ مقداری برای اضافه کردن وجود ندارد، بنابراین برنامه متوقف میشود و مقدار None در سمت راست => را بازمیگرداند. از آنجا که اولین بازو مطابقت داشت، بازوهای دیگر بررسی نمیشوند.
ترکیب match و enumها در بسیاری از موقعیتها مفید است. این الگو را در کد Rust زیاد خواهید دید: match روی یک enum، اتصال یک متغیر به داده داخل، و سپس اجرای کد بر اساس آن. ممکن است در ابتدا کمی سخت باشد، اما وقتی به آن عادت کنید، آرزو خواهید کرد که در همه زبانها وجود داشته باشد. این سازه همواره یکی از ویژگیهای مورد علاقه کاربران است.
تطابقها Exhaustive هستند
یکی دیگر از جنبههای عبارت match این است که الگوهای بازوها باید تمام حالتهای ممکن را پوشش دهند. به این نسخه از تابع plus_one که یک باگ دارد و کامپایل نمیشود توجه کنید:
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}ما حالت None را مدیریت نکردهایم، بنابراین این کد باعث بروز یک باگ خواهد شد. خوشبختانه، این یک باگ است که Rust میتواند آن را تشخیص دهد. اگر تلاش کنیم این کد را کامپایل کنیم، این خطا را دریافت خواهیم کرد:
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/4eb161250e340c8f48f66e2b929ef4a5bed7c181/library/core/src/option.rs:572:1
::: /rustc/4eb161250e340c8f48f66e2b929ef4a5bed7c181/library/core/src/option.rs:576:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust میداند که ما هر حالت ممکن را پوشش ندادهایم و حتی میداند که کدام الگو را فراموش کردهایم! تطابقها در Rust exhaustive هستند: ما باید هر حالت ممکن را مدیریت کنیم تا کد معتبر باشد. به ویژه در مورد Option<T>، وقتی که Rust از فراموش کردن مدیریت صریح حالت None جلوگیری میکند، از فرض نادرست وجود مقدار زمانی که ممکن است null باشد محافظت میکند و به این ترتیب اشتباه میلیارد دلاری که قبلاً بحث شد را غیرممکن میسازد.
الگوهای Catch-all و Placeholder _
با استفاده از Enumها، میتوانیم اقدامات ویژهای برای چند مقدار خاص انجام دهیم، اما برای تمام مقادیر دیگر یک عمل پیشفرض داشته باشیم. تصور کنید که در حال پیادهسازی یک بازی هستید که اگر بازیکن عدد 3 روی تاس بیاورد، حرکت نمیکند اما یک کلاه زیبا جدید میگیرد. اگر عدد 7 بیاورد، بازیکن یک کلاه زیبا از دست میدهد. برای تمام مقادیر دیگر، بازیکن به اندازه عدد روی تخته بازی حرکت میکند. در اینجا یک عبارت match آورده شده است که این منطق را پیادهسازی میکند. نتیجهی پرتاب تاس به جای مقدار تصادفی، به صورت هاردکد شده قرار داده شده است، و تمام منطق دیگر با توابعی بدون بدنه نشان داده شدهاند زیرا پیادهسازی آنها خارج از محدوده این مثال است:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), other => move_player(other), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn move_player(num_spaces: u8) {} }
برای دو بازوی اول، الگوها مقادیر ثابت 3 و 7 هستند. برای بازوی آخر که تمام مقادیر ممکن دیگر را پوشش میدهد، الگو یک متغیر است که ما آن را other نامیدهایم. کدی که برای بازوی other اجرا میشود، متغیر را با استفاده از تابع move_player میفرستد.
این کد کامپایل میشود، حتی اگر تمام مقادیر ممکن یک u8 را فهرست نکرده باشیم، زیرا بازوی آخر همه مقادیر ذکر نشده را تطبیق میدهد. این الگوی catch-all نیاز تطابق exhaustive را برآورده میکند. توجه داشته باشید که باید بازوی catch-all را در آخر قرار دهیم زیرا الگوها به ترتیب ارزیابی میشوند. اگر بازوی catch-all را زودتر قرار دهیم، بازوهای دیگر هرگز اجرا نخواهند شد، بنابراین Rust به ما هشدار میدهد اگر بعد از یک بازوی catch-all بازوهای دیگری اضافه کنیم!
Rust همچنین یک الگو به نام _ دارد که میتوانیم از آن استفاده کنیم وقتی که میخواهیم یک catch-all داشته باشیم اما نمیخواهیم مقدار در الگوی catch-all را استفاده کنیم. این به Rust میگوید که ما قصد نداریم مقدار را استفاده کنیم، بنابراین Rust درباره یک متغیر استفاده نشده به ما هشدار نمیدهد.
بیایید قوانین بازی را تغییر دهیم: حالا اگر بازیکن هر چیزی به غیر از 3 یا 7 بیاورد، باید دوباره تاس بیندازد. دیگر نیازی به استفاده از مقدار catch-all نیست، بنابراین میتوانیم کد خود را بهجای متغیری به نام other از _ استفاده کنیم:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => reroll(), } fn add_fancy_hat() {} fn remove_fancy_hat() {} fn reroll() {} }
این مثال نیز نیاز تطابق exhaustive را برآورده میکند زیرا ما صریحاً تمام مقادیر دیگر را در بازوی آخر نادیده گرفتهایم و چیزی را فراموش نکردهایم.
در نهایت، قوانین بازی را یک بار دیگر تغییر میدهیم، بنابراین اگر بازیکن هر چیزی غیر از 3 یا 7 بیاورد، هیچ کار دیگری در نوبت او انجام نمیشود. میتوانیم این موضوع را با استفاده از مقدار واحد (نوع tuple خالی که قبلاً در بخش “نوع Tuple” ذکر شد) به عنوان کدی که با بازوی _ همراه است بیان کنیم:
fn main() { let dice_roll = 9; match dice_roll { 3 => add_fancy_hat(), 7 => remove_fancy_hat(), _ => (), } fn add_fancy_hat() {} fn remove_fancy_hat() {} }
اینجا، ما به Rust صریحاً میگوییم که قصد نداریم هیچ مقدار دیگری را که با هیچ الگویی در بازوهای قبلی مطابقت ندارد استفاده کنیم و نمیخواهیم در این حالت کدی اجرا کنیم.
درباره الگوها و تطبیق آنها مطالب بیشتری در فصل 19 پوشش خواهیم داد. فعلاً به سینتکس if let میپردازیم که میتواند در مواقعی که عبارت match کمی طولانی به نظر میرسد، مفید باشد.
جریان کنترلی مختصر با if let و let else
دستور if let به شما اجازه میدهد که if و let را ترکیب کنید و به شکلی کمتر پرحجم، مقادیر مطابق با یک الگو را مدیریت کنید و سایر مقادیر را نادیده بگیرید. برنامهای که در لیستینگ 6-6 نشان داده شده است، بر روی یک مقدار Option<u8> در متغیر config_max مطابقت دارد، اما تنها زمانی که مقدار Some باشد کد را اجرا میکند.
fn main() { let config_max = Some(3u8); match config_max { Some(max) => println!("The maximum is configured to be {max}"), _ => (), } }
match که تنها به اجرای کد زمانی که مقدار Some است اهمیت میدهداگر مقدار Some باشد، مقدار موجود در متغیر Some را با اتصال به متغیر max در الگو چاپ میکنیم. ما نمیخواهیم با مقدار None کاری انجام دهیم. برای برآورده کردن دستور match، باید _ => () را بعد از پردازش تنها یک مورد اضافه کنیم، که کد اضافی آزاردهندهای است.
در عوض، میتوانیم این کد را به شکلی کوتاهتر با استفاده از if let بنویسیم. کد زیر به همان شکل match در لیستینگ 6-6 عمل میکند:
fn main() { let config_max = Some(3u8); if let Some(max) = config_max { println!("The maximum is configured to be {max}"); } }
دستور if let یک الگو و یک عبارت را میگیرد که با یک علامت مساوی جدا شدهاند. این دستور همانند match عمل میکند، جایی که عبارت به match داده میشود و الگو بازوی اول آن است. در این مورد، الگو Some(max) است و متغیر max مقدار داخل Some را میگیرد. سپس میتوانیم از max در بدنه بلوک if let همانطور که در بازوی متناظر match استفاده کردیم، استفاده کنیم. کد در بلوک if let تنها در صورتی اجرا میشود که مقدار با الگو مطابقت داشته باشد.
استفاده از if let به معنای تایپ کمتر، تورفتگی کمتر، و کدنویسی قالبی (boilerplate) کمتر است.
با این حال، بررسی جامعای که match تحمیل میکند را از دست میدهید؛ این بررسی تضمین میکند
که هیچ حالتی را فراموش نکرده باشید. انتخاب بین match و if let بستگی به کاری دارد که
در موقعیت خاص خود انجام میدهید و اینکه آیا دستیابی به اختصار، مبادلهای مناسب در برابر از دست دادن بررسی جامع است یا خیر.
به عبارت دیگر، میتوانید if let را به عنوان یک قند سینتکس برای match تصور کنید که کد را زمانی که مقدار با یک الگو مطابقت دارد اجرا میکند و سپس تمام مقادیر دیگر را نادیده میگیرد.
ما میتوانیم یک else با یک if let اضافه کنیم. بلوک کدی که با else همراه میشود همان بلوک کدی است که با مورد _ در دستور match که معادل if let و else است همراه میشود. دستور Coin را در لیستینگ 6-4 به یاد بیاورید، جایی که نوع Quarter یک مقدار UsState را نیز در خود جای داده بود. اگر میخواستیم تمام سکههای غیر Quarter را که میبینیم بشماریم، همزمان ایالتهای سکههای Quarter را اعلام کنیم، میتوانستیم این کار را با یک دستور match انجام دهیم، مانند این:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; match coin { Coin::Quarter(state) => println!("State quarter from {state:?}!"), _ => count += 1, } }
یا میتوانستیم از یک عبارت if let و else استفاده کنیم، مانند این:
#[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn main() { let coin = Coin::Penny; let mut count = 0; if let Coin::Quarter(state) = coin { println!("State quarter from {state:?}!"); } else { count += 1; } }
ماندن در «مسیر خوشحال» با let...else
الگوی رایج این است که وقتی یک مقدار موجود است، عملیاتی را انجام دهیم و در غیر این صورت،
یک مقدار پیشفرض را بازگردانیم. با ادامه دادن مثال سکهها با یک مقدار UsState،
اگر بخواهیم بر اساس قدمت ایالتی که روی سکهی ۲۵ سنتی (quarter) است،
چیزی خندهدار بگوییم، میتوانیم یک متد روی UsState تعریف کنیم تا سن ایالت را بررسی کند،
مانند مثال زیر:
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { if let Coin::Quarter(state) = coin { if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } else { None } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
سپس ممکن است از if let برای مطابقت با نوع سکه استفاده کنیم، متغیری به نام state را در بدنه شرط معرفی کنیم، همانطور که در لیستینگ 6-7 نشان داده شده است.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { if let Coin::Quarter(state) = coin { if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } else { None } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
if let تو در تو قرار دارند.این کار انجام میشود، اما منطق اجرا را به درون بدنهی عبارت if let منتقل کردهایم،
و اگر کار مورد نظر پیچیدهتر باشد، ممکن است دنبال کردن ارتباط شاخههای سطح بالا دشوار شود.
همچنین میتوانیم از این واقعیت بهره ببریم که عبارات یک مقدار تولید میکنند—
یا برای تولید state از if let استفاده کنیم یا زودتر بازگردیم، همانطور که در لیستینگ 6-8 نشان داده شده است.
(میتوانید کار مشابهی را با match نیز انجام دهید.)
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { let state = if let Coin::Quarter(state) = coin { state } else { return None; }; if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
if let برای تولید یک مقدار یا بازگشت زودهنگام.این تا حدی آزاردهنده است! یک شاخه if let یک مقدار تولید میکند و دیگری کاملاً از تابع بازمیگردد.
برای بیان سادهتر این الگوی رایج، Rust ساختار let...else را ارائه داده است.
سینتکس let...else یک الگو در سمت چپ و یک عبارت در سمت راست میگیرد،
که بسیار شبیه به if let است، اما شاخهی if ندارد و تنها یک شاخهی else دارد.
اگر الگو با مقدار مطابقت داشته باشد، مقدار از درون الگو در حوزهی بیرونی (outer scope) بایند خواهد شد.
اگر الگو مطابقت نداشته باشد، برنامه وارد شاخهی else خواهد شد،
که باید از تابع بازگردد.
در لیستینگ 6-9 میتوانید ببینید که چگونه لیستینگ 6-8 با استفاده از let...else
به جای if let بازنویسی شده است.
#[derive(Debug)] // so we can inspect the state in a minute enum UsState { Alabama, Alaska, // --snip-- } impl UsState { fn existed_in(&self, year: u16) -> bool { match self { UsState::Alabama => year >= 1819, UsState::Alaska => year >= 1959, // -- snip -- } } } enum Coin { Penny, Nickel, Dime, Quarter(UsState), } fn describe_state_quarter(coin: Coin) -> Option<String> { let Coin::Quarter(state) = coin else { return None; }; if state.existed_in(1900) { Some(format!("{state:?} is pretty old, for America!")) } else { Some(format!("{state:?} is relatively new.")) } } fn main() { if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) { println!("{desc}"); } }
let...else برای شفافسازی جریان اجرای تابع.توجه داشته باشید که با این روش، بدنهی اصلی تابع در «مسیر خوشحال» باقی میماند،
بدون آنکه مانند if let جریان کنترل متفاوت و قابلتوجهی بین دو شاخه ایجاد کند.
اگر در موقعیتی هستید که منطق برنامهتان برای بیان با استفاده از match بیش از حد مفصل است،
به یاد داشته باشید که if let و let...else نیز در جعبهابزار Rust شما قرار دارند.
خلاصه
ما اکنون پوشش دادهایم که چگونه از enumها برای ایجاد انواع سفارشی که میتوانند یکی از مجموعه مقادیر شمارششده باشند استفاده کنید. ما نشان دادهایم که چگونه نوع Option<T> از کتابخانه استاندارد به شما کمک میکند از سیستم نوع برای جلوگیری از خطاها استفاده کنید. وقتی مقادیر enum دادههایی درون خود دارند، میتوانید از match یا if let برای استخراج و استفاده از آن مقادیر استفاده کنید، بسته به تعداد مواردی که باید مدیریت کنید.
برنامههای Rust شما اکنون میتوانند مفاهیمی را در حوزه خود بیان کنند و از ساختارها و enumها استفاده کنند. ایجاد انواع سفارشی برای استفاده در API شما ایمنی نوع را تضمین میکند: کامپایلر مطمئن میشود که توابع شما فقط مقادیری از نوعی که هر تابع انتظار دارد دریافت میکنند.
برای ارائه یک API سازمانیافته به کاربران خود که استفاده از آن ساده باشد و فقط دقیقاً آنچه کاربران شما نیاز دارند را آشکار کند، حالا به ماژولهای Rust میپردازیم.
مدیریت پروژههای بزرگ با بستهها، جعبهها (crates) و ماژولها
با نوشتن برنامههای بزرگتر، سازماندهی کد شما اهمیت بیشتری پیدا میکند. با گروهبندی قابلیتهای مرتبط و جدا کردن کدی که ویژگیهای متمایزی دارد، میتوانید مشخص کنید که کد یک ویژگی خاص در کجا پیادهسازی شده و کجا میتوان آن را تغییر داد.
برنامههایی که تا اینجا نوشتهایم، همگی در یک ماژول و در یک فایل بودهاند. با رشد یک پروژه، باید کد را با تقسیم آن به چند ماژول و سپس چند فایل، سازماندهی کنید. یک پکیج میتواند شامل چندین crate دودویی باشد و بهصورت اختیاری یک crate کتابخانهای نیز داشته باشد. با گسترش یک پکیج، میتوانید بخشهایی از آن را به crateهای جداگانه استخراج کنید که به وابستگیهای خارجی تبدیل میشوند. این فصل تمام این تکنیکها را پوشش میدهد. برای پروژههای بسیار بزرگی که از مجموعهای از پکیجهای مرتبط بههم تشکیل شدهاند و با هم رشد میکنند، Cargo قابلیتی به نام workspaces ارائه میدهد که آن را در فصل ۱۴ با عنوان “Cargo Workspaces” بررسی خواهیم کرد.
همچنین درباره جزئیات پیادهسازی که به شما امکان میدهد کد را در سطح بالاتری بازاستفاده کنید صحبت خواهیم کرد: وقتی یک عملیات را پیادهسازی کردهاید، سایر کدها میتوانند از طریق رابط عمومی کد شما آن را فراخوانی کنند بدون این که لازم باشد بدانند چگونه پیادهسازی شده است. نحوه نوشتن کد شما مشخص میکند که کدام بخشها برای سایر کدها عمومی و قابل استفاده هستند و کدام بخشها جزئیات پیادهسازی خصوصی هستند که میتوانید هر زمان بخواهید تغییر دهید. این رویکرد یکی دیگر از روشهایی است که مقدار جزئیاتی که باید به خاطر بسپارید را محدود میکند.
یک مفهوم مرتبط، محدوده (scope) است: زمینهای که در آن کد نوشته شده است و مجموعهای از نامها که به عنوان «در محدوده» تعریف میشوند. هنگام خواندن، نوشتن و کامپایل کد، برنامهنویسان و کامپایلرها باید بدانند که آیا یک نام خاص در یک مکان خاص به متغیر، تابع، ساختار، enum، ماژول، ثابت یا مورد دیگری اشاره دارد و معنای آن مورد چیست. شما میتوانید محدودهها ایجاد کنید و مشخص کنید که کدام نامها در محدوده هستند یا خارج از آن. نمیتوانید دو مورد با نام یکسان در یک محدوده داشته باشید؛ ابزارهایی برای رفع تعارض نامها در دسترس هستند.
Rust مجموعهای از ویژگیها دارد که به شما امکان میدهد سازماندهی کد خود را مدیریت کنید، از جمله جزئیاتی که آشکار میشوند، جزئیاتی که خصوصی هستند، و نامهایی که در هر محدوده در برنامههای شما قرار دارند. این ویژگیها که گاهی به صورت جمعی سیستم ماژول نامیده میشوند شامل موارد زیر هستند:
- Packages: یکی از قابلیتهای Cargo که به شما اجازه میدهد crateها را بسازید، تست کنید و به اشتراک بگذارید
- Crates: یک درخت از ماژولها که یک کتابخانه یا فایل اجرایی تولید میکند
- Modules و use: به شما امکان میدهد سازماندهی، حوزه (scope)، و سطح دسترسی مسیرها را کنترل کنید
- Paths: روشی برای نامگذاری یک آیتم، مانند یک
struct، تابع، یا ماژول
در این فصل، تمام این ویژگیها را پوشش خواهیم داد، نحوه تعامل آنها را توضیح میدهیم و نحوه استفاده از آنها برای مدیریت محدوده را بررسی میکنیم. تا پایان، باید درک جامعی از سیستم ماژول داشته باشید و بتوانید با محدودهها مانند یک حرفهای کار کنید!
بستهها و جعبهها (crates)
اولین بخشهایی که در سیستم ماژول بررسی خواهیم کرد، بستهها و جعبهها (crates) هستند.
یک crate کوچکترین واحدی از کد است که کامپایلر Rust در هر لحظه به آن توجه میکند.
حتی اگر به جای استفاده از cargo، مستقیماً rustc را اجرا کنید و تنها یک فایل کد منبع را (همانطور که در فصل اول در بخش «نوشتن و اجرای یک برنامه Rust» انجام دادیم) به آن بدهید،
کامپایلر آن فایل را به عنوان یک crate در نظر میگیرد.
crateها میتوانند شامل ماژولهایی باشند، و این ماژولها ممکن است در فایلهای دیگری تعریف شده باشند
که هنگام کامپایل، همراه با crate پردازش میشوند، همانطور که در بخشهای بعدی خواهیم دید.
یک crate میتواند یکی از دو نوع زیر باشد: crate دودویی (binary) یا crate کتابخانهای (library).
crateهای دودویی برنامههایی هستند که میتوانید آنها را به فایل اجرایی کامپایل کرده و اجرا کنید،
مانند یک برنامهی خط فرمان یا یک سرور. هر crate دودویی باید تابعی به نام main داشته باشد
که مشخص میکند هنگام اجرای فایل اجرایی، چه اتفاقی میافتد.
تمام crateهایی که تا اینجا ایجاد کردهایم، crateهای دودویی بودهاند.
crateهای کتابخانهای تابع main ندارند و به فایل اجرایی کامپایل نمیشوند.
در عوض، آنها قابلیتهایی را تعریف میکنند که برای اشتراکگذاری میان پروژههای مختلف در نظر گرفته شدهاند.
برای مثال، crate rand که در فصل ۲ از آن استفاده کردیم، قابلیتهایی برای تولید اعداد تصادفی فراهم میکند.
در اغلب موارد، زمانی که Rustaceanها از واژهی “crate” استفاده میکنند، منظورشان crate کتابخانهای است
و این واژه را بهطور معادل با مفهوم عمومی «کتابخانه» در برنامهنویسی به کار میبرند.
ریشهی crate (crate root) فایلی از کد منبع است که کامپایلر Rust از آن شروع میکند و ماژول ریشهی crate را تشکیل میدهد (ماژولها را در بخش “تعریف ماژولها برای کنترل حوزه و سطح دسترسی” با جزئیات توضیح خواهیم داد).
یک package مجموعهای از یک یا چند crate است که مجموعهای از قابلیتها را ارائه میدهد. یک package شامل یک فایل Cargo.toml است که مشخص میکند چگونه crateها باید ساخته شوند. خود Cargo در واقع یک package است که شامل یک crate دودویی برای ابزار خط فرمانی است که تاکنون از آن برای ساخت کد خود استفاده کردهاید. پکیج Cargo همچنین شامل یک crate کتابخانهای است که crate دودویی به آن وابسته است. سایر پروژهها میتوانند به crate کتابخانهای Cargo وابسته شوند تا از همان منطق استفاده کنند که ابزار خط فرمان Cargo از آن بهره میبرد.
یک package میتواند هر تعداد crate دودویی داشته باشد، اما در بیشترین حالت، تنها یک crate کتابخانهای میتواند داشته باشد. هر package باید دستکم شامل یک crate باشد، چه crate کتابخانهای و چه crate دودویی.
بیایید ببینیم وقتی یک بسته ایجاد میکنیم چه اتفاقی میافتد. ابتدا دستور cargo new my-project را وارد میکنیم:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
بعد از اجرای cargo new my-project، از دستور ls استفاده میکنیم تا ببینیم Cargo چه چیزی ایجاد کرده است. در دایرکتوری پروژه، یک فایل Cargo.toml وجود دارد که به ما یک بسته میدهد. همچنین یک دایرکتوری src وجود دارد که شامل فایل main.rs است. فایل Cargo.toml را در ویرایشگر متن خود باز کنید و توجه کنید که هیچ اشارهای به src/main.rs نشده است. Cargo از یک قرارداد پیروی میکند که src/main.rs ریشه جعبه (crate) یک جعبه (crate) باینری با همان نام بسته است. به همین ترتیب، Cargo میداند که اگر دایرکتوری بسته شامل src/lib.rs باشد، بسته شامل یک جعبه (crate) کتابخانهای با همان نام بسته است و src/lib.rs ریشه جعبه (crate) آن است. Cargo فایلهای ریشه جعبه (crate) را به rustc ارسال میکند تا کتابخانه یا فایل اجرایی ساخته شود.
در اینجا، ما یک بسته داریم که تنها شامل src/main.rs است، به این معنی که تنها یک جعبه (crate) باینری به نام my-project دارد. اگر یک بسته شامل src/main.rs و src/lib.rs باشد، آن بسته دو جعبه (crate) خواهد داشت: یک جعبه (crate) باینری و یک کتابخانه، هر دو با همان نام بسته. یک بسته میتواند چندین جعبه (crate) باینری داشته باشد با قرار دادن فایلها در دایرکتوری src/bin: هر فایل یک جعبه (crate) باینری جداگانه خواهد بود.
تعریف ماژولها برای کنترل محدوده و حریم خصوصی
در این بخش، ما درباره ماژولها و سایر بخشهای سیستم ماژول صحبت خواهیم کرد، یعنی مسیرها که به شما امکان میدهند آیتمها را نامگذاری کنید؛ کلمه کلیدی use که مسیر را به محدوده وارد میکند؛ و کلمه کلیدی pub برای عمومی کردن آیتمها. همچنین درباره کلمه کلیدی as، بستههای خارجی، و عملگر glob صحبت خواهیم کرد.
خلاصهای از ماژولها
قبل از اینکه به جزئیات ماژولها و مسیرها بپردازیم، اینجا یک مرجع سریع در مورد نحوه عملکرد ماژولها، مسیرها، کلمه کلیدی use و کلمه کلیدی pub در کامپایلر ارائه میدهیم و همچنین نحوه سازماندهی کد توسط اکثر توسعهدهندگان را نشان میدهیم. ما در طول این فصل به مثالهایی از هر یک از این قواعد خواهیم پرداخت، اما این یک مکان عالی برای یادآوری نحوه عملکرد ماژولها است.
- شروع از ریشه جعبه (crate): هنگام کامپایل یک جعبه (crate)، کامپایلر ابتدا در فایل ریشه جعبه (crate) (معمولاً src/lib.rs برای یک جعبه (crate) کتابخانهای یا src/main.rs برای یک جعبه (crate) باینری) به دنبال کد برای کامپایل میگردد.
- تعریف ماژولها: در فایل ریشه جعبه (crate)، میتوانید ماژولهای جدید تعریف کنید؛ مثلاً میتوانید یک ماژول “garden” با
mod garden;تعریف کنید. کامپایلر کد ماژول را در مکانهای زیر جستجو میکند:- به صورت درونخطی، داخل براکتهای موجدار که به جای علامت نقطهویرگول بعد از
mod gardenقرار میگیرند. - در فایل src/garden.rs
- در فایل src/garden/mod.rs
- به صورت درونخطی، داخل براکتهای موجدار که به جای علامت نقطهویرگول بعد از
- تعریف زیرماژولها: در هر فایلی به جز فایل ریشه جعبه (crate)، میتوانید زیرماژولها تعریف کنید. برای مثال، ممکن است
mod vegetables;را در فایل src/garden.rs تعریف کنید. کامپایلر کد زیرماژول را در دایرکتوریای که به نام ماژول والد است، در مکانهای زیر جستجو میکند:- به صورت درونخطی، مستقیماً بعد از
mod vegetables، داخل براکتهای موجدار به جای نقطهویرگول - در فایل src/garden/vegetables.rs
- در فایل src/garden/vegetables/mod.rs
- به صورت درونخطی، مستقیماً بعد از
- مسیرها به کد در ماژولها: وقتی یک ماژول بخشی از جعبه (crate) شما باشد، میتوانید از هر جای دیگر در همان جعبه (crate) (تا زمانی که قواعد حریم خصوصی اجازه دهند) با استفاده از مسیر به کد آن ارجاع دهید. برای مثال، یک نوع
Asparagusدر ماژول vegetables در garden به این صورت پیدا میشود:crate::garden::vegetables::Asparagus. - خصوصی در مقابل عمومی: کد درون یک ماژول به صورت پیشفرض برای ماژولهای والد خصوصی است. برای عمومی کردن یک ماژول، آن را با
pub modبه جایmodتعریف کنید. برای عمومی کردن آیتمهای داخل یک ماژول عمومی، ازpubقبل از اعلان آنها استفاده کنید. - کلمه کلیدی
use: در یک محدوده، کلمه کلیدیuseمیانبری به آیتمها ایجاد میکند تا تکرار مسیرهای طولانی کاهش یابد. در هر محدودهای که میتواند بهcrate::garden::vegetables::Asparagusارجاع دهد، میتوانید یک میانبر باuse crate::garden::vegetables::Asparagus;ایجاد کنید و از آن به بعد فقط کافی استAsparagusرا در آن محدوده استفاده کنید.
اینجا، ما یک جعبه (crate) باینری به نام backyard ایجاد میکنیم که این قواعد را نشان میدهد. دایرکتوری جعبه (crate) که آن هم backyard نامیده میشود شامل این فایلها و دایرکتوریها است:
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
فایل ریشه جعبه (crate) در اینجا src/main.rs است و حاوی موارد زیر است:
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {plant:?}!");
}خط pub mod garden; به کامپایلر میگوید که کدی را که در src/garden.rs پیدا میکند وارد کند، که شامل موارد زیر است:
pub mod vegetables;اینجا، pub mod vegetables; به این معنا است که کد موجود در src/garden/vegetables.rs نیز وارد میشود. آن کد به صورت زیر است:
#[derive(Debug)]
pub struct Asparagus {}حالا بیایید به جزئیات این قواعد بپردازیم و آنها را در عمل نشان دهیم!
گروهبندی کدهای مرتبط در ماژولها
ماژولها به ما امکان میدهند کد را در یک جعبه (crate) برای خوانایی و بازاستفاده آسان سازماندهی کنیم. ماژولها همچنین به ما امکان کنترل حریم خصوصی آیتمها را میدهند زیرا کد درون یک ماژول به صورت پیشفرض خصوصی است. آیتمهای خصوصی جزئیات پیادهسازی داخلی هستند که برای استفاده خارجی در دسترس نیستند. ما میتوانیم انتخاب کنیم که ماژولها و آیتمهای درون آنها عمومی باشند، که این موارد را برای استفاده خارجی آشکار میکند.
برای مثال، بیایید یک جعبه (crate) کتابخانهای بنویسیم که عملکرد یک رستوران را ارائه دهد. امضای توابع را تعریف میکنیم اما بدنه آنها را خالی میگذاریم تا بیشتر بر سازماندهی کد تمرکز کنیم تا پیادهسازی عملکرد یک رستوران.
در صنعت رستوران، برخی قسمتهای یک رستوران به عنوان جلوی خانه و دیگر قسمتها به عنوان پشت خانه شناخته میشوند. جلوی خانه جایی است که مشتریان هستند؛ این شامل جایی است که میزبانها مشتریان را مینشانند، گارسونها سفارش میگیرند و پرداختها را انجام میدهند، و بارتندرها نوشیدنی درست میکنند. پشت خانه جایی است که سرآشپزها و آشپزها در آشپزخانه کار میکنند، ظرفشورها ظروف را تمیز میکنند، و مدیران کارهای اداری انجام میدهند.
برای ساختاردهی جعبه (crate) خود به این روش، میتوانیم عملکردها را در ماژولهای تو در تو سازماندهی کنیم. یک کتابخانه جدید به نام restaurant با اجرای دستور cargo new restaurant --lib ایجاد کنید. سپس کد لیستینگ 7-1 را در src/lib.rs وارد کنید تا برخی ماژولها و امضای توابع تعریف شود. این کد بخش جلوی خانه را تعریف میکند.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}front_of_house که شامل ماژولهای دیگر است که سپس شامل توابع میشوندماژولی را با استفاده از کلیدواژهی mod و بهدنبال آن نام ماژول تعریف میکنیم
(در این مثال، front_of_house). بدنهی ماژول درون آکولاد قرار میگیرد.
درون ماژولها میتوان ماژولهای دیگری نیز قرار داد، همانطور که در این مثال،
ماژولهای hosting و serving درون front_of_house قرار گرفتهاند.
ماژولها همچنین میتوانند شامل تعریف آیتمهای دیگر نیز باشند،
مانند structها، enumها، ثابتها (constants)، traitها،
و همانطور که در لیستینگ 7-1 میبینید، توابع.
با استفاده از ماژولها، میتوانیم تعاریف مرتبط را با هم گروهبندی کنیم و دلیل ارتباط آنها را نامگذاری کنیم. برنامهنویسانی که از این کد استفاده میکنند میتوانند بر اساس گروهها کد را مرور کنند، به جای اینکه مجبور باشند تمام تعاریف را بخوانند. این کار پیدا کردن تعاریف مرتبط با آنها را آسانتر میکند. برنامهنویسانی که عملکرد جدیدی به این کد اضافه میکنند میدانند که کد را کجا قرار دهند تا برنامه سازماندهی شده باقی بماند.
درخت ماژول
قبلاً اشاره کردیم که src/main.rs و src/lib.rs به نام ریشه جعبه (crate) شناخته میشوند. دلیل نامگذاری آنها این است که محتوای هر یک از این دو فایل یک ماژول به نام crate را در ریشه ساختار ماژول جعبه (crate) تشکیل میدهند، که به عنوان درخت ماژول شناخته میشود.
لیستینگ 7-2 درخت ماژول را برای ساختار موجود در لیستینگ 7-1 نشان میدهد.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
این درخت نشان میدهد که برخی از ماژولها در داخل ماژولهای دیگر قرار دارند؛ برای مثال، hosting در داخل front_of_house قرار دارد. درخت همچنین نشان میدهد که برخی از ماژولها همسطح هستند، به این معنی که در همان ماژول تعریف شدهاند؛ hosting و serving همسطح هستند و درون front_of_house تعریف شدهاند. اگر ماژول A درون ماژول B قرار گیرد، میگوییم ماژول A فرزند ماژول B است و ماژول B والد ماژول A است. توجه کنید که کل درخت ماژول در زیر ماژول ضمنی به نام crate ریشه دارد.
درخت ماژول ممکن است شما را به یاد درخت دایرکتوریهای فایلسیستم کامپیوتر بیندازد؛ این مقایسه بسیار مناسبی است! درست همانطور که دایرکتوریها در فایلسیستم کد را سازماندهی میکنند، شما میتوانید از ماژولها برای سازماندهی کد خود استفاده کنید. و درست مانند فایلها در یک دایرکتوری، ما نیاز به روشی برای پیدا کردن ماژولها داریم.
مسیرها برای اشاره به یک آیتم در درخت ماژول
برای نشان دادن به Rust که یک آیتم را در درخت ماژول کجا پیدا کند، از یک مسیر استفاده میکنیم، مشابه استفاده از مسیر هنگام پیمایش در یک فایلسیستم. برای فراخوانی یک تابع، باید مسیر آن را بدانیم.
یک مسیر میتواند به دو شکل باشد:
- یک مسیر مطلق مسیری کامل است که از ریشه جعبه (crate) شروع میشود؛ برای کدی که از یک جعبه (crate) خارجی میآید، مسیر مطلق با نام جعبه (crate) شروع میشود، و برای کدی که از جعبه (crate) فعلی میآید، با کلمه کلیدی
crateشروع میشود. - یک مسیر نسبی از ماژول فعلی شروع میشود و از
self،superیا یک شناسه در ماژول فعلی استفاده میکند.
هر دو مسیر مطلق و نسبی با یک یا چند شناسه که با دو نقطه دوبل (::) جدا شدهاند دنبال میشوند.
با بازگشت به لیستینگ 7-1، فرض کنید که میخواهیم تابع add_to_waitlist را فراخوانی کنیم. این کار مشابه پرسیدن این است: مسیر تابع add_to_waitlist چیست؟ لیستینگ 7-3 شامل لیستینگ 7-1 با حذف برخی از ماژولها و توابع است.
ما دو روش برای فراخوانی تابع add_to_waitlist از یک تابع جدید، eat_at_restaurant، که در ریشه جعبه (crate) تعریف شده است، نشان خواهیم داد. این مسیرها درست هستند، اما یک مشکل دیگر وجود دارد که مانع کامپایل این مثال به شکل فعلی میشود. بعداً توضیح خواهیم داد که چرا.
تابع eat_at_restaurant بخشی از API عمومی جعبه (crate) کتابخانهای ما است، بنابراین آن را با کلمه کلیدی pub علامت میزنیم. در بخش «آشکار کردن مسیرها با کلمه کلیدی pub»، به جزئیات بیشتری درباره pub خواهیم پرداخت.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}add_to_waitlist با استفاده از مسیرهای مطلق و نسبیبار اولی که تابع add_to_waitlist را در eat_at_restaurant فراخوانی میکنیم، از یک مسیر مطلق استفاده میکنیم. تابع add_to_waitlist در همان جعبه (crate) تعریف شده است که eat_at_restaurant در آن قرار دارد، که به این معنی است که میتوانیم از کلمه کلیدی crate برای شروع مسیر مطلق استفاده کنیم. سپس هر یک از ماژولهای متوالی را شامل میکنیم تا به add_to_waitlist برسیم. میتوانید یک فایلسیستم با ساختار مشابه تصور کنید: ما مسیر /front_of_house/hosting/add_to_waitlist را برای اجرای برنامه add_to_waitlist مشخص میکنیم؛ استفاده از نام crate برای شروع از ریشه جعبه (crate) مانند استفاده از / برای شروع از ریشه فایلسیستم در شل است.
بار دوم که تابع add_to_waitlist را در eat_at_restaurant فراخوانی میکنیم، از یک مسیر نسبی استفاده میکنیم. مسیر با front_of_house شروع میشود، که نام ماژولی است که در همان سطح از درخت ماژول به عنوان eat_at_restaurant تعریف شده است. اینجا معادل فایلسیستم استفاده از مسیر front_of_house/hosting/add_to_waitlist است. شروع با نام ماژول به این معنی است که مسیر نسبی است.
انتخاب بین مسیرهای مطلق و نسبی
انتخاب بین استفاده از مسیر نسبی یا مطلق یک تصمیم است که بر اساس پروژه شما گرفته میشود، و به این بستگی دارد که آیا احتمال بیشتری دارد کد تعریف آیتم را به طور مستقل از یا همراه با کدی که از آیتم استفاده میکند جابجا کنید. برای مثال، اگر ماژول front_of_house و تابع eat_at_restaurant را به یک ماژول به نام customer_experience منتقل کنیم، باید مسیر مطلق به add_to_waitlist را بهروزرسانی کنیم، اما مسیر نسبی همچنان معتبر خواهد بود. با این حال، اگر تابع eat_at_restaurant را به طور مستقل به یک ماژول به نام dining منتقل کنیم، مسیر مطلق به فراخوانی add_to_waitlist تغییر نمیکند، اما مسیر نسبی باید بهروزرسانی شود. ترجیح ما به طور کلی این است که مسیرهای مطلق را مشخص کنیم زیرا احتمال بیشتری دارد که بخواهیم تعریف کد و فراخوانی آیتمها را مستقل از یکدیگر جابجا کنیم.
بیایید سعی کنیم کد لیستینگ 7-3 را کامپایل کنیم و ببینیم چرا هنوز کامپایل نمیشود! خطاهایی که دریافت میکنیم در لیستینگ 7-4 نشان داده شدهاند.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
پیامهای خطا میگویند که ماژول hosting خصوصی است. به عبارت دیگر، ما مسیرهای صحیح برای ماژول hosting و تابع add_to_waitlist داریم، اما Rust به ما اجازه نمیدهد از آنها استفاده کنیم زیرا به بخشهای خصوصی دسترسی ندارد. در Rust، تمام آیتمها (توابع، متدها، ساختارها، enumها، ماژولها و ثابتها) به صورت پیشفرض برای ماژولهای والد خصوصی هستند. اگر بخواهید آیتمی مانند یک تابع یا ساختار را خصوصی کنید، آن را در یک ماژول قرار میدهید.
آیتمهای موجود در یک ماژول والد نمیتوانند از آیتمهای خصوصی درون ماژولهای فرزند استفاده کنند، اما آیتمهای درون ماژولهای فرزند میتوانند از آیتمهای ماژولهای اجداد خود استفاده کنند. این به این دلیل است که ماژولهای فرزند جزئیات پیادهسازی خود را بستهبندی و پنهان میکنند، اما ماژولهای فرزند میتوانند زمینهای که در آن تعریف شدهاند را ببینند. برای ادامه مثال، قواعد حریم خصوصی را مانند دفتر پشتی یک رستوران تصور کنید: آنچه در آنجا میگذرد برای مشتریان رستوران خصوصی است، اما مدیران دفتر میتوانند همه چیز را در رستوران ببینند و انجام دهند.
Rust تصمیم گرفته است که سیستم ماژول به این صورت کار کند تا پنهان کردن جزئیات پیادهسازی داخلی به صورت پیشفرض باشد. به این ترتیب، میدانید کدام بخشهای کد داخلی را میتوانید تغییر دهید بدون اینکه کد بیرونی را خراب کنید. با این حال، Rust به شما این امکان را میدهد که بخشهای داخلی کد ماژولهای فرزند را به ماژولهای اجداد بیرونی با استفاده از کلمه کلیدی pub عمومی کنید.
آشکار کردن مسیرها با کلمه کلیدی pub
بیایید به خطای لیستینگ 7-4 برگردیم که به ما گفت ماژول hosting خصوصی است. ما میخواهیم تابع eat_at_restaurant در ماژول والد به تابع add_to_waitlist در ماژول فرزند دسترسی داشته باشد، بنابراین ماژول hosting را با کلمه کلیدی pub علامت میزنیم، همانطور که در لیستینگ 7-5 نشان داده شده است.
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}hosting به عنوان pub برای استفاده از آن در eat_at_restaurantمتأسفانه، کد در لیستینگ 7-5 همچنان به خطاهای کامپایلر منجر میشود، همانطور که در لیستینگ 7-6 نشان داده شده است.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
چه اتفاقی افتاد؟ اضافه کردن کلمه کلیدی pub در جلوی mod hosting ماژول را عمومی میکند. با این تغییر، اگر به front_of_house دسترسی داشته باشیم، میتوانیم به hosting نیز دسترسی داشته باشیم. اما محتویات hosting همچنان خصوصی است؛ عمومی کردن ماژول به معنای عمومی کردن محتوای آن نیست. کلمه کلیدی pub روی یک ماژول فقط به کدهای موجود در ماژولهای اجداد اجازه میدهد به آن ارجاع دهند، نه اینکه به کد داخلی آن دسترسی داشته باشند. از آنجایی که ماژولها به عنوان ظرف عمل میکنند، تنها عمومی کردن ماژول کافی نیست؛ باید فراتر رفته و یک یا چند مورد از آیتمهای درون ماژول را نیز عمومی کنیم.
خطاهای موجود در لیستینگ 7-6 نشان میدهند که تابع add_to_waitlist خصوصی است. قواعد حریم خصوصی برای ساختارها، enumها، توابع، متدها و همچنین ماژولها اعمال میشوند.
بیایید تابع add_to_waitlist را نیز با اضافه کردن کلمه کلیدی pub قبل از تعریف آن عمومی کنیم، همانطور که در لیستینگ 7-7 نشان داده شده است.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}pub به mod hosting و fn add_to_waitlist به ما اجازه میدهد تابع را از eat_at_restaurant فراخوانی کنیمNow the code will compile! To see why adding the pub keyword lets us use
these paths in eat_at_restaurant with respect to the privacy rules, let’s look
at the absolute and the relative paths.
In the absolute path, we start with crate, the root of our crate’s module
tree. The front_of_house module is defined in the crate root. While
front_of_house isn’t public, because the eat_at_restaurant function is
defined in the same module as front_of_house (that is, eat_at_restaurant
and front_of_house are siblings), we can refer to front_of_house from
eat_at_restaurant. Next is the hosting module marked with pub. We can
access the parent module of hosting, so we can access hosting. Finally, the
add_to_waitlist function is marked with pub and we can access its parent
module, so this function call works!
In the relative path, the logic is the same as the absolute path except for the
first step: rather than starting from the crate root, the path starts from
front_of_house. The front_of_house module is defined within the same module
as eat_at_restaurant, so the relative path starting from the module in which
eat_at_restaurant is defined works. Then, because hosting and
add_to_waitlist are marked with pub, the rest of the path works, and this
function call is valid!
If you plan on sharing your library crate so other projects can use your code, your public API is your contract with users of your crate that determines how they can interact with your code. There are many considerations around managing changes to your public API to make it easier for people to depend on your crate. These considerations are out of the scope of this book; if you’re interested in this topic, see The Rust API Guidelines.
بهترین شیوهها برای بستههایی که یک جعبه (crate) باینری و یک جعبه (crate) کتابخانهای دارند
We mentioned that a package can contain both a src/main.rs binary crate root as well as a src/lib.rs library crate root, and both crates will have the package name by default. Typically, packages with this pattern of containing both a library and a binary crate will have just enough code in the binary crate to start an executable that calls code within the library crate. This lets other projects benefit from most of the functionality that the package provides because the library crate’s code can be shared.
درخت ماژول باید در src/lib.rs تعریف شود. سپس، هر آیتم عمومی را میتوان در جعبه (crate) باینری با شروع مسیرها با نام بسته استفاده کرد. جعبه (crate) باینری به یک کاربر از جعبه (crate) کتابخانهای تبدیل میشود، درست مثل اینکه یک جعبه (crate) کاملاً خارجی از جعبه (crate) کتابخانهای استفاده میکند: تنها میتواند از API عمومی استفاده کند. این کار به شما کمک میکند یک API خوب طراحی کنید؛ نه تنها نویسنده آن هستید، بلکه یک کاربر نیز هستید!
In Chapter 12, we’ll demonstrate this organizational practice with a command-line program that will contain both a binary crate and a library crate.
Starting Relative Paths with super
We can construct relative paths that begin in the parent module, rather than
the current module or the crate root, by using super at the start of the
path. This is like starting a filesystem path with the .. syntax. Using
super allows us to reference an item that we know is in the parent module,
which can make rearranging the module tree easier when the module is closely
related to the parent but the parent might be moved elsewhere in the module
tree someday.
Consider the code in Listing 7-8 that models the situation in which a chef
fixes an incorrect order and personally brings it out to the customer. The
function fix_incorrect_order defined in the back_of_house module calls the
function deliver_order defined in the parent module by specifying the path to
deliver_order, starting with super.
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}super شروع میشودتابع fix_incorrect_order در ماژول back_of_house است، بنابراین میتوانیم از super برای رفتن به ماژول والد back_of_house استفاده کنیم، که در این مورد crate، یعنی ریشه است. از آنجا به دنبال deliver_order میگردیم و آن را پیدا میکنیم. موفقیت! ما فکر میکنیم که ماژول back_of_house و تابع deliver_order احتمالاً در همان رابطه با یکدیگر باقی میمانند و اگر بخواهیم درخت ماژول جعبه (crate) را سازماندهی مجدد کنیم، با هم جابجا میشوند. بنابراین، از super استفاده کردیم تا در آینده، اگر این کد به ماژول دیگری منتقل شد، تغییرات کمتری در کد لازم باشد.
عمومی کردن ساختارها و enumها
ما همچنین میتوانیم از pub برای مشخص کردن ساختارها و enumها به عنوان عمومی استفاده کنیم، اما چند جزئیات اضافی در مورد استفاده از pub با ساختارها و enumها وجود دارد. اگر از pub قبل از تعریف یک ساختار استفاده کنیم، ساختار عمومی میشود، اما فیلدهای ساختار همچنان خصوصی خواهند بود. ما میتوانیم هر فیلد را به صورت موردی عمومی یا خصوصی کنیم. در لیستینگ 7-9، یک ساختار عمومی به نام back_of_house::Breakfast تعریف کردهایم که یک فیلد عمومی به نام toast دارد اما فیلد seasonal_fruit خصوصی است. این مدلسازی حالتی است که در آن مشتری میتواند نوع نان همراه با وعده غذایی را انتخاب کند، اما سرآشپز تصمیم میگیرد که کدام میوه همراه وعده غذایی باشد بر اساس آنچه در فصل و موجودی است. میوههای موجود به سرعت تغییر میکنند، بنابراین مشتریان نمیتوانند میوه را انتخاب کنند یا حتی ببینند که چه میوهای دریافت خواهند کرد.
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like.
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compile if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal.
// meal.seasonal_fruit = String::from("blueberries");
}از آنجا که فیلد toast در ساختار back_of_house::Breakfast عمومی است، میتوانیم در eat_at_restaurant به این فیلد با استفاده از نقطهگذاری مقدار بدهیم یا مقدار آن را بخوانیم. توجه کنید که نمیتوانیم از فیلد seasonal_fruit در eat_at_restaurant استفاده کنیم، زیرا seasonal_fruit خصوصی است. خطی که مقدار فیلد seasonal_fruit را تغییر میدهد را لغو کامنت کنید تا ببینید چه خطایی دریافت میکنید!
همچنین توجه کنید که چون back_of_house::Breakfast یک فیلد خصوصی دارد، ساختار باید یک تابع وابسته عمومی ارائه دهد که یک نمونه از Breakfast بسازد (ما آن را اینجا summer نامیدهایم). اگر Breakfast چنین تابعی نداشت، نمیتوانستیم یک نمونه از Breakfast را در eat_at_restaurant ایجاد کنیم، زیرا نمیتوانستیم مقدار فیلد خصوصی seasonal_fruit را در eat_at_restaurant تنظیم کنیم.
در مقابل، اگر یک enum را عمومی کنیم، تمام متغیرهای آن نیز عمومی میشوند. ما فقط به pub قبل از کلمه کلیدی enum نیاز داریم، همانطور که در لیستینگ 7-10 نشان داده شده است.
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}از آنجایی که enum Appetizer را عمومی کردیم، میتوانیم از متغیرهای Soup و Salad در eat_at_restaurant استفاده کنیم.
Enums خیلی مفید نیستند مگر اینکه متغیرهای آنها عمومی باشند؛ اضافه کردن pub به تمام متغیرهای enum در هر مورد کار خستهکنندهای خواهد بود، بنابراین به طور پیشفرض متغیرهای enum عمومی هستند. ساختارها اغلب بدون عمومی بودن فیلدهایشان مفید هستند، بنابراین فیلدهای ساختار از قانون کلی پیروی میکنند که همه چیز به صورت پیشفرض خصوصی است مگر اینکه با pub مشخص شود.
یک وضعیت دیگر مرتبط با pub وجود دارد که هنوز آن را پوشش ندادهایم، و آن آخرین ویژگی سیستم ماژول ما است: کلمه کلیدی use. ابتدا use را به تنهایی بررسی خواهیم کرد، و سپس نشان خواهیم داد چگونه pub و use را ترکیب کنیم.
وارد کردن مسیرها به محدوده با کلمه کلیدی use
نوشتن مسیرهای کامل برای فراخوانی توابع میتواند خستهکننده و تکراری باشد. در لیستینگ 7-7، چه مسیر مطلق یا نسبی را برای تابع add_to_waitlist انتخاب کنیم، هر بار که بخواهیم این تابع را فراخوانی کنیم باید front_of_house و hosting را نیز مشخص کنیم. خوشبختانه، راهی برای سادهتر کردن این فرآیند وجود دارد: میتوانیم یک میانبر به یک مسیر با استفاده از کلمه کلیدی use ایجاد کنیم و سپس در هر جای دیگر محدوده، از نام کوتاهتر استفاده کنیم.
در لیستینگ 7-11، ماژول crate::front_of_house::hosting را به محدوده تابع eat_at_restaurant میآوریم تا فقط نیاز به مشخص کردن hosting::add_to_waitlist برای فراخوانی تابع add_to_waitlist در eat_at_restaurant داشته باشیم.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}useاضافه کردن use و یک مسیر در یک محدوده مشابه ایجاد یک لینک نمادین در فایلسیستم است. با اضافه کردن use crate::front_of_house::hosting در ریشه جعبه (crate)، hosting اکنون یک نام معتبر در آن محدوده است، درست مانند اینکه ماژول hosting در ریشه جعبه (crate) تعریف شده باشد. مسیرهایی که با use به محدوده آورده میشوند مانند هر مسیر دیگری حریم خصوصی را بررسی میکنند.
توجه کنید که use فقط میانبر را برای محدوده خاصی که در آن use استفاده شده ایجاد میکند. لیستینگ 7-12 تابع eat_at_restaurant را به یک زیرماژول جدید به نام customer منتقل میکند که سپس یک محدوده متفاوت از دستور use است، بنابراین بدنه تابع کامپایل نمیشود.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}use تنها در همان حوزهای (scope) اعمال میشود که در آن قرار داردخطای کامپایلر نشان میدهد که میانبر دیگر در ماژول customer اعمال نمیشود:
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of undeclared crate or module `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of undeclared crate or module `hosting`
|
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
توجه کنید که همچنین یک هشدار وجود دارد که use دیگر در محدوده خود استفاده نمیشود! برای رفع این مشکل، دستور use را نیز به داخل ماژول customer منتقل کنید، یا میانبر را در ماژول والد با super::hosting در داخل ماژول customer ارجاع دهید.
ایجاد مسیرهای use به صورت ایدیوماتیک
در لیستینگ 7-11، ممکن است این سوال پیش بیاید که چرا ما use crate::front_of_house::hosting را مشخص کردهایم و سپس hosting::add_to_waitlist را در eat_at_restaurant فراخوانی کردهایم، به جای اینکه مسیر use را تا تابع add_to_waitlist مشخص کنیم تا همان نتیجه را به دست آوریم، همانطور که در لیستینگ 7-13 نشان داده شده است.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}add_to_waitlist به محدوده با use که غیر ایدیوماتیک استاگرچه هم لیستینگ 7-11 و هم لیستینگ 7-13 کار مشابهی انجام میدهند، لیستینگ 7-11 روش ایدیوماتیک برای وارد کردن یک تابع به محدوده با use است. وارد کردن ماژول والد تابع با use به این معنا است که باید ماژول والد را هنگام فراخوانی تابع مشخص کنیم. مشخص کردن ماژول والد هنگام فراخوانی تابع نشان میدهد که تابع به صورت محلی تعریف نشده است، در حالی که همچنان تکرار مسیر کامل را به حداقل میرساند. کد موجود در لیستینگ 7-13 مشخص نمیکند که add_to_waitlist کجا تعریف شده است.
از طرف دیگر، وقتی ساختارها، enumها، و سایر آیتمها را با use وارد میکنیم، ایدیوماتیک است که مسیر کامل را مشخص کنیم. لیستینگ 7-14 روش ایدیوماتیک برای وارد کردن ساختار HashMap از کتابخانه استاندارد به محدوده جعبه (crate) باینری را نشان میدهد.
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
HashMap به محدوده به روش ایدیوماتیکهیچ دلیل قوی پشت این عرف نیست: این فقط کنوانسیونی است که در جامعه Rust به وجود آمده و افراد به خواندن و نوشتن کد Rust به این روش عادت کردهاند.
استثنای این عرف زمانی است که دو آیتم با نام یکسان را با دستورات use وارد محدوده میکنیم، زیرا Rust این اجازه را نمیدهد. لیستینگ 7-15 نشان میدهد که چگونه دو نوع Result را که نام یکسانی دارند اما از ماژولهای والد متفاوتی میآیند وارد محدوده کنیم و چگونه به آنها ارجاع دهیم.
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}همانطور که میبینید، استفاده از ماژولهای والد دو نوع Result را از هم متمایز میکند. اگر به جای آن use std::fmt::Result و use std::io::Result مشخص کنیم، دو نوع Result در یک محدوده خواهیم داشت و Rust نمیتواند بفهمد منظور ما از Result کدام است.
ارائه نامهای جدید با کلمه کلیدی as
یک راهحل دیگر برای مشکل وارد کردن دو نوع با نام یکسان به یک محدوده با use این است که پس از مسیر، با استفاده از as یک نام محلی جدید یا نام مستعار برای نوع مشخص کنیم. لیستینگ 7-16 راه دیگری برای نوشتن کد در لیستینگ 7-15 را نشان میدهد که در آن یکی از دو نوع Result را با استفاده از as تغییر نام دادهایم.
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}asدر دستور دوم use، ما نام جدید IoResult را برای نوع std::io::Result انتخاب کردیم، که با نوع Result از std::fmt که آن را نیز وارد محدوده کردهایم، تضاد نخواهد داشت. هر دو لیستینگ 7-15 و 7-16 ایدیوماتیک در نظر گرفته میشوند، بنابراین انتخاب با شماست!
دوباره صادر کردن نامها با pub use
وقتی با استفاده از کلیدواژهی use یک نام را وارد حوزهای میکنیم،
آن نام تنها در همان حوزه خصوصی است که در آن وارد شده است.
برای اینکه کد خارج از آن حوزه نیز بتواند به آن نام دسترسی داشته باشد،
انگار که در همان حوزه تعریف شده است، میتوانیم pub و use را با هم ترکیب کنیم.
این تکنیک re-exporting نامیده میشود، زیرا در حالی که یک آیتم را وارد حوزه میکنیم،
همزمان آن را برای دیگران نیز قابل دسترس میکنیم تا بتوانند آن را وارد حوزهی خود کنند.
لیستینگ 7-17 کد موجود در لیستینگ 7-11 را با تغییر دستور use در ماژول ریشه به pub use نشان میدهد.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}pub useقبل از این تغییر، کد خارجی باید تابع add_to_waitlist را با استفاده از مسیر restaurant::front_of_house::hosting::add_to_waitlist() فراخوانی میکرد، که همچنین نیاز داشت ماژول front_of_house به عنوان pub علامتگذاری شود. حالا که این pub use ماژول hosting را از ماژول ریشه دوباره صادر کرده است، کد خارجی میتواند از مسیر restaurant::hosting::add_to_waitlist() استفاده کند.
Re-exporting زمانی مفید است که ساختار داخلی کد شما با نحوهی تفکر برنامهنویسانی که از کد شما استفاده میکنند دربارهی دامنه، متفاوت باشد.
برای مثال، در این تمثیل رستوران، کسانی که رستوران را اداره میکنند دربارهی «بخش جلویی» (front of house) و «بخش پشتی» (back of house) فکر میکنند.
اما مشتریانی که به رستوران میآیند احتمالاً دربارهی قسمتهای رستوران با چنین اصطلاحاتی فکر نمیکنند.
با استفاده از pub use میتوانیم کد خود را با یک ساختار بنویسیم ولی ساختاری متفاوت را در معرض استفاده قرار دهیم.
این کار باعث میشود کتابخانهی ما هم برای برنامهنویسانی که روی کتابخانه کار میکنند و هم برای برنامهنویسانی که از آن استفاده میکنند، بهخوبی سازماندهی شده باشد.
در فصل ۱۴، در بخش “صادرات یک API عمومی راحت با استفاده از pub use”،
مثال دیگری از pub use و تأثیر آن بر مستندات crate شما را بررسی خواهیم کرد.
استفاده از بستههای خارجی
در فصل ۲، ما یک پروژه بازی حدسزنی برنامهریزی کردیم که از یک بسته خارجی به نام rand برای تولید اعداد تصادفی استفاده میکرد. برای استفاده از rand در پروژه خود، این خط را به Cargo.toml اضافه کردیم:
rand = "0.8.5"
اضافه کردن rand به عنوان یک وابستگی در Cargo.toml به Cargo میگوید که بسته rand و هرگونه وابستگی را از crates.io دانلود کرده و rand را در پروژه ما در دسترس قرار دهد.
سپس، برای وارد کردن تعاریف crate rand به حوزهی پکیج خود،
یک خط use اضافه کردیم که با نام crate، یعنی rand، آغاز شد
و آیتمهایی را که میخواستیم وارد حوزه کنیم، فهرست کردیم.
به یاد داشته باشید که در بخش “تولید یک عدد تصادفی” در فصل ۲،
trait مربوط به Rng را وارد حوزه کردیم و تابع rand::thread_rng را فراخوانی نمودیم:
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}اعضای جامعه Rust بسیاری از بستهها را در crates.io به اشتراک گذاشتهاند، و وارد کردن هر یک از آنها به بسته شما شامل این مراحل است: فهرست کردن آنها در فایل Cargo.toml بسته شما و استفاده از use برای وارد کردن آیتمها از جعبه (crate) آنها به محدوده.
توجه داشته باشید که کتابخانه استاندارد std نیز یک جعبه (crate) خارجی برای بسته ما است. از آنجا که کتابخانه استاندارد همراه با زبان Rust ارائه میشود، نیازی به تغییر Cargo.toml برای گنجاندن std نداریم. اما برای وارد کردن آیتمها از آن به محدوده بسته خود، باید به آن با use ارجاع دهیم. برای مثال، با HashMap از این خط استفاده میکردیم:
#![allow(unused)] fn main() { use std::collections::HashMap; }
این یک مسیر مطلق است که با std، نام جعبه (crate) کتابخانه استاندارد، شروع میشود.
استفاده از مسیرهای تو در تو برای سادهسازی لیستهای بزرگ use
اگر از چندین آیتم تعریفشده در یک جعبه (crate) یا ماژول استفاده کنیم، فهرست کردن هر آیتم در خط خود میتواند فضای عمودی زیادی در فایلهای ما اشغال کند. برای مثال، این دو دستور use که در بازی حدسزنی در لیستینگ ۲-۴ استفاده کردیم آیتمهایی از std را به محدوده میآورند:
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}در عوض، میتوانیم از مسیرهای تو در تو استفاده کنیم تا همان آیتمها را در یک خط به محدوده بیاوریم. این کار را با مشخص کردن بخش مشترک مسیر، به دنبال آن دو نقطه دوبل و سپس یک لیست از بخشهای متفاوت مسیرها در داخل آکولاد انجام میدهیم، همانطور که در لیستینگ 7-18 نشان داده شده است.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}در برنامههای بزرگتر، وارد کردن بسیاری از آیتمها از یک جعبه (crate) یا ماژول مشابه با استفاده از مسیرهای تو در تو میتواند تعداد دستورات use جداگانه مورد نیاز را به طور قابلتوجهی کاهش دهد.
ما میتوانیم در هر سطحی از یک مسیر، از یک مسیر تو در تو استفاده کنیم، که این کار در مواقعی که دو دستور use دارای یک زیرمسیر مشترک هستند، مفید است. برای مثال، لیستینگ 7-19 دو دستور use را نشان میدهد: یکی که std::io را به محدوده وارد میکند و دیگری که std::io::Write را به محدوده وارد میکند.
use std::io;
use std::io::Write;use که یکی زیرمسیر دیگری استبخش مشترک این دو مسیر، std::io است که مسیر کامل اولین دستور use را تشکیل میدهد. برای ترکیب این دو مسیر به یک دستور use، میتوانیم از self در مسیر تو در تو استفاده کنیم، همانطور که در لیستینگ 7-20 نشان داده شده است.
use std::io::{self, Write};useاین خط، std::io و std::io::Write را به محدوده وارد میکند.
عملگر Glob
اگر بخواهیم تمام آیتمهای عمومی تعریفشده در یک مسیر را به محدوده وارد کنیم، میتوانیم آن مسیر را به همراه عملگر * مشخص کنیم:
#![allow(unused)] fn main() { use std::collections::*; }
این دستور use تمام آیتمهای عمومی تعریفشده در std::collections را وارد حوزهی فعلی میکند.
در استفاده از عملگر glob دقت کنید!
استفاده از glob میتواند باعث شود تشخیص اینکه چه نامهایی در حوزه هستند
و یک نام استفادهشده در برنامه از کجا آمده، دشوارتر شود.
علاوه بر این، اگر وابستگی تغییراتی در تعاریف خود ایجاد کند، آنچه شما وارد کردهاید نیز تغییر میکند،
که ممکن است هنگام بهروزرسانی وابستگی، باعث بروز خطای کامپایلر شود—
برای مثال، اگر وابستگی تعریفی با همان نامی اضافه کند که شما نیز در همان حوزه تعریف کردهاید.
عملگر glob اغلب هنگام تست برای وارد کردن تمام آیتمهای تحت تست به ماژول tests استفاده میشود؛
در فصل ۱۱ در بخش “چگونه تست بنویسیم” دربارهی آن صحبت خواهیم کرد.
همچنین، عملگر glob گاهی در قالب الگوی prelude نیز بهکار میرود؛
برای اطلاعات بیشتر دربارهی این الگو، به مستندات کتابخانهی استاندارد مراجعه کنید.
جدا کردن ماژولها به فایلهای مختلف
تا به اینجا، تمام مثالهای این فصل چندین ماژول را در یک فایل تعریف کردهاند. هنگامی که ماژولها بزرگ میشوند، ممکن است بخواهید تعریفهای آنها را به یک فایل جداگانه منتقل کنید تا کد آسانتر خوانده و مدیریت شود.
برای مثال، بیایید از کد موجود در لیستینگ 7-17 شروع کنیم که شامل چندین ماژول مرتبط با رستوران بود. ما این ماژولها را به جای تعریف در فایل ریشه جعبه (crate)، به فایلهای جداگانه منتقل میکنیم. در این مثال، فایل ریشه جعبه (crate) src/lib.rs است، اما این روش برای جعبهها (crates)ی باینری که فایل ریشه آنها src/main.rs است نیز کار میکند.
ابتدا ماژول front_of_house را به فایل خودش منتقل میکنیم. کدی که داخل آکولادهای ماژول front_of_house است را حذف کرده و فقط اعلان mod front_of_house; را باقی میگذاریم. نتیجه کد در src/lib.rs مانند لیستینگ 7-21 خواهد بود. توجه داشته باشید که این کد تا زمانی که فایل src/front_of_house.rs مطابق لیستینگ 7-22 ایجاد نشود کامپایل نخواهد شد.
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}front_of_house که بدنه آن در src/front_of_house.rs خواهد بودسپس، کدی که داخل آکولادهای ماژول front_of_house بود را به یک فایل جدید به نام src/front_of_house.rs منتقل میکنیم، همانطور که در لیستینگ 7-22 نشان داده شده است. کامپایلر میداند که باید این فایل را بررسی کند زیرا در فایل ریشه جعبه (crate) با نام front_of_house اعلان ماژول را دیده است.
pub mod hosting {
pub fn add_to_waitlist() {}
}front_of_house در src/front_of_house.rsتوجه داشته باشید که شما فقط یک بار نیاز دارید تا یک فایل را با استفاده از دستور mod در درخت ماژول خود بارگذاری کنید. وقتی کامپایلر میفهمد که فایل بخشی از پروژه است (و میفهمد که کد در کجای درخت ماژول قرار دارد به خاطر جایی که دستور mod را قرار دادهاید)، سایر فایلهای پروژه شما باید با استفاده از مسیری که به محل اعلان فایل اشاره میکند به کد بارگذاری شده ارجاع دهند، همانطور که در بخش «مسیرها برای اشاره به یک آیتم در درخت ماژول» توضیح داده شد. به عبارت دیگر، mod یک عملیات “شامل کردن” (include) نیست که ممکن است در زبانهای برنامهنویسی دیگر دیده باشید.
در مرحله بعد، ماژول hosting را به فایل خودش منتقل میکنیم. این فرآیند کمی متفاوت است زیرا hosting یک زیرماژول از front_of_house است، نه از ماژول ریشه. فایل مربوط به hosting را در یک دایرکتوری جدید قرار میدهیم که به نام والدین آن در درخت ماژول نامگذاری شده است، که در اینجا src/front_of_house است.
برای شروع انتقال hosting، فایل src/front_of_house.rs را تغییر میدهیم تا فقط شامل اعلان ماژول hosting باشد:
pub mod hosting;سپس یک دایرکتوری به نام src/front_of_house و یک فایل hosting.rs ایجاد میکنیم تا تعریفهایی که در ماژول hosting انجام شدهاند را در آن قرار دهیم:
pub fn add_to_waitlist() {}اگر به جای آن فایل hosting.rs را در دایرکتوری src قرار دهیم، کامپایلر انتظار خواهد داشت که کد hosting.rs در یک ماژول hosting که در ریشه جعبه (crate) اعلان شده باشد قرار داشته باشد، نه به عنوان یک زیرماژول از ماژول front_of_house. قوانین کامپایلر برای مشخص کردن این که کدام فایلها برای کدام ماژولها بررسی شوند، به این معناست که دایرکتوریها و فایلها با درخت ماژول مطابقت بیشتری دارند.
مسیرهای فایل جایگزین
تاکنون مسیرهای فایل ایدیوماتیک را که کامپایلر Rust استفاده میکند پوشش دادهایم، اما Rust از یک سبک قدیمیتر از مسیر فایل نیز پشتیبانی میکند. برای یک ماژول به نام front_of_house که در ریشه جعبه (crate) اعلان شده است، کامپایلر کد ماژول را در مکانهای زیر جستجو میکند:
- src/front_of_house.rs (روشی که پوشش داده شد)
- src/front_of_house/mod.rs (مسیر قدیمیتر، همچنان پشتیبانیشده)
برای یک ماژول به نام hosting که زیرماژولی از front_of_house است، کامپایلر کد ماژول را در مکانهای زیر جستجو میکند:
- src/front_of_house/hosting.rs (روشی که پوشش داده شد)
- src/front_of_house/hosting/mod.rs (مسیر قدیمیتر، همچنان پشتیبانیشده)
اگر هر دو سبک را برای یک ماژول استفاده کنید، یک خطای کامپایلر دریافت خواهید کرد. استفاده از ترکیبی از هر دو سبک برای ماژولهای مختلف در یک پروژه مجاز است، اما ممکن است برای کسانی که پروژه شما را مرور میکنند گیجکننده باشد.
نکته منفی اصلی سبک استفاده از فایلهایی با نام mod.rs این است که پروژه شما ممکن است تعداد زیادی فایل با نام mod.rs داشته باشد، که میتواند هنگام باز بودن همزمان این فایلها در ویرایشگر شما گیجکننده باشد.
ما کد هر ماژول را به یک فایل جداگانه منتقل کردهایم و درخت ماژول به همان شکل باقی مانده است. فراخوانی توابع در eat_at_restaurant بدون هیچ تغییری کار خواهد کرد، حتی اگر تعریفها در فایلهای مختلف قرار داشته باشند. این تکنیک به شما امکان میدهد ماژولها را به فایلهای جدید منتقل کنید زیرا اندازه آنها افزایش مییابد.
توجه داشته باشید که دستور pub use crate::front_of_house::hosting در src/lib.rs نیز تغییری نکرده است، و همچنین use هیچ تأثیری بر اینکه چه فایلهایی به عنوان بخشی از جعبه (crate) کامپایل شوند ندارد. کلمه کلیدی mod ماژولها را اعلان میکند و Rust در فایلی با همان نام ماژول به دنبال کدی میگردد که وارد آن ماژول شود.
خلاصه
Rust به شما اجازه میدهد یک بسته را به چندین جعبه (crate) و یک جعبه (crate) را به ماژولها تقسیم کنید تا بتوانید به آیتمهایی که در یک ماژول تعریف شدهاند از ماژول دیگری ارجاع دهید. میتوانید این کار را با مشخص کردن مسیرهای مطلق یا نسبی انجام دهید. این مسیرها میتوانند با یک دستور use به محدوده وارد شوند تا بتوانید از یک مسیر کوتاهتر برای استفادههای متعدد از آن آیتم در آن محدوده استفاده کنید. کد ماژول به صورت پیشفرض خصوصی است، اما میتوانید با افزودن کلمه کلیدی pub تعریفها را عمومی کنید.
در فصل بعدی، به برخی از ساختارهای دادهای مجموعه در کتابخانه استاندارد خواهیم پرداخت که میتوانید در کد مرتب و سازماندهیشده خود از آنها استفاده کنید.
مجموعههای معمول
کتابخانهی استاندارد Rust شامل تعدادی ساختار دادهی بسیار مفید به نام collections (مجموعهها) است.
اکثر انواع دادهی دیگر نمایانگر یک مقدار خاص هستند، اما مجموعهها میتوانند چندین مقدار را در خود نگه دارند.
بر خلاف انواع داخلی مانند array و tuple، دادههایی که این مجموعهها به آنها اشاره میکنند،
روی heap ذخیره میشوند؛ به این معنا که نیازی نیست اندازهی دادهها در زمان کامپایل مشخص باشد،
و این اندازه میتواند در طول اجرای برنامه رشد یا کاهش یابد.
هر نوع مجموعه قابلیتها و هزینههای متفاوتی دارد،
و انتخاب مجموعهی مناسب برای موقعیت فعلی، مهارتی است که با گذشت زمان به دست خواهید آورد.
در این فصل، دربارهی سه نوع مجموعه که بسیار در برنامههای Rust استفاده میشوند صحبت خواهیم کرد:
- یک بردار به شما اجازه میدهد که تعداد متغیری از مقادیر را در کنار یکدیگر ذخیره کنید.
- یک رشته یک مجموعه از کاراکترها است. ما قبلاً نوع
Stringرا ذکر کردهایم، اما در این فصل به طور عمیقتر درباره آن صحبت خواهیم کرد. - یک هش مپ به شما اجازه میدهد که یک مقدار را با یک کلید مشخص مرتبط کنید. این یک پیادهسازی خاص از ساختار داده کلیتر به نام نقشه است.
برای یادگیری درباره انواع دیگر مجموعههایی که توسط کتابخانه استاندارد ارائه شدهاند، مستندات را مشاهده کنید.
ما درباره نحوه ایجاد و بهروزرسانی بردارها، رشتهها و هش مپها، همچنین ویژگیهایی که هر کدام را خاص میکند، صحبت خواهیم کرد.
ذخیره لیستهایی از مقادیر با بردارها
اولین نوع مجموعهای که به آن خواهیم پرداخت، Vec<T> یا همان بردار است.
بردارها به شما اجازه میدهند که بیش از یک مقدار را در یک ساختار داده ذخیره کنید
که تمامی مقادیر را در کنار یکدیگر در حافظه قرار میدهد. بردارها فقط میتوانند
مقادیر از یک نوع را ذخیره کنند. این ابزار زمانی مفید است که لیستی از آیتمها
مانند خطوط متنی در یک فایل یا قیمت آیتمها در یک سبد خرید داشته باشید.
ایجاد یک بردار جدید
برای ایجاد یک بردار خالی جدید، از تابع Vec::new استفاده میکنیم، همانطور که
در لیست ۸-۱ نشان داده شده است.
fn main() { let v: Vec<i32> = Vec::new(); }
i32توجه داشته باشید که ما یک توضیح نوع اضافه کردهایم. چون ما هیچ مقداری به این بردار
اضافه نکردهایم، Rust نمیداند چه نوع عناصری را قصد داریم ذخیره کنیم. این نکته
مهمی است. بردارها با استفاده از جنریکها پیادهسازی شدهاند؛ در فصل ۱۰ خواهیم دید
که چگونه میتوان جنریکها را در انواع خودتان استفاده کرد. در حال حاضر بدانید که
نوع Vec<T> ارائه شده توسط کتابخانه استاندارد میتواند هر نوعی را نگهداری کند.
وقتی یک بردار برای نگهداری نوع خاصی ایجاد میکنیم، میتوانیم نوع موردنظر را داخل
براکتهای زاویهای مشخص کنیم. در لیست ۸-۱، ما به Rust اعلام کردهایم که بردار Vec<T>
در v عناصر نوع i32 را نگهداری خواهد کرد.
بیشتر اوقات، شما یک Vec<T> با مقادیر اولیه ایجاد خواهید کرد و Rust نوع مقادیر
را از روی آنها استنتاج خواهد کرد، بنابراین به ندرت نیاز به توضیح نوع خواهید داشت.
Rust به راحتی ماکروی vec! را فراهم میکند که یک بردار جدید ایجاد کرده و مقادیر
مورد نظر شما را در آن قرار میدهد. لیست ۸-۲ یک بردار جدید Vec<i32> را ایجاد میکند
که مقادیر 1، 2 و 3 را نگهداری میکند. نوع عدد صحیح i32 است چون این نوع
پیشفرض برای اعداد صحیح است، همانطور که در بخش “انواع دادهها”
فصل ۳ بحث کردیم.
fn main() { let v = vec![1, 2, 3]; }
چون مقادیر اولیه i32 دادهایم، Rust میتواند استنتاج کند که نوع v
Vec<i32> است و نیازی به توضیح نوع نیست. حالا به نحوه بهروزرسانی یک بردار
خواهیم پرداخت.
بهروزرسانی یک بردار
برای ایجاد یک بردار و سپس اضافه کردن عناصر به آن، میتوانیم از متد push استفاده کنیم،
همانطور که در لیست ۸-۳ نشان داده شده است.
fn main() { let mut v = Vec::new(); v.push(5); v.push(6); v.push(7); v.push(8); }
push برای اضافه کردن مقادیر به یک بردارهمانطور که با هر متغیری دیگر انجام میدهیم، اگر بخواهیم بتوانیم مقدار آن را تغییر دهیم،
باید آن را با استفاده از کلیدواژه mut قابل تغییر کنیم، همانطور که در فصل ۳ بحث شد.
اعدادی که در داخل بردار قرار میدهیم همه از نوع i32 هستند و Rust این نوع را از دادهها
استنتاج میکند، بنابراین نیازی به توضیح نوع Vec<i32> نیست.
خواندن عناصر بردار
دو روش برای ارجاع به یک مقدار ذخیره شده در بردار وجود دارد: از طریق استفاده از اندیس (index)یا
با استفاده از متد get. در مثالهای زیر، انواع مقادیر بازگشتی از این توابع برای وضوح بیشتر
مشخص شدهاند.
لیست ۸-۴ هر دو روش دسترسی به یک مقدار در بردار، با استفاده از سینتکس اندیس (index)و متد get
را نشان میدهد.
fn main() { let v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; println!("The third element is {third}"); let third: Option<&i32> = v.get(2); match third { Some(third) => println!("The third element is {third}"), None => println!("There is no third element."), } }
get برای دسترسی به یک آیتم در برداربه چند جزئیات اینجا توجه کنید. ما از مقدار اندیس (index)2 برای دسترسی به عنصر سوم استفاده میکنیم
زیرا بردارها با شماره از صفر اندیسگذاری میشوند. استفاده از & و [] یک مرجع به عنصر
در مقدار اندیس (index)را به ما میدهد. وقتی از متد get با اندیسی که به عنوان آرگومان داده میشود
استفاده میکنیم، یک Option<&T> دریافت میکنیم که میتوانیم با match از آن استفاده کنیم.
Rust این دو روش ارجاع به یک عنصر را ارائه میدهد تا بتوانید انتخاب کنید که برنامه شما چگونه رفتار کند وقتی تلاش میکنید از یک مقدار اندیس (index)خارج از محدوده عناصر موجود استفاده کنید. به عنوان یک مثال، بیایید ببینیم چه اتفاقی میافتد وقتی یک بردار با پنج عنصر داشته باشیم و سپس تلاش کنیم به یک عنصر در اندیس (index)۱۰۰ با هر دو تکنیک دسترسی پیدا کنیم، همانطور که در لیست ۸-۵ نشان داده شده است.
fn main() { let v = vec![1, 2, 3, 4, 5]; let does_not_exist = &v[100]; let does_not_exist = v.get(100); }
وقتی این کد را اجرا میکنیم، روش اول [] باعث میشود برنامه متوقف شود زیرا به یک
عنصر غیرموجود اشاره میکند. این روش زمانی بهترین استفاده را دارد که بخواهید برنامهتان
در صورت تلاش برای دسترسی به عنصری خارج از انتهای بردار، متوقف شود.
وقتی متد get یک اندیس (index)خارج از بردار دریافت میکند، مقدار None را بدون متوقف کردن
برنامه بازمیگرداند. شما از این روش استفاده میکنید اگر دسترسی به عنصری خارج از محدوده بردار
ممکن است گاهبهگاه در شرایط عادی رخ دهد. کد شما سپس منطق لازم برای مدیریت داشتن
Some(&element) یا None را خواهد داشت، همانطور که در فصل ۶ بحث شد. برای مثال،
اندیس (index)ممکن است از یک عدد ورودی توسط کاربر بیاید. اگر کاربر تصادفاً عددی وارد کند که بیش از حد
بزرگ باشد و برنامه مقدار None دریافت کند، شما میتوانید به کاربر اطلاع دهید که چند آیتم
در بردار موجود است و به او فرصت دیگری برای وارد کردن یک مقدار معتبر بدهید. این راهکار برای
کاربر پسندتر است تا این که برنامه به دلیل یک اشتباه تایپی متوقف شود!
وقتی برنامه یک مرجع معتبر دارد، بررسیکننده قرض قوانین مالکیت و قرضگیری (که در فصل ۴ پوشش داده شد) را اعمال میکند تا اطمینان حاصل کند که این مرجع و هر مرجع دیگری به محتوای بردار معتبر باقی میمانند. به یاد بیاورید که قانون بیان میکند نمیتوانید مرجعهای قابل تغییر و غیرقابل تغییر را در یک حوزه داشته باشید. این قانون در لیست ۸-۶ اعمال میشود، جایی که یک مرجع غیرقابل تغییر به اولین عنصر در یک بردار نگه داشته شده است و سعی داریم یک عنصر به انتها اضافه کنیم. این برنامه زمانی کار نخواهد کرد اگر همچنین بخواهیم بعداً در تابع به آن عنصر ارجاع دهیم.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}کامپایل کردن این کد به این خطا منجر میشود:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ------- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
کد در لیست ۸-۶ ممکن است به نظر بیاید که باید کار کند: چرا یک مرجع به اولین عنصر باید به تغییرات انتهای بردار اهمیت دهد؟ این خطا به نحوه کار بردارها مربوط است: چون بردارها مقادیر را در کنار یکدیگر در حافظه قرار میدهند، اضافه کردن یک عنصر جدید به انتهای بردار ممکن است نیازمند اختصاص حافظه جدید و کپی کردن عناصر قدیمی به مکان جدید باشد، اگر فضای کافی برای قرار دادن همه عناصر در کنار یکدیگر در محل کنونی بردار وجود نداشته باشد. در این حالت، مرجع به اولین عنصر به حافظهای اشاره میکند که آزاد شده است. قوانین قرضگیری از به وجود آمدن این شرایط در برنامهها جلوگیری میکنند.
نکته: برای اطلاعات بیشتر درباره جزئیات پیادهسازی نوع
Vec<T>، به “The Rustonomicon” مراجعه کنید.
پیمایش بر روی مقادیر در یک بردار
برای دسترسی به هر عنصر در یک بردار به ترتیب، میتوانیم به جای استفاده از اندیسها
برای دسترسی به یک عنصر در هر بار، بر روی تمامی عناصر پیمایش کنیم. لیست ۸-۷ نشان میدهد
چگونه میتوان از یک حلقه for برای گرفتن مرجعهای غیرقابل تغییر به هر عنصر در یک بردار
از مقادیر i32 استفاده کرد و آنها را چاپ کرد.
fn main() { let v = vec![100, 32, 57]; for i in &v { println!("{i}"); } }
forهمچنین میتوانیم بر روی مرجعهای قابل تغییر به هر عنصر در یک بردار قابل تغییر پیمایش کنیم
تا تغییراتی روی تمام عناصر اعمال کنیم. حلقه for در لیست ۸-۸ مقدار 50 را به هر عنصر اضافه میکند.
fn main() { let mut v = vec![100, 32, 57]; for i in &mut v { *i += 50; } }
برای تغییر مقداری که رفرنس قابلتغییر به آن اشاره میکند،
باید از عملگر * برای dereference کردن استفاده کنیم تا به مقدار درون i دسترسی پیدا کنیم
و سپس بتوانیم از عملگر += استفاده کنیم.
در بخش “دنبال کردن رفرنس تا رسیدن به مقدار” در فصل ۱۵،
بیشتر دربارهی عملگر dereference صحبت خواهیم کرد.
پیمایش بر روی یک بردار، چه به صورت غیرقابل تغییر و چه به صورت قابل تغییر، امن است
زیرا از قوانین بررسیکننده قرض پیروی میکند. اگر بخواهیم در بدنه حلقههای for در لیست ۸-۷
و لیست ۸-۸ آیتمها را درج یا حذف کنیم، با خطای کامپایل مشابهی با کدی که در لیست ۸-۶ دیدیم
روبرو خواهیم شد. مرجع به برداری که حلقه for نگه میدارد از تغییر همزمان کل بردار
جلوگیری میکند.
استفاده از Enum برای ذخیره انواع مختلف
بردارها فقط میتوانند مقادیر از یک نوع را ذخیره کنند. این موضوع ممکن است گاهی
ناخوشایند باشد؛ مطمئناً موارد استفادهای وجود دارند که نیاز به ذخیره یک لیست
از آیتمها با انواع مختلف دارید. خوشبختانه، متغیرهای یک enum تحت یک نوع
enum تعریف شدهاند، بنابراین وقتی نیاز به یک نوع برای نمایش عناصر از انواع
مختلف دارید، میتوانید یک enum تعریف کرده و از آن استفاده کنید!
برای مثال، فرض کنید میخواهیم مقادیر یک ردیف از یک صفحه گسترده را که برخی از
ستونهای آن شامل اعداد صحیح، برخی شامل اعداد اعشاری و برخی شامل رشتهها
میباشند، دریافت کنیم. میتوانیم یک enum تعریف کنیم که متغیرهای آن انواع
مختلف مقادیر را نگهداری کنند، و تمام متغیرهای enum به عنوان یک نوع مشابه
(یعنی نوع enum) در نظر گرفته میشوند. سپس میتوانیم یک بردار ایجاد کنیم
که این enum را نگهداری کند و در نتیجه انواع مختلف را ذخیره کند. این موضوع
در لیست ۸-۹ نمایش داده شده است.
fn main() { enum SpreadsheetCell { Int(i32), Float(f64), Text(String), } let row = vec![ SpreadsheetCell::Int(3), SpreadsheetCell::Text(String::from("blue")), SpreadsheetCell::Float(10.12), ]; }
enum برای ذخیره انواع مختلف در یک بردارRust باید بداند چه انواعی در بردار خواهند بود تا بتواند در زمان کامپایل
دقیقاً مشخص کند چه مقدار حافظه در heap برای ذخیره هر عنصر نیاز است.
همچنین باید به طور صریح مشخص کنیم که چه انواعی در این بردار مجاز هستند.
اگر Rust اجازه میداد که بردار هر نوعی را نگهداری کند، احتمال داشت که
یک یا چند نوع باعث ایجاد خطا در عملیات انجام شده روی عناصر بردار شوند.
استفاده از یک enum به علاوه یک عبارت match به این معنی است که Rust
در زمان کامپایل اطمینان حاصل خواهد کرد که تمام حالتهای ممکن مدیریت شدهاند،
همانطور که در فصل ۶ بحث شد.
اگر مجموعه جامعی از انواعی که برنامه در زمان اجرا دریافت میکند و باید
در بردار ذخیره شود را نمیدانید، تکنیک enum کار نخواهد کرد. به جای آن،
میتوانید از یک شیء ویژگی (trait object) استفاده کنید که در فصل ۱۸
مورد بررسی قرار خواهد گرفت.
اکنون که برخی از رایجترین روشهای استفاده از بردارها را بحث کردیم، مطمئن شوید
که مستندات API را برای تمام متدهای مفیدی که کتابخانه
استاندارد روی Vec<T> تعریف کرده است مرور کنید. برای مثال، علاوه بر push،
متد pop عنصر آخر را حذف کرده و بازمیگرداند.
حذف یک بردار، عناصر آن را نیز حذف میکند
مانند هر struct دیگری، یک بردار وقتی از محدوده خارج میشود آزاد میشود،
همانطور که در لیست ۸-۱۰ نشان داده شده است.
fn main() { { let v = vec![1, 2, 3, 4]; // do stuff with v } // <- v goes out of scope and is freed here }
وقتی بردار حذف میشود، تمام محتوای آن نیز حذف میشوند، به این معنی که اعداد صحیحی که نگهداری میکند تمیزکاری میشوند. بررسیکننده قرض اطمینان حاصل میکند که هر مرجع به محتوای یک بردار فقط تا زمانی که خود بردار معتبر است استفاده شود.
حال به نوع مجموعه بعدی میپردازیم: String!
ذخیره متنهای کدگذاری شده UTF-8 با رشتهها (strings)
ما در فصل ۴ درباره رشتهها صحبت کردیم، اما اکنون به آنها با عمق بیشتری نگاه خواهیم کرد. Rustaceanهای تازهوارد معمولاً به دلیل ترکیبی از سه عامل در رشتهها دچار مشکل میشوند: گرایش Rust به آشکارسازی خطاهای ممکن، رشتهها به عنوان یک ساختار داده پیچیدهتر از آنچه بسیاری از برنامهنویسان تصور میکنند، و UTF-8. این عوامل به نحوی ترکیب میشوند که میتوانند برای کسانی که از زبانهای برنامهنویسی دیگر میآیند دشوار باشند.
ما رشتهها را در زمینه مجموعهها بررسی میکنیم، زیرا رشتهها به عنوان مجموعهای از بایتها
پیادهسازی شدهاند، به علاوه تعدادی متد برای ارائه قابلیتهای مفید زمانی که این بایتها
به عنوان متن تفسیر میشوند. در این بخش، درباره عملیاتهایی که روی String انجام میشود
و هر نوع مجموعهای آنها را دارد، مانند ایجاد، بهروزرسانی، و خواندن صحبت خواهیم کرد.
همچنین تفاوتهای String با سایر مجموعهها را مورد بحث قرار میدهیم، بهویژه نحوه پیچیدگی
اندیسگذاری در یک String به دلیل تفاوتهای بین تفسیر دادههای String توسط انسانها
و کامپیوترها.
رشته (string) چیست؟
ابتدا تعریف میکنیم که منظور ما از اصطلاح رشته چیست. Rust فقط یک نوع رشته در زبان
هسته خود دارد که همان قطعه رشته str است که معمولاً به صورت قرض گرفته شده &str
دیده میشود. در فصل ۴ درباره قطعههای رشته صحبت کردیم، که ارجاعاتی به دادههای رشتهای
کدگذاری شده UTF-8 هستند که در جای دیگری ذخیره شدهاند. به عنوان مثال، رشتههای
لیترال در باینری برنامه ذخیره میشوند و بنابراین قطعههای رشته هستند.
نوع String، که توسط کتابخانه استاندارد Rust ارائه شده است و نه مستقیماً در زبان هسته
کدگذاری شده، یک نوع رشته رشدپذیر، قابل تغییر، و مالک UTF-8 است. وقتی Rustaceanها
به “رشتهها” در Rust اشاره میکنند، ممکن است به نوع String یا قطعه رشته &str اشاره
کنند، نه فقط یکی از این دو نوع. اگرچه این بخش عمدتاً درباره String است، اما هر دو نوع
در کتابخانه استاندارد Rust به شدت مورد استفاده قرار میگیرند و هر دو String و قطعههای
رشته کدگذاری UTF-8 دارند.
ایجاد یک رشته (strings) جدید
بسیاری از عملیات مشابه موجود در Vec<T> برای String نیز در دسترس است، زیرا String
در واقع به عنوان یک پوششی بر روی یک بردار از بایتها پیادهسازی شده است، با برخی
ضمانتها، محدودیتها، و قابلیتهای اضافی. مثالی از یک تابع که به همان روش با
Vec<T> و String کار میکند، تابع new برای ایجاد یک نمونه است، همانطور که در لیست
۸-۱۱ نشان داده شده است.
fn main() { let mut s = String::new(); }
String جدید و خالیاین خط یک رشته جدید و خالی به نام s ایجاد میکند که میتوانیم دادهها را در آن بارگذاری کنیم.
اغلب، دادههای اولیهای خواهیم داشت که میخواهیم رشته را با آنها شروع کنیم. برای این کار،
از متد to_string استفاده میکنیم که بر روی هر نوعی که ویژگی Display را پیادهسازی
میکند، همانند رشتههای لیترال، در دسترس است. لیست ۸-۱۲ دو مثال را نشان میدهد.
fn main() { let data = "initial contents"; let s = data.to_string(); // The method also works on a literal directly: let s = "initial contents".to_string(); }
to_string برای ایجاد یک String از یک رشته لیترالاین کد یک رشته حاوی initial contents ایجاد میکند.
ما همچنین میتوانیم از تابع String::from برای ایجاد یک String از یک رشته لیترال
استفاده کنیم. کد در لیست ۸-۱۳ معادل کدی است که در لیست ۸-۱۲ از to_string استفاده میکند.
fn main() { let s = String::from("initial contents"); }
String::from برای ایجاد یک String از یک رشته لیترالاز آنجا که رشتهها برای موارد بسیاری استفاده میشوند، میتوانیم از بسیاری از APIهای
جنریک مختلف برای رشتهها استفاده کنیم که گزینههای زیادی را در اختیار ما قرار میدهند.
برخی از اینها ممکن است به نظر اضافی بیایند، اما هرکدام جایگاه خاص خود را دارند!
در این مورد، String::from و to_string عملکرد یکسانی دارند، بنابراین انتخاب بین آنها
مسئله سبک و خوانایی کد است.
به یاد داشته باشید که رشتهها با کدگذاری UTF-8 هستند، بنابراین میتوانیم هر دادهای که به طور صحیح کدگذاری شده باشد را در آنها قرار دهیم، همانطور که در لیست ۸-۱۴ نشان داده شده است.
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
تمام این موارد مقادیر معتبر String هستند.
بهروزرسانی یک رشته
یک String میتواند از نظر اندازه رشد کند و محتوای آن تغییر کند، همانطور که محتوای
یک Vec<T> تغییر میکند، اگر داده بیشتری به آن اضافه کنیم. علاوه بر این، میتوانیم به راحتی
از عملگر + یا ماکروی format! برای الحاق مقادیر String استفاده کنیم.
الحاق به یک رشته (string) با push_str و push
ما میتوانیم یک String را با استفاده از متد push_str برای الحاق یک قطعه رشته رشد دهیم،
همانطور که در لیست ۸-۱۵ نشان داده شده است.
fn main() { let mut s = String::from("foo"); s.push_str("bar"); }
String با استفاده از متد push_strبعد از این دو خط، مقدار s شامل foobar خواهد بود. متد push_str یک قطعه رشته را به عنوان آرگومان میگیرد
زیرا ما لزوماً نمیخواهیم مالکیت پارامتر را بگیریم. برای مثال، در کدی که در لیست ۸-۱۶ نشان داده شده است،
ما میخواهیم بتوانیم پس از الحاق محتوای s2 به s1 همچنان از s2 استفاده کنیم.
fn main() { let mut s1 = String::from("foo"); let s2 = "bar"; s1.push_str(s2); println!("s2 is {s2}"); }
Stringاگر متد push_str مالکیت s2 را میگرفت، نمیتوانستیم مقدار آن را در خط آخر چاپ کنیم. با این حال،
این کد همانطور که انتظار میرود کار میکند!
متد push یک کاراکتر را به عنوان پارامتر میگیرد و آن را به String اضافه میکند. لیست ۸-۱۷
حرف l را با استفاده از متد push به یک String اضافه میکند.
fn main() { let mut s = String::from("lo"); s.push('l'); }
String با استفاده از pushدر نتیجه، مقدار s شامل lol خواهد بود.
الحاق با استفاده از عملگر + یا ماکروی format!
اغلب، ممکن است بخواهید دو رشته موجود را با هم ترکیب کنید. یکی از راههای انجام این کار
استفاده از عملگر + است، همانطور که در لیست ۸-۱۸ نشان داده شده است.
fn main() { let s1 = String::from("Hello, "); let s2 = String::from("world!"); let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used }
+ برای ترکیب دو مقدار String در یک مقدار String جدیدمقدار s3 شامل Hello, world! خواهد بود. دلیل اینکه s1 پس از این الحاق دیگر معتبر نیست
و دلیل اینکه ما از یک مرجع به s2 استفاده کردیم، به امضای متدی که هنگام استفاده از
عملگر + فراخوانی میشود مربوط است. عملگر + از متد add استفاده میکند که امضای آن به شکل زیر است:
fn add(self, s: &str) -> String {در کتابخانه استاندارد، شما add را خواهید دید که با استفاده از جنریکها و انواع مرتبط تعریف شده است.
اینجا، ما انواع مشخصی را جایگزین کردهایم، که این همان چیزی است که هنگام فراخوانی این متد با مقادیر
String اتفاق میافتد. درباره جنریکها در فصل ۱۰ صحبت خواهیم کرد. این امضا به ما سرنخهایی میدهد
تا بتوانیم بخشهای چالشبرانگیز عملگر + را درک کنیم.
اول، s2 یک & دارد، به این معنی که ما یک مرجع از رشته دوم را به رشته اول اضافه میکنیم.
این به دلیل پارامتر s در تابع add است: ما فقط میتوانیم یک &str را به یک String اضافه کنیم؛
نمیتوانیم دو مقدار String را با هم جمع کنیم. اما صبر کنید—نوع &s2، &String است، نه &str
همانطور که در پارامتر دوم add مشخص شده است. پس چرا کد در لیست ۸-۱۸ کامپایل میشود؟
دلیل اینکه میتوانیم از &s2 در فراخوانی add استفاده کنیم این است که کامپایلر میتواند آرگومان
&String را به &str تبدیل کند. هنگامی که ما متد add را فراخوانی میکنیم، Rust از یک
coercion deref استفاده میکند که در اینجا &s2 را به &s2[..] تبدیل میکند. ما این موضوع
را در فصل ۱۵ به طور عمیقتری بررسی خواهیم کرد. از آنجا که add مالکیت پارامتر s را نمیگیرد،
s2 پس از این عملیات همچنان یک String معتبر باقی خواهد ماند.
دوم، میتوانیم در امضا ببینیم که add مالکیت self را میگیرد زیرا self یک & ندارد.
این بدان معناست که s1 در لیست ۸-۱۸ به فراخوانی add منتقل میشود و پس از آن دیگر معتبر نخواهد بود.
بنابراین، اگرچه let s3 = s1 + &s2; به نظر میرسد که هر دو رشته را کپی میکند و یک رشته جدید ایجاد
میکند، این عبارت در واقع مالکیت s1 را میگیرد، یک کپی از محتوای s2 را اضافه میکند، و سپس مالکیت
نتیجه را بازمیگرداند. به عبارت دیگر، به نظر میرسد که کپیهای زیادی انجام میدهد، اما اینطور نیست؛
پیادهسازی کارآمدتر از کپی کردن است.
اگر نیاز به الحاق چندین رشته داشته باشیم، رفتار عملگر + دستوپاگیر میشود:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = s1 + "-" + &s2 + "-" + &s3; }
در این نقطه، مقدار s برابر با tic-tac-toe خواهد بود. با تمام این + و کاراکترهای "،
دیدن اینکه چه اتفاقی میافتد دشوار است. برای ترکیب رشتهها به روشهای پیچیدهتر، میتوانیم
به جای آن از ماکروی format! استفاده کنیم:
fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); let s = format!("{s1}-{s2}-{s3}"); }
این کد نیز مقدار s را به tic-tac-toe تنظیم میکند. ماکروی format! شبیه به println! کار میکند،
اما به جای چاپ خروجی روی صفحه، یک String با محتوای مورد نظر بازمیگرداند. نسخه کد با استفاده از
format! بسیار خواناتر است و کدی که توسط ماکروی format! تولید میشود از مراجع استفاده میکند،
بنابراین این فراخوانی مالکیت هیچیک از پارامترهایش را نمیگیرد.
اندیسگذاری در رشتهها
در بسیاری از زبانهای برنامهنویسی دیگر، دسترسی به کاراکترهای منفرد در یک رشته با اشاره به آنها
توسط اندیس (index)یک عملیات معتبر و رایج است. با این حال، اگر تلاش کنید در Rust با استفاده از سینتکس
اندیسگذاری به بخشهایی از یک String دسترسی پیدا کنید، با خطا مواجه میشوید. کد نامعتبر
در لیست ۸-۱۹ را در نظر بگیرید.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}Stringاین کد به خطای زیر منجر خواهد شد:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
but trait `SliceIndex<[_]>` is implemented for `usize`
= help: for that trait implementation, expected `[_]`, found `str`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
خطا و توضیحات آن گویای موضوع است: رشتههای Rust از اندیسگذاری پشتیبانی نمیکنند. اما چرا؟ برای پاسخ به این سؤال، باید درباره نحوه ذخیرهسازی رشتهها در حافظه توسط Rust صحبت کنیم.
نمایش داخلی
یک String در واقع یک پوشش بر روی Vec<u8> است. بیایید به برخی از مثالهای رشتههای کدگذاری
شده UTF-8 در لیست ۸-۱۴ نگاه کنیم. ابتدا این مورد:
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
در این حالت، مقدار len برابر با 4 خواهد بود، به این معنی که برداری که رشته "Hola" را
ذخیره میکند ۴ بایت طول دارد. هر یک از این حروف هنگام کدگذاری در UTF-8 یک بایت میگیرد.
با این حال، خط زیر ممکن است شما را شگفتزده کند (توجه داشته باشید که این رشته با حرف بزرگ
سیریلیک Ze آغاز میشود، نه عدد ۳):
fn main() { let hello = String::from("السلام عليكم"); let hello = String::from("Dobrý den"); let hello = String::from("Hello"); let hello = String::from("שלום"); let hello = String::from("नमस्ते"); let hello = String::from("こんにちは"); let hello = String::from("안녕하세요"); let hello = String::from("你好"); let hello = String::from("Olá"); let hello = String::from("Здравствуйте"); let hello = String::from("Hola"); }
اگر از شما پرسیده شود طول این رشته چقدر است، ممکن است بگویید ۱۲. اما در واقع، پاسخ Rust ۲۴ است: این تعداد بایتهایی است که برای کدگذاری “Здравствуйте” در UTF-8 نیاز است، زیرا هر مقدار اسکالر Unicode در این رشته ۲ بایت فضای ذخیرهسازی میگیرد. بنابراین، یک اندیس (index)در بایتهای رشته همیشه با یک مقدار اسکالر Unicode معتبر مطابقت ندارد. برای نشان دادن این موضوع، کد نامعتبر زیر در Rust را در نظر بگیرید:
let hello = "Здравствуйте";
let answer = &hello[0];شما قبلاً میدانید که مقدار answer برابر با З، اولین حرف، نخواهد بود. وقتی در UTF-8 کدگذاری
میشود، اولین بایت از З برابر با 208 و دومین بایت برابر با 151 است، بنابراین ممکن است به نظر
برسد که answer باید در واقع 208 باشد، اما 208 به تنهایی یک کاراکتر معتبر نیست. بازگرداندن
208 احتمالاً چیزی نیست که یک کاربر بخواهد اگر درخواست اولین حرف این رشته را داشته باشد؛
با این حال، این تنها دادهای است که Rust در اندیس (index)بایت ۰ دارد. کاربران به طور کلی نمیخواهند
مقدار بایت بازگردانده شود، حتی اگر رشته فقط حروف لاتین داشته باشد: اگر &"hi"[0] یک کد معتبر
بود که مقدار بایت را بازمیگرداند، مقدار 104 و نه h را بازمیگرداند.
پاسخ این است که برای جلوگیری از بازگرداندن یک مقدار غیرمنتظره و ایجاد باگهایی که ممکن است فوراً کشف نشوند، Rust این کد را اصلاً کامپایل نمیکند و از سوءتفاهمها در اوایل فرآیند توسعه جلوگیری میکند.
بایتها، مقادیر اسکالر و خوشههای گرافیمی! اوه خدای من!
نکته دیگری درباره UTF-8 این است که در واقع سه روش مرتبط برای مشاهده رشتهها از دیدگاه Rust وجود دارد: به صورت بایت، مقادیر اسکالر، و خوشههای گرافیمی (نزدیکترین چیز به چیزی که ما حروف مینامیم).
اگر به کلمه هندی “नमस्ते” نوشته شده در اسکریپت Devanagari نگاه کنیم، این کلمه به صورت یک بردار
از مقادیر u8 ذخیره میشود که به شکل زیر است:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
این ۱۸ بایت است و این همان چیزی است که کامپیوترها در نهایت این داده را ذخیره میکنند.
اگر به آنها به عنوان مقادیر اسکالر Unicode نگاه کنیم، که همان نوع char در Rust است، این بایتها
به این صورت به نظر میرسند:
['न', 'म', 'स', '्', 'त', 'े']
اینجا شش مقدار char وجود دارد، اما مقدار چهارم و ششم حروف نیستند: اینها دیاکریتیکهایی هستند که
به تنهایی معنایی ندارند. در نهایت، اگر به آنها به عنوان خوشههای گرافیمی نگاه کنیم، همان چیزی
که یک فرد به عنوان حروف کلمه هندی تشخیص میدهد، اینطور خواهد بود:
["न", "म", "स्", "ते"]
Rust روشهای مختلفی برای تفسیر داده خام رشته ارائه میدهد که کامپیوترها ذخیره میکنند، بنابراین هر برنامه میتواند تفسیری را که نیاز دارد انتخاب کند، صرف نظر از اینکه داده به چه زبان انسانی است.
یکی دیگر از دلایل اینکه Rust به ما اجازه نمیدهد در یک String اندیسگذاری کنیم تا یک کاراکتر را
دریافت کنیم این است که عملیات اندیسگذاری باید همیشه در زمان ثابت (O(1)) انجام شود. اما امکان
تضمین این عملکرد با یک String وجود ندارد، زیرا Rust باید محتویات را از ابتدا تا اندیس (index)مرور کند تا
تعیین کند که چند کاراکتر معتبر وجود دارد.
برش رشتهها
اندیسگذاری در یک رشته اغلب ایده خوبی نیست زیرا مشخص نیست که نوع بازگشتی عملیات اندیسگذاری رشته چه باید باشد: یک مقدار بایت، یک کاراکتر، یک خوشه گرافیمی، یا یک قطعه رشته. بنابراین، اگر واقعاً نیاز به استفاده از اندیسها برای ایجاد قطعههای رشته دارید، Rust از شما میخواهد بیشتر مشخص کنید.
به جای اندیسگذاری با استفاده از [] و یک عدد، میتوانید از [] با یک بازه استفاده کنید
تا یک قطعه رشته که شامل بایتهای خاصی است ایجاد کنید:
#![allow(unused)] fn main() { let hello = "Здравствуйте"; let s = &hello[0..4]; }
اینجا، s یک &str خواهد بود که شامل چهار بایت اول رشته است. پیشتر اشاره کردیم که هر
یک از این کاراکترها دو بایت طول دارند، که به این معنی است که مقدار s برابر با Зд خواهد بود.
اگر سعی کنیم فقط بخشی از بایتهای یک کاراکتر را با چیزی مثل &hello[0..1] برش دهیم،
Rust در زمان اجرا دچار خطا میشود، به همان شکلی که اگر یک اندیس (index)نامعتبر در یک بردار
دسترسی داده شود:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
هنگام ایجاد قطعههای رشته با بازهها باید احتیاط کنید، زیرا این کار ممکن است باعث خرابی برنامه شما شود.
متدهایی برای پیمایش در رشتهها
بهترین راه برای کار با بخشهایی از رشتهها این است که به وضوح مشخص کنید که آیا میخواهید
روی کاراکترها یا بایتها کار کنید. برای مقادیر اسکالر Unicode منفرد، از متد chars استفاده کنید.
فراخوانی chars روی "Зд" دو مقدار از نوع char را جدا کرده و بازمیگرداند، و میتوانید
با استفاده از نتیجه پیمایش کنید تا به هر عنصر دسترسی پیدا کنید:
#![allow(unused)] fn main() { for c in "Зд".chars() { println!("{c}"); } }
این کد خروجی زیر را چاپ خواهد کرد:
З
д
به صورت جایگزین، متد bytes هر بایت خام را بازمیگرداند که ممکن است برای حوزه کاری شما مناسب باشد:
#![allow(unused)] fn main() { for b in "Зд".bytes() { println!("{b}"); } }
این کد چهار بایتی که این رشته را تشکیل میدهند چاپ خواهد کرد:
208
151
208
180
اما حتماً به یاد داشته باشید که مقادیر اسکالر Unicode معتبر ممکن است از بیش از یک بایت تشکیل شده باشند.
دریافت خوشههای گرافیمی از رشتهها، همانند اسکریپت Devanagari، پیچیده است، بنابراین این قابلیت توسط کتابخانه استاندارد ارائه نمیشود. اگر به این قابلیت نیاز دارید، کرایتهایی در crates.io موجود هستند.
رشتهها اینقدر ساده نیستند
به طور خلاصه، رشتهها پیچیده هستند. زبانهای برنامهنویسی مختلف انتخابهای متفاوتی درباره نحوه
نمایش این پیچیدگی به برنامهنویس میکنند. Rust انتخاب کرده است که مدیریت صحیح دادههای
String رفتار پیشفرض برای تمام برنامههای Rust باشد، که به این معنی است که برنامهنویسان
باید در ابتدا بیشتر درباره مدیریت دادههای UTF-8 فکر کنند. این معامله پیچیدگی بیشتری از رشتهها
را نسبت به سایر زبانهای برنامهنویسی نشان میدهد، اما از مواجهه با خطاهای مربوط به کاراکترهای
غیر-ASCII در مراحل بعدی چرخه توسعه جلوگیری میکند.
خبر خوب این است که کتابخانه استاندارد عملکردهای زیادی را بر اساس انواع String و &str
برای کمک به مدیریت صحیح این شرایط پیچیده ارائه میدهد. حتماً مستندات را برای متدهای مفیدی مانند
contains برای جستجو در یک رشته و replace برای جایگزینی بخشهایی از یک رشته با رشتهای دیگر
بررسی کنید.
بیایید به چیزی کمی کمتر پیچیده برویم: هش مپها!
ذخیره کلیدها با مقادیر مرتبط در هش مپها
آخرین مورد از مجموعههای رایج ما، هش مپ است. نوع HashMap<K, V> یک نگاشت از کلیدهایی
با نوع K به مقادیری با نوع V را با استفاده از یک تابع هش ذخیره میکند، که تعیین میکند
چگونه این کلیدها و مقادیر در حافظه قرار بگیرند. بسیاری از زبانهای برنامهنویسی از این نوع
ساختار داده پشتیبانی میکنند، اما اغلب از نامهای متفاوتی مانند هش، مپ، شیء،
جدول هش، دایرکتوری، یا آرایه ارتباطی برای اشاره به آن استفاده میکنند.
هش مپها زمانی مفید هستند که بخواهید دادهها را نه با استفاده از یک اندیس، مانند بردارها، بلکه با استفاده از یک کلید که میتواند هر نوعی باشد، جستجو کنید. برای مثال، در یک بازی، میتوانید امتیاز هر تیم را در یک هش مپ ذخیره کنید که هر کلید نام یک تیم و هر مقدار امتیاز آن تیم باشد. با داشتن نام یک تیم، میتوانید امتیاز آن را بازیابی کنید.
در این بخش، به API اصلی هش مپها میپردازیم، اما امکانات بیشتری در توابع تعریف شده
روی HashMap<K, V> در کتابخانه استاندارد وجود دارد. مانند همیشه، مستندات کتابخانه
استاندارد را برای اطلاعات بیشتر بررسی کنید.
ایجاد یک هش مپ جدید
یکی از راههای ایجاد یک هش مپ خالی استفاده از new و افزودن عناصر با insert است.
در لیست ۸-۲۰، ما امتیازات دو تیم به نامهای Blue و Yellow را پیگیری میکنیم. تیم
آبی با ۱۰ امتیاز و تیم زرد با ۵۰ امتیاز شروع میکنند.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); }
توجه داشته باشید که ابتدا باید HashMap را از بخش مجموعههای کتابخانه استاندارد use
کنیم. از میان سه مجموعه رایج ما، این یکی کمتر مورد استفاده قرار میگیرد، بنابراین به طور
پیشفرض در محدوده وارد نمیشود. همچنین، هش مپها از حمایت کمتری از کتابخانه استاندارد
برخوردارند؛ برای مثال، هیچ ماکروی داخلی برای ساخت آنها وجود ندارد.
همانند بردارها، هش مپها دادههای خود را روی heap ذخیره میکنند. این HashMap دارای
کلیدهایی از نوع String و مقادیری از نوع i32 است. مانند بردارها، هش مپها همگن هستند:
تمام کلیدها باید از یک نوع باشند و تمام مقادیر نیز باید از یک نوع باشند.
دسترسی به مقادیر در یک هش مپ
میتوانیم یک مقدار را با ارائه کلید آن به متد get از هش مپ دریافت کنیم، همانطور که
در لیست ۸-۲۱ نشان داده شده است.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); let team_name = String::from("Blue"); let score = scores.get(&team_name).copied().unwrap_or(0); }
اینجا، مقدار score برابر با مقداری خواهد بود که به تیم Blue مرتبط است، و نتیجه 10 خواهد بود.
متد get یک Option<&V> را بازمیگرداند؛ اگر هیچ مقداری برای آن کلید در هش مپ وجود نداشته
باشد، get مقدار None را بازمیگرداند. این برنامه مقدار Option را با فراخوانی copied
برای دریافت یک Option<i32> به جای Option<&i32> مدیریت میکند، سپس با استفاده از unwrap_or
مقدار score را به صفر تنظیم میکند اگر scores یک ورودی برای کلید نداشته باشد.
میتوانیم روی هر جفت کلید-مقدار در یک hash map بهروشی مشابه با vectorها پیمایش کنیم،
با استفاده از یک حلقهی for:
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); for (key, value) in &scores { println!("{key}: {value}"); } }
این کد هر جفت را به ترتیب دلخواه چاپ خواهد کرد:
Yellow: 50
Blue: 10
هش مپها و مالکیت
برای انواعی که ویژگی Copy را پیادهسازی میکنند، مانند i32، مقادیر درون هش مپ کپی میشوند.
برای مقادیر مالک مانند String، مقادیر منتقل شده و هش مپ مالک آنها خواهد شد، همانطور که در
لیست ۸-۲۲ نشان داده شده است.
fn main() { use std::collections::HashMap; let field_name = String::from("Favorite color"); let field_value = String::from("Blue"); let mut map = HashMap::new(); map.insert(field_name, field_value); // field_name and field_value are invalid at this point, try using them and // see what compiler error you get! }
پس از انتقال متغیرهای field_name و field_value به هش مپ با فراخوانی insert، دیگر نمیتوانیم
از آنها استفاده کنیم.
اگر رفرنسهایی به مقادیر را درون hash map قرار دهیم، آن مقادیر به درون hash map منتقل نخواهند شد (moved نمیشوند).
مقدارهایی که این رفرنسها به آنها اشاره میکنند، باید حداقل تا زمانی معتبر باشند که hash map معتبر است.
در فصل ۱۰، در بخش “اعتبارسنجی رفرنسها با استفاده از lifetime”،
بیشتر دربارهی این مسائل صحبت خواهیم کرد.
بهروزرسانی یک هش مپ
اگرچه تعداد جفتهای کلید و مقدار قابل افزایش است، هر کلید یکتا فقط میتواند یک مقدار
مرتبط داشته باشد (اما نه بالعکس: برای مثال، هر دو تیم Blue و Yellow میتوانند مقدار 10
را در هش مپ scores ذخیره کنند).
وقتی میخواهید دادهها را در یک هش مپ تغییر دهید، باید تصمیم بگیرید چگونه با حالتی که یک کلید قبلاً دارای مقدار است برخورد کنید. میتوانید مقدار قدیمی را با مقدار جدید جایگزین کنید و مقدار قدیمی را کاملاً نادیده بگیرید. میتوانید مقدار قدیمی را نگه دارید و مقدار جدید را نادیده بگیرید، فقط مقدار جدید را اضافه کنید اگر کلید ندارد قبلاً یک مقدار. یا میتوانید مقدار قدیمی و مقدار جدید را با هم ترکیب کنید. بیایید ببینیم چگونه هر یک از این کارها را انجام دهیم!
بازنویسی یک مقدار
اگر یک کلید و مقدار را درون یک hash map قرار دهیم و سپس همان کلید را با یک مقدار متفاوت دوباره وارد کنیم،
مقدار مرتبط با آن کلید جایگزین خواهد شد.
حتی با اینکه کد در لیستینگ 8-23 دوبار تابع insert را فراخوانی میکند،
hash map تنها شامل یک جفت کلید-مقدار خواهد بود،
زیرا هر دو بار مقدار مربوط به کلید تیم Blue را وارد میکنیم.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Blue"), 25); println!("{scores:?}"); }
این کد مقدار {"Blue": 25} را چاپ خواهد کرد. مقدار اصلی 10 بازنویسی شده است.
اضافه کردن یک کلید و مقدار فقط اگر کلید وجود ندارد
بررسی اینکه آیا یک کلید خاص در هش مپ دارای مقدار است یا خیر و سپس انجام اقدامات زیر رایج است: اگر کلید در هش مپ وجود دارد، مقدار موجود باید همانطور که هست باقی بماند؛ اگر کلید وجود ندارد، آن را به همراه یک مقدار وارد کنید.
هش مپها یک API خاص برای این کار دارند که به نام entry شناخته میشود و کلیدی که میخواهید بررسی کنید
را به عنوان پارامتر میگیرد. مقدار بازگشتی متد entry یک enum به نام Entry است که نشاندهنده مقداری
است که ممکن است وجود داشته باشد یا نداشته باشد. فرض کنید میخواهیم بررسی کنیم که آیا کلید تیم Yellow
دارای مقدار مرتبط است یا خیر. اگر ندارد، میخواهیم مقدار 50 را وارد کنیم، و همینطور برای تیم Blue.
با استفاده از API entry، کد به شکل لیست ۸-۲۴ خواهد بود.
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.entry(String::from("Yellow")).or_insert(50); scores.entry(String::from("Blue")).or_insert(50); println!("{scores:?}"); }
entry برای وارد کردن مقدار فقط در صورتی که کلید قبلاً مقدار نداردمتد or_insert روی Entry به گونهای تعریف شده است که یک مرجع قابل تغییر به مقدار مرتبط با کلید
Entry برمیگرداند اگر آن کلید وجود داشته باشد، و اگر نه، پارامتر را به عنوان مقدار جدید برای
این کلید وارد کرده و یک مرجع قابل تغییر به مقدار جدید بازمیگرداند. این تکنیک بسیار تمیزتر از نوشتن
منطق به صورت دستی است و علاوه بر این، با بررسیکننده قرض بهتر کار میکند.
اجرای کد در لیست ۸-۲۴ مقدار {"Yellow": 50, "Blue": 10} را چاپ خواهد کرد. اولین فراخوانی به entry
کلید تیم Yellow را با مقدار 50 وارد میکند زیرا تیم Yellow قبلاً مقداری ندارد. دومین فراخوانی
به entry هش مپ را تغییر نمیدهد زیرا تیم Blue قبلاً مقدار 10 را دارد.
بهروزرسانی یک مقدار بر اساس مقدار قدیمی
یکی دیگر از موارد استفاده رایج برای هش مپها این است که مقدار یک کلید را جستجو کرده و سپس بر اساس
مقدار قدیمی آن را بهروزرسانی کنیم. برای مثال، لیست ۸-۲۵ کدی را نشان میدهد که تعداد دفعات ظاهر شدن
هر کلمه در یک متن را میشمارد. ما از یک هش مپ با کلمات به عنوان کلید و مقدار برای نگهداری تعداد دفعات
ظاهر شدن هر کلمه استفاده میکنیم. اگر این اولین بار باشد که یک کلمه را مشاهده میکنیم، ابتدا مقدار
0 را وارد میکنیم.
fn main() { use std::collections::HashMap; let text = "hello world wonderful world"; let mut map = HashMap::new(); for word in text.split_whitespace() { let count = map.entry(word).or_insert(0); *count += 1; } println!("{map:?}"); }
این کد مقدار {"world": 2, "hello": 1, "wonderful": 1} را چاپ خواهد کرد.
ممکن است همین جفتهای کلید-مقدار را به ترتیب متفاوتی ببینید:
به یاد داشته باشید از بخش “دسترسی به مقادیر در یک Hash Map”
که پیمایش در یک hash map بهصورت ترتیبی دلخواه (arbitrary order) انجام میشود.
متد split_whitespace یک iterator بر روی زیررشتههایی که با فضای خالی جدا شدهاند از مقدار موجود
در text بازمیگرداند. متد or_insert یک مرجع قابل تغییر (&mut V) به مقدار مرتبط با کلید مشخص
برمیگرداند. اگر آن کلید وجود داشته باشد، مقدار بازگشتی همان مقدار موجود است؛ و اگر نه، پارامتر
را به عنوان مقدار جدید برای این کلید وارد میکند و مرجع قابل تغییر به مقدار جدید را بازمیگرداند.
در اینجا، ما این مرجع قابل تغییر را در متغیر count ذخیره میکنیم، بنابراین برای تخصیص مقدار
به آن، باید ابتدا count را با استفاده از عملگر ستاره (*) dereference کنیم. مرجع قابل تغییر
در انتهای حلقه for از محدوده خارج میشود، بنابراین تمام این تغییرات ایمن هستند و قوانین
قرضگیری را نقض نمیکنند.
توابع هش
به طور پیشفرض، HashMap از یک تابع هش به نام SipHash استفاده میکند که مقاومت در برابر
حملات انکار سرویس (DoS) مربوط به جداول هش1 را فراهم میکند. این سریعترین
الگوریتم هش موجود نیست، اما مبادله برای امنیت بهتر با کاهش عملکرد ارزشمند است. اگر کد خود را
پروفایل کنید و متوجه شوید که تابع هش پیشفرض برای اهداف شما بسیار کند است، میتوانید با مشخص کردن
یک هشکننده دیگر آن را تغییر دهید. یک هشکننده نوعی است که ویژگی BuildHasher را پیادهسازی
میکند. درباره ویژگیها (traits) و نحوه پیادهسازی آنها در فصل ۱۰ صحبت
خواهیم کرد. نیازی نیست حتماً هشکننده خود را از ابتدا پیادهسازی کنید؛ در
crates.io کتابخانههایی موجود هستند که توسط کاربران Rust به
اشتراک گذاشته شدهاند و هشکنندههایی با بسیاری از الگوریتمهای هش رایج ارائه میدهند.
خلاصه
بردارها، رشتهها، و هش مپها مقدار زیادی از قابلیتهای مورد نیاز برای ذخیره، دسترسی، و تغییر دادهها در برنامهها را فراهم میکنند. در اینجا چند تمرین وجود دارد که اکنون باید قادر به حل آنها باشید:
- با داشتن یک لیست از اعداد صحیح، از یک بردار استفاده کرده و میانه (وقتی مرتبسازی شود، مقداری که در موقعیت وسط قرار دارد) و مد (مقداری که بیشترین بار ظاهر میشود؛ یک هش مپ در اینجا مفید خواهد بود) لیست را بازگردانید.
- رشتهها را به زبان لاتین خوکی تبدیل کنید. اولین صامت هر کلمه به انتهای کلمه منتقل شده و ay به آن اضافه میشود، بنابراین first به irst-fay تبدیل میشود. کلماتی که با یک حرف صدادار شروع میشوند، hay به انتهای آنها اضافه میشود (apple به apple-hay تبدیل میشود). جزئیات مربوط به کدگذاری UTF-8 را در نظر داشته باشید!
- با استفاده از یک هش مپ و بردارها، یک رابط متنی ایجاد کنید تا به کاربر امکان اضافه کردن نام کارمندان به یک دپارتمان در شرکت را بدهد؛ برای مثال، “Add Sally to Engineering” یا “Add Amir to Sales”. سپس به کاربر اجازه دهید لیستی از تمام افراد در یک دپارتمان یا تمام افراد در شرکت بر اساس دپارتمان، مرتب شده به صورت حروف الفبا، بازیابی کند.
مستندات API کتابخانه استاندارد متدهایی را که بردارها، رشتهها، و هش مپها دارند و برای این تمرینها مفید خواهند بود توصیف میکنند!
ما وارد برنامههای پیچیدهتری شدهایم که در آنها عملیات ممکن است با شکست مواجه شوند، بنابراین زمان مناسبی است تا درباره مدیریت خطا صحبت کنیم. این کار را در ادامه انجام خواهیم داد!
مدیریت خطاها
خطاها بخشی اجتنابناپذیر از زندگی در دنیای نرمافزار هستند، و به همین دلیل، Rust ویژگیهای متعددی برای مدیریت موقعیتهایی دارد که در آنها مشکلی پیش میآید. در بسیاری از موارد، Rust شما را ملزم میکند که امکان وقوع یک خطا را به رسمیت بشناسید و پیش از آنکه کد شما کامپایل شود، اقدامی انجام دهید. این الزام باعث میشود برنامهی شما مقاومتر باشد، زیرا تضمین میکند که خطاها را پیش از استقرار کد در محیط اجرایی (production) شناسایی کرده و بهدرستی مدیریت کردهاید.
Rust خطاها را به دو دسته اصلی تقسیم میکند: خطاهای قابل بازیابی و خطاهای غیرقابل بازیابی. برای یک خطای قابل بازیابی، مانند خطای فایل یافت نشد، احتمالاً میخواهیم مشکل را به کاربر گزارش دهیم و عملیات را دوباره انجام دهیم. خطاهای غیرقابل بازیابی همیشه نشانههای باگها هستند، مانند تلاش برای دسترسی به مکانی خارج از انتهای یک آرایه، بنابراین میخواهیم بلافاصله برنامه را متوقف کنیم.
بیشتر زبانها بین این دو نوع خطا تفاوت قائل نمیشوند و هر دو را به یک شکل مدیریت میکنند،
با استفاده از مکانیزمهایی مانند استثناها. Rust استثناها ندارد. در عوض، نوع Result<T, E> برای
خطاهای قابل بازیابی و ماکروی panic! که اجرای برنامه را زمانی که با یک خطای غیرقابل بازیابی
روبرو میشود متوقف میکند، ارائه میدهد. این فصل ابتدا به فراخوانی panic! میپردازد و سپس
در مورد بازگرداندن مقادیر Result<T, E> صحبت میکند. علاوه بر این، ملاحظاتی را هنگام تصمیمگیری
در مورد اینکه آیا سعی در بازیابی از یک خطا کنیم یا اجرای برنامه را متوقف کنیم، بررسی خواهیم کرد.
خطاهای غیرقابل بازیابی با panic!
گاهی اوقات اتفاقات بدی در کد شما رخ میدهد و هیچ کاری نمیتوانید در مورد آن انجام دهید. در این موارد،
Rust ماکروی panic! را ارائه میدهد. دو راه برای ایجاد یک خطا با panic! وجود دارد: با انجام عملی
که باعث ایجاد خطا میشود (مانند دسترسی به یک اندیس (index)خارج از محدوده در یک آرایه) یا با صراحت
فراخوانی ماکروی panic!. در هر دو حالت، ما یک خطا در برنامه خود ایجاد میکنیم. به طور پیشفرض،
این خطاها یک پیام خطا چاپ میکنند، استک را unwind میکنند، دادهها را پاکسازی میکنند و برنامه
را متوقف میکنند. با استفاده از یک متغیر محیطی، میتوانید Rust را مجبور کنید هنگام وقوع یک
panic، استک فراخوانی را نمایش دهد تا ردیابی منبع خطا آسانتر شود.
Unwinding the Stack یا متوقف کردن در پاسخ به یک Panic
به طور پیشفرض، هنگامی که یک خطا رخ میدهد، برنامه شروع به unwinding میکند، که به معنی این است که Rust استک را به سمت بالا پیمایش میکند و دادهها را از هر تابعی که با آن برخورد میکند پاکسازی میکند. با این حال، پیمایش به بالا و پاکسازی کار زیادی است. بنابراین، Rust به شما اجازه میدهد گزینه جایگزین abort کردن فوری را انتخاب کنید، که برنامه را بدون پاکسازی متوقف میکند.
حافظهای که برنامه استفاده میکرد نیاز به پاکسازی توسط سیستم عامل خواهد داشت. اگر در پروژه
خود نیاز دارید تا فایل باینری حاصل را تا حد ممکن کوچک کنید، میتوانید از unwind به abort در
زمان خطا تغییر دهید با اضافه کردن panic = 'abort' به بخشهای مناسب [profile] در فایل
Cargo.toml خود. برای مثال، اگر میخواهید در حالت release در زمان وقوع خطا متوقف شوید،
این مورد را اضافه کنید:
[profile.release]
panic = 'abort'
بیایید فراخوانی panic! را در یک برنامه ساده امتحان کنیم:
fn main() { panic!("crash and burn"); }
وقتی برنامه را اجرا کنید، چیزی شبیه به این خواهید دید:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
فراخوانی panic! پیام خطای موجود در دو خط آخر را ایجاد میکند. خط اول پیام خطای panic! ما
و مکانی در کد منبع ما که این خطا رخ داده است را نشان میدهد: src/main.rs:2:5 نشان میدهد
که این خط دوم، پنجمین کاراکتر در فایل src/main.rs ما است.
در این مورد، خط نشان داده شده بخشی از کد ما است، و اگر به آن خط برویم، فراخوانی ماکروی
panic! را میبینیم. در موارد دیگر، فراخوانی panic! ممکن است در کدی باشد که کد ما آن را
فراخوانی میکند، و نام فایل و شماره خط گزارش شده توسط پیام خطا کدی از دیگران را نشان میدهد
که در آن ماکروی panic! فراخوانی شده است، نه خطی از کد ما که در نهایت منجر به فراخوانی
panic! شد.
ما میتوانیم از backtrace توابعی که فراخوانی panic! از آنها آمده است استفاده کنیم تا بخش کد
ما که باعث مشکل شده است را پیدا کنیم. برای درک نحوه استفاده از backtrace یک panic!، بیایید
یک مثال دیگر ببینیم و مشاهده کنیم زمانی که یک فراخوانی panic! از یک کتابخانه به دلیل یک باگ
در کد ما رخ میدهد، به جای اینکه کد ما مستقیماً ماکرو را فراخوانی کند، چگونه است. لیست ۹-۱
کدی دارد که تلاش میکند به یک اندیس (index)در یک بردار که خارج از محدوده اندیسهای معتبر است
دسترسی پیدا کند.
fn main() { let v = vec![1, 2, 3]; v[99]; }
panic! خواهد شددر اینجا، ما سعی داریم به عنصر صدم بردار خود دسترسی پیدا کنیم (که در اندیس (index)۹۹ است زیرا اندیسگذاری از صفر شروع میشود)، اما بردار فقط سه عنصر دارد. در این وضعیت، Rust با یک خطا متوقف میشود. استفاده از [] قرار است یک عنصر را بازگرداند، اما اگر یک اندیس (index)نامعتبر را ارائه دهید، هیچ عنصری وجود ندارد که Rust بتواند به درستی بازگرداند.
در زبان C، تلاش برای خواندن فراتر از انتهای یک ساختار داده رفتاری نامشخص دارد. ممکن است هر چیزی که در مکان حافظهای که با آن عنصر در ساختار داده مطابقت دارد باشد را دریافت کنید، حتی اگر آن حافظه متعلق به آن ساختار نباشد. این به عنوان buffer overread شناخته میشود و میتواند به آسیبپذیریهای امنیتی منجر شود اگر یک مهاجم بتواند اندیس (index)را به گونهای دستکاری کند که دادههایی را بخواند که نباید به آنها دسترسی داشته باشد و پس از ساختار داده ذخیره شدهاند.
برای محافظت از برنامه شما در برابر این نوع آسیبپذیری، اگر تلاش کنید یک عنصر را در یک اندیسی که وجود ندارد بخوانید، Rust اجرای برنامه را متوقف کرده و از ادامه دادن امتناع میکند. بیایید این موضوع را امتحان کنیم و ببینیم:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
این خطا به خط ۴ فایل main.rs ما اشاره میکند، جایی که سعی داریم به اندیس (index)99 بردار v دسترسی پیدا کنیم.
خط note: به ما میگوید که میتوانیم متغیر محیطی RUST_BACKTRACE را تنظیم کنیم تا یک backtrace دقیقاً از آنچه باعث خطا شده است دریافت کنیم. یک backtrace لیستی از تمام توابعی است که تا این نقطه فراخوانی شدهاند. backtraceها در Rust مانند زبانهای دیگر کار میکنند: کلید خواندن backtrace این است که از بالا شروع کرده و تا زمانی که فایلهایی که شما نوشتهاید را ببینید، بخوانید. این همان جایی است که مشکل از آنجا منشأ گرفته است. خطوط بالاتر از آن نقطه کدی است که کد شما فراخوانی کرده است؛ خطوط پایینتر کدی است که کد شما را فراخوانی کرده است. این خطوط قبل و بعد ممکن است شامل کد هسته Rust، کد کتابخانه استاندارد، یا جعبه(crate)هایی که استفاده میکنید باشند. بیایید با تنظیم متغیر محیطی RUST_BACKTRACE به هر مقداری به غیر از 0 یک backtrace دریافت کنیم. لیست ۹-۲ خروجی مشابه چیزی را که خواهید دید نشان میدهد.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
panic! که وقتی متغیر محیطی RUST_BACKTRACE تنظیم شده است نمایش داده میشوداین مقدار زیادی خروجی است! خروجی دقیق ممکن است بسته به سیستم عامل و نسخه Rust شما متفاوت باشد. برای دریافت backtraceها با این اطلاعات، باید نمادهای اشکالزدایی (debug symbols) فعال باشند. نمادهای اشکالزدایی به طور پیشفرض هنگام استفاده از cargo build یا cargo run بدون فلگ --release فعال هستند، همانطور که در اینجا انجام دادیم.
در خروجی لیست ۹-۲، خط ۶ از backtrace به خطی در پروژه ما اشاره میکند که باعث مشکل شده است: خط ۴ فایل src/main.rs. اگر نمیخواهیم برنامه ما دچار خطا شود، باید بررسی خود را از مکانی که توسط اولین خطی که اشاره به فایلی که نوشتهایم دارد، آغاز کنیم. در لیست ۹-۱، جایی که به عمد کدی نوشتهایم که باعث خطا شود، راه حل رفع این خطا این است که درخواست یک عنصر فراتر از محدوده اندیسهای بردار نکنیم. زمانی که کد شما در آینده دچار خطا میشود، باید بفهمید که کد با چه مقادیری چه عملی انجام میدهد که باعث خطا میشود و کد چه کاری باید انجام دهد.
ما در بخش “To panic! or Not to panic!” که بعداً در این فصل آمده است، دوباره به موضوع panic! و زمانی که باید و نباید از panic! برای مدیریت شرایط خطا استفاده کنیم بازخواهیم گشت. اکنون، به بررسی نحوه بازیابی از یک خطا با استفاده از Result میپردازیم.
خطاهای قابل بازیابی با Result
بیشتر خطاها به اندازهای جدی نیستند که نیاز به توقف کامل برنامه داشته باشند. گاهی اوقات وقتی یک تابع با شکست مواجه میشود، دلیلی وجود دارد که میتوانید آن را به راحتی تفسیر کرده و به آن پاسخ دهید. برای مثال، اگر بخواهید یک فایل را باز کنید و این عملیات به دلیل وجود نداشتن فایل شکست بخورد، ممکن است بخواهید فایل را ایجاد کنید به جای اینکه فرآیند را متوقف کنید.
به یاد بیاورید از بخش “Handling Potential Failure with Result”
در فصل ۲ که Result به صورت یک enum تعریف شده که دو حالت دارد، Ok و Err، به صورت زیر:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
T و E پارامترهای نوع جنریک هستند: ما درباره جنریکها به طور کاملتر در فصل ۱۰ صحبت خواهیم کرد.
چیزی که اکنون باید بدانید این است که T نمایانگر نوع مقداری است که در حالت موفقیت در داخل Ok
بازگردانده میشود، و E نمایانگر نوع خطایی است که در حالت شکست در داخل Err بازگردانده میشود.
زیرا Result این پارامترهای نوع جنریک را دارد، میتوانیم نوع Result و توابع تعریف شده روی آن را
در بسیاری از شرایط مختلف که مقادیر موفقیت و خطا ممکن است متفاوت باشند، استفاده کنیم.
بیایید تابعی را فراخوانی کنیم که یک مقدار Result را بازمیگرداند زیرا این تابع ممکن است با شکست
مواجه شود. در لیست ۹-۳ سعی میکنیم یک فایل را باز کنیم.
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); }
نوع بازگشتی File::open یک Result<T, E> است. پارامتر نوع جنریک T توسط پیادهسازی
File::open با نوع مقدار موفقیت، یعنی std::fs::File، که یک فایل هندل است، مقداردهی
شده است. نوع E استفاده شده در مقدار خطا std::io::Error است. این نوع بازگشتی به این معنی
است که فراخوانی File::open ممکن است موفقیتآمیز باشد و یک فایل هندل بازگرداند که میتوانیم از
آن برای خواندن یا نوشتن استفاده کنیم. همچنین ممکن است این فراخوانی با شکست مواجه شود: برای مثال،
فایل ممکن است وجود نداشته باشد یا ممکن است مجوز دسترسی به فایل را نداشته باشیم. تابع File::open
باید روشی داشته باشد تا به ما بگوید که آیا موفقیتآمیز بود یا شکست خورد و در عین حال فایل هندل یا
اطلاعات خطا را به ما بدهد. این اطلاعات دقیقاً همان چیزی است که enum Result منتقل میکند.
در حالتی که File::open موفقیتآمیز باشد، مقدار در متغیر greeting_file_result یک نمونه از Ok
خواهد بود که یک فایل هندل را شامل میشود. در حالتی که با شکست مواجه شود، مقدار در
greeting_file_result یک نمونه از Err خواهد بود که اطلاعات بیشتری در مورد نوع خطایی که رخ
داده است را شامل میشود.
باید به کد در لیست ۹-۳ اضافه کنیم تا اقدامات متفاوتی بسته به مقداری که File::open بازمیگرداند
انجام دهیم. لیست ۹-۴ یک روش برای مدیریت Result با استفاده از یک ابزار پایه، یعنی عبارت match
که در فصل ۶ مورد بحث قرار گرفت، نشان میدهد.
use std::fs::File; fn main() { let greeting_file_result = File::open("hello.txt"); let greeting_file = match greeting_file_result { Ok(file) => file, Err(error) => panic!("Problem opening the file: {error:?}"), }; }
match برای مدیریت حالتهای Result که ممکن است بازگردانده شودتوجه داشته باشید که مانند enum Option، enum Result و حالات آن به وسیله prelude به محدوده آورده شدهاند، بنابراین نیازی نیست قبل از حالات Ok و Err در بازوهای match از Result:: استفاده کنیم.
وقتی نتیجه Ok باشد، این کد مقدار داخلی file را از حالت Ok بازمیگرداند و سپس آن مقدار فایل هندل را به متغیر greeting_file اختصاص میدهیم. بعد از match، میتوانیم از فایل هندل برای خواندن یا نوشتن استفاده کنیم.
بازوی دیگر match حالت زمانی را مدیریت میکند که از File::open یک مقدار Err دریافت میکنیم. در این مثال، تصمیم گرفتهایم ماکروی panic! را فراخوانی کنیم. اگر فایل hello.txt در دایرکتوری فعلی ما وجود نداشته باشد و این کد را اجرا کنیم، خروجی زیر را از ماکروی panic! خواهیم دید:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
مثل همیشه، این خروجی دقیقاً به ما میگوید چه اشتباهی رخ داده است.
مطابقت بر اساس خطاهای مختلف
کد در لیست ۹-۴ در هر صورتی که File::open با شکست مواجه شود، ماکروی panic! را فراخوانی میکند. با این حال، ما میخواهیم اقدامات متفاوتی برای دلایل مختلف شکست انجام دهیم. اگر File::open به دلیل وجود نداشتن فایل شکست بخورد، میخواهیم فایل را ایجاد کنیم و هندل فایل جدید را بازگردانیم. اگر File::open به دلایل دیگری شکست بخورد—برای مثال، به دلیل نداشتن مجوز باز کردن فایل—همچنان میخواهیم کد مانند لیست ۹-۴ panic! کند. برای این کار، یک عبارت match داخلی اضافه میکنیم که در لیست ۹-۵ نشان داده شده است.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
_ => {
panic!("Problem opening the file: {error:?}");
}
},
};
}نوع مقداری که File::open درون حالت Err بازمیگرداند، io::Error است که یک ساختار داده ارائه شده توسط کتابخانه استاندارد است. این ساختار دارای متدی به نام kind است که میتوانیم آن را برای دریافت مقدار io::ErrorKind فراخوانی کنیم. enum io::ErrorKind توسط کتابخانه استاندارد ارائه شده و شامل حالتهایی است که انواع مختلف خطاهای ممکن در یک عملیات io را نمایش میدهد. حالتی که میخواهیم از آن استفاده کنیم ErrorKind::NotFound است که نشان میدهد فایل مورد نظر برای باز کردن هنوز وجود ندارد. بنابراین، ما بر روی greeting_file_result مطابقت میدهیم، اما همچنین یک match داخلی بر روی error.kind() داریم.
شرطی که میخواهیم در match داخلی بررسی کنیم این است که آیا مقدار بازگردانده شده توسط error.kind() همان حالت NotFound از enum ErrorKind است یا خیر. اگر چنین باشد، سعی میکنیم فایل را با File::create ایجاد کنیم. با این حال، از آنجایی که File::create نیز ممکن است شکست بخورد، به یک بازوی دوم در عبارت match داخلی نیاز داریم. هنگامی که فایل نمیتواند ایجاد شود، یک پیام خطای متفاوت چاپ میشود. بازوی دوم match بیرونی به همان شکل باقی میماند، بنابراین برنامه برای هر خطایی به جز خطای وجود نداشتن فایل، با خطا متوقف میشود.
جایگزینهایی برای استفاده از match با Result<T, E>
استفاده از match زیاد است! عبارت match بسیار مفید است اما همچنان ابتدایی محسوب میشود.
در فصل ۱۳، درباره closures یاد خواهید گرفت که در بسیاری از متدهایی که روی Result<T, E>
تعریف شدهاند استفاده میشوند. این متدها میتوانند هنگام مدیریت مقادیر Result<T, E> در کد شما،
مختصرتر از استفاده از match باشند.
برای مثال، در اینجا راه دیگری برای نوشتن همان منطق نشان داده شده در لیست ۹-۵ آورده شده است،
این بار با استفاده از closures و متد unwrap_or_else:
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file = File::open("hello.txt").unwrap_or_else(|error| {
if error.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|error| {
panic!("Problem creating the file: {error:?}");
})
} else {
panic!("Problem opening the file: {error:?}");
}
});
}اگرچه این کد همان رفتار لیست ۹-۵ را دارد، اما شامل هیچ عبارت match نیست و خواندن آن تمیزتر است.
بعد از خواندن فصل ۱۳، به این مثال بازگردید و متد unwrap_or_else را در مستندات کتابخانه استاندارد
بررسی کنید. بسیاری از این متدها میتوانند عبارتهای match تو در تو را هنگام کار با خطاها ساده کنند.
میانبرهایی برای توقف برنامه در صورت خطا: unwrap و expect
استفاده از match به اندازه کافی خوب کار میکند، اما ممکن است کمی طولانی باشد و همیشه به خوبی نیت
را منتقل نکند. نوع Result<T, E> دارای بسیاری از متدهای کمکی است که برای انجام وظایف خاصتر تعریف
شدهاند. متد unwrap یک روش میانبر است که دقیقاً مانند عبارت match که در لیست ۹-۴ نوشتیم،
پیادهسازی شده است. اگر مقدار Result در حالت Ok باشد، unwrap مقدار داخل Ok را بازمیگرداند.
اگر مقدار Result در حالت Err باشد، unwrap ماکروی panic! را برای ما فراخوانی میکند. در اینجا
یک مثال از استفاده از unwrap آورده شده است:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt").unwrap(); }
اگر این کد را بدون فایل hello.txt اجرا کنیم، یک پیام خطا از فراخوانی panic! که متد unwrap انجام
میدهد خواهیم دید:
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
به همین ترتیب، متد expect به ما اجازه میدهد پیام خطای ماکروی panic! را نیز انتخاب کنیم. استفاده
از expect به جای unwrap و ارائه پیامهای خطای خوب میتواند نیت شما را بهتر منتقل کند و پیگیری منبع
یک خطا را آسانتر کند. سینتکس expect به این شکل است:
use std::fs::File; fn main() { let greeting_file = File::open("hello.txt") .expect("hello.txt should be included in this project"); }
ما از expect به همان شیوهای استفاده میکنیم که از unwrap استفاده میکنیم: برای بازگرداندن فایل هندل یا فراخوانی ماکروی panic!. پیام خطایی که توسط expect در فراخوانی panic! استفاده میشود، پارامتری است که ما به expect میدهیم، به جای پیام پیشفرض panic! که توسط unwrap استفاده میشود. اینجا چیزی است که به نظر میرسد:
thread 'main' panicked at src/main.rs:5:10:
hello.txt should be included in this project: Os { code: 2, kind: NotFound, message: "No such file or directory" }
در کد با کیفیت تولید، بیشتر Rustaceanها expect را به جای unwrap انتخاب میکنند و اطلاعات بیشتری درباره اینکه چرا عملیات باید همیشه موفقیتآمیز باشد ارائه میدهند. به این ترتیب، اگر فرضیات شما هرگز اشتباه ثابت شوند، اطلاعات بیشتری برای استفاده در اشکالزدایی خواهید داشت.
انتشار خطاها (Propagating Errors)
وقتی پیادهسازی یک تابع چیزی را فراخوانی میکند که ممکن است شکست بخورد، بهجای آنکه خطا را درون خود تابع مدیریت کند، میتوانید آن خطا را به کدی که تابع را فراخوانی کرده برگردانید تا آن کد تصمیم بگیرد که چه کاری باید انجام شود. این روش به انتقال (propagating) خطا معروف است و کنترل بیشتری را به کد فراخواننده میدهد، جایی که ممکن است اطلاعات یا منطق بیشتری برای تصمیمگیری در مورد نحوهی مدیریت خطا وجود داشته باشد نسبت به آنچه در زمینهی تابع فعلی در دسترس است.
برای مثال، لیست ۹-۶ یک تابع را نشان میدهد که یک نام کاربری را از یک فایل میخواند. اگر فایل وجود نداشته باشد یا قابل خواندن نباشد، این تابع آن خطاها را به کدی که تابع را فراخوانی کرده بازمیگرداند.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let username_file_result = File::open("hello.txt"); let mut username_file = match username_file_result { Ok(file) => file, Err(e) => return Err(e), }; let mut username = String::new(); match username_file.read_to_string(&mut username) { Ok(_) => Ok(username), Err(e) => Err(e), } } }
matchاین تابع میتواند به روشی بسیار کوتاهتر نوشته شود، اما ما قرار است با انجام بسیاری از کارها به صورت دستی، مدیریت خطاها را بررسی کنیم. در انتها، راه کوتاهتر را نشان خواهیم داد. بیایید ابتدا به نوع بازگشتی تابع نگاه کنیم: Result<String, io::Error>. این به این معناست که تابع مقداری از نوع Result<T, E> بازمیگرداند، جایی که پارامتر جنریک T با نوع مشخص String مقداردهی شده است و نوع جنریک E با نوع مشخص io::Error.
اگر این تابع بدون هیچ مشکلی موفقیتآمیز باشد، کدی که این تابع را فراخوانی میکند یک مقدار Ok دریافت میکند که یک String را نگهداری میکند—نام کاربریای که این تابع از فایل خوانده است. اگر این تابع با مشکلی مواجه شود، کدی که آن را فراخوانی کرده است یک مقدار Err دریافت میکند که یک نمونه از io::Error را نگهداری میکند که اطلاعات بیشتری درباره مشکلاتی که رخ دادهاند شامل میشود. ما io::Error را به عنوان نوع بازگشتی این تابع انتخاب کردیم زیرا این همان نوعی است که مقدار خطا از هر دو عملیات فراخوانی شده در بدنه این تابع که ممکن است شکست بخورند بازمیگرداند: تابع File::open و متد read_to_string.
بدنه تابع با فراخوانی تابع File::open شروع میشود. سپس مقدار Result را با یک match مشابه
آنچه در لیست ۹-۴ دیدیم مدیریت میکنیم. اگر File::open موفق شود، هندل فایل در متغیر الگو file
به مقدار در متغیر قابل تغییر username_file تبدیل میشود و تابع ادامه مییابد. در حالت Err،
به جای فراخوانی panic!، از کلیدواژه return استفاده میکنیم تا زودتر از تابع خارج شویم و مقدار
خطا از File::open که اکنون در متغیر الگو e قرار دارد را به کدی که تابع را فراخوانی کرده بازگردانیم.
بنابراین، اگر یک هندل فایل در username_file داشته باشیم، تابع سپس یک String جدید در متغیر
username ایجاد کرده و متد read_to_string را روی هندل فایل در username_file فراخوانی میکند
تا محتوای فایل را در username بخواند. متد read_to_string نیز یک مقدار Result بازمیگرداند
زیرا ممکن است با شکست مواجه شود، حتی اگر File::open موفق بوده باشد. بنابراین، به یک match
دیگر برای مدیریت آن Result نیاز داریم: اگر read_to_string موفق شود، آنگاه تابع ما موفقیتآمیز
بوده و نام کاربری از فایل که اکنون در username است، درون یک Ok بازمیگرداند. اگر
read_to_string شکست بخورد، مقدار خطا را به همان شیوهای که مقدار خطا را در match که مقدار
بازگشتی File::open را مدیریت میکرد بازمیگردانیم. با این حال، نیازی نیست که به صراحت بگوییم
return، زیرا این آخرین عبارت در تابع است.
کدی که این تابع را فراخوانی میکند سپس مدیریت دریافت مقدار Ok که شامل یک نام کاربری است یا
مقدار Err که شامل یک io::Error است را انجام میدهد. این به کدی که تابع را فراخوانی میکند بستگی دارد
که تصمیم بگیرد با این مقادیر چه کاری انجام دهد. اگر کد فراخوانیکننده یک مقدار Err دریافت کند،
میتواند panic! را فراخوانی کرده و برنامه را متوقف کند، از یک نام کاربری پیشفرض استفاده کند، یا
به جای فایل نام کاربری را از مکان دیگری جستجو کند، برای مثال. ما اطلاعات کافی درباره اینکه کد فراخوانیکننده
دقیقاً چه میخواهد انجام دهد نداریم، بنابراین تمام اطلاعات موفقیت یا خطا را به بالا منتقل میکنیم
تا آن را به درستی مدیریت کند.
این الگوی انتشار خطاها در Rust آنقدر رایج است که Rust عملگر ? را برای آسانتر کردن این کار
فراهم میکند.
یک میانبر برای انتشار خطاها: عملگر ?
لیست ۹-۷ پیادهسازی read_username_from_file را نشان میدهد که همان عملکرد لیست ۹-۶ را دارد،
اما این پیادهسازی از عملگر ? استفاده میکند.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username_file = File::open("hello.txt")?; let mut username = String::new(); username_file.read_to_string(&mut username)?; Ok(username) } }
? بازمیگرداندعملگر ? که پس از یک مقدار Result قرار میگیرد تقریباً به همان شیوهای عمل میکند که عبارات
match که برای مدیریت مقادیر Result در لیست ۹-۶ تعریف کردیم. اگر مقدار Result در حالت
Ok باشد، مقدار درون Ok از این عبارت بازگردانده میشود و برنامه ادامه مییابد. اگر مقدار در حالت
Err باشد، مقدار Err از کل تابع بازگردانده میشود به گونهای که انگار کلیدواژه return را
استفاده کردهایم تا مقدار خطا به کد فراخوانیکننده منتقل شود.
تفاوتی بین کاری که عبارت match در لیست ۹-۶ انجام میدهد و کاری که عملگر ? انجام میدهد وجود
دارد: مقادیر خطا که عملگر ? روی آنها فراخوانی میشود از طریق تابع from که در ویژگی
From کتابخانه استاندارد تعریف شده است عبور میکنند، که برای تبدیل مقادیر از یک نوع به نوع دیگر
استفاده میشود. وقتی عملگر ? تابع from را فراخوانی میکند، نوع خطای دریافت شده به نوع خطای
تعریف شده در نوع بازگشتی تابع فعلی تبدیل میشود. این موضوع زمانی مفید است که یک تابع یک نوع خطا
را برای نمایش تمام راههایی که ممکن است یک تابع شکست بخورد بازگرداند، حتی اگر بخشهایی ممکن است
به دلایل بسیار مختلفی شکست بخورند.
برای مثال، میتوانیم تابع read_username_from_file در لیست ۹-۷ را تغییر دهیم تا یک نوع خطای سفارشی به نام OurError که تعریف کردهایم بازگرداند. اگر همچنین impl From<io::Error> for OurError را تعریف کنیم تا یک نمونه از OurError را از یک io::Error بسازد، سپس فراخوانیهای عملگر ? در بدنه تابع read_username_from_file تابع from را فراخوانی کرده و نوع خطاها را بدون نیاز به افزودن کد اضافی به تابع تبدیل میکنند.
در زمینه لیست ۹-۷، عملگر ? در انتهای فراخوانی File::open مقدار درون یک Ok را به متغیر username_file بازمیگرداند. اگر خطایی رخ دهد، عملگر ? زودتر از کل تابع خارج شده و هر مقدار Err را به کد فراخوانیکننده بازمیگرداند. همین موضوع برای عملگر ? در انتهای فراخوانی read_to_string صدق میکند.
عملگر ? مقدار زیادی از کد اضافی را حذف کرده و پیادهسازی این تابع را سادهتر میکند. حتی میتوانیم این کد را بیشتر کوتاه کنیم با زنجیره کردن فراخوانی متدها بلافاصله بعد از ?، همانطور که در لیست ۹-۸ نشان داده شده است.
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { let mut username = String::new(); File::open("hello.txt")?.read_to_string(&mut username)?; Ok(username) } }
?ما ایجاد String جدید در username را به ابتدای تابع منتقل کردهایم؛ آن قسمت تغییر نکرده است. به جای ایجاد یک متغیر username_file، ما فراخوانی read_to_string را مستقیماً به نتیجه File::open("hello.txt")? زنجیره کردهایم. همچنان یک عملگر ? در انتهای فراخوانی read_to_string داریم و همچنان مقدار Ok شامل username را زمانی که هر دو File::open و read_to_string موفق هستند بازمیگردانیم، به جای بازگرداندن خطاها. عملکرد دوباره همانند لیست ۹-۶ و لیست ۹-۷ است؛ این فقط یک روش متفاوت و کاربرپسندتر برای نوشتن آن است.
لیست ۹-۹ روشی برای کوتاهتر کردن این کد با استفاده از fs::read_to_string را نشان میدهد.
#![allow(unused)] fn main() { use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { fs::read_to_string("hello.txt") } }
fs::read_to_string به جای باز کردن و سپس خواندن فایلخواندن یک فایل به یک رشته یک عملیات نسبتاً رایج است، بنابراین کتابخانه استاندارد تابع مناسب fs::read_to_string را فراهم میکند که فایل را باز میکند، یک String جدید ایجاد میکند، محتوای فایل را میخواند، محتوا را در آن String قرار میدهد و آن را بازمیگرداند. البته، استفاده از fs::read_to_string به ما فرصتی برای توضیح تمام مدیریت خطاها نمیدهد، بنابراین ابتدا آن را به روش طولانیتر انجام دادیم.
جایی که میتوان از عملگر ? استفاده کرد
عملگر ? فقط در توابعی استفاده میشود که نوع بازگشتی آنها با مقدار استفاده شده توسط ? سازگار باشد. این به این دلیل است که عملگر ? برای بازگرداندن زودهنگام یک مقدار از تابع تعریف شده است، به همان شیوهای که عبارت match در لیست ۹-۶ تعریف شده است. در لیست ۹-۶، match از یک مقدار Result استفاده میکرد و بازوی بازگشتی زودهنگام یک مقدار Err(e) را بازمیگرداند. نوع بازگشتی تابع باید یک Result باشد تا با این بازگشت سازگار باشد.
در لیست ۹-۱۰، بیایید به خطایی که دریافت میکنیم وقتی که از عملگر ? در یک تابع main با نوع بازگشتیای که با نوع مقدار استفاده شده در ? سازگار نیست استفاده میکنیم نگاه کنیم.
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}? در تابع main که نوع بازگشتی آن () است و کامپایل نمیشود.این کد یک فایل را باز میکند، که ممکن است شکست بخورد. عملگر ? مقدار Result بازگردانده شده توسط File::open را دنبال میکند، اما این تابع main نوع بازگشتی () دارد، نه Result. وقتی این کد را کامپایل میکنیم، پیام خطای زیر را دریافت میکنیم:
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
= help: the trait `FromResidual<Result<Infallible, std::io::Error>>` is not implemented for `()`
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
این خطا نشان میدهد که فقط میتوان از عملگر ? در توابعی که نوع بازگشتی آنها Result، Option، یا نوع دیگری که FromResidual را پیادهسازی میکند استفاده کرد.
برای رفع این خطا، دو انتخاب دارید. یکی این است که نوع بازگشتی تابع خود را تغییر دهید تا با مقداری که از عملگر ? استفاده میکنید سازگار باشد، به شرطی که محدودیتی مانع از انجام این کار نداشته باشید. انتخاب دیگر این است که از یک match یا یکی از متدهای Result<T, E> برای مدیریت Result<T, E> به شیوهای که مناسب است استفاده کنید.
پیام خطا همچنین اشاره کرد که ? میتواند با مقادیر Option<T> نیز استفاده شود. همانند استفاده از ? روی Result، فقط میتوانید از ? روی Option در تابعی استفاده کنید که یک Option بازمیگرداند. رفتار عملگر ? وقتی روی یک Option<T> فراخوانی میشود شبیه به رفتار آن وقتی روی یک Result<T, E> فراخوانی میشود: اگر مقدار None باشد، None زودهنگام از تابع بازگردانده میشود. اگر مقدار Some باشد، مقدار داخل Some مقدار نتیجه عبارت است و تابع ادامه میدهد. لیست ۹-۱۱ مثالی از تابعی را نشان میدهد که آخرین کاراکتر خط اول متن داده شده را پیدا میکند.
fn last_char_of_first_line(text: &str) -> Option<char> { text.lines().next()?.chars().last() } fn main() { assert_eq!( last_char_of_first_line("Hello, world\nHow are you today?"), Some('d') ); assert_eq!(last_char_of_first_line(""), None); assert_eq!(last_char_of_first_line("\nhi"), None); }
? روی یک مقدار Option<T>این تابع Option<char> بازمیگرداند زیرا ممکن است یک کاراکتر وجود داشته باشد، اما ممکن است وجود نداشته باشد. این کد آرگومان قطعه رشته text را میگیرد و متد lines را روی آن فراخوانی میکند، که یک iterator روی خطوط درون رشته بازمیگرداند. چون این تابع میخواهد خط اول را بررسی کند، next را روی iterator فراخوانی میکند تا اولین مقدار از iterator را دریافت کند. اگر text رشتهای خالی باشد، این فراخوانی به next مقدار None بازمیگرداند، که در این صورت از ? برای متوقف کردن و بازگرداندن None از last_char_of_first_line استفاده میکنیم. اگر text رشته خالی نباشد، next یک مقدار Some شامل یک قطعه رشته از خط اول در text بازمیگرداند.
عملگر ? قطعه رشته را استخراج میکند و میتوانیم متد chars را روی آن فراخوانی کنیم تا یک iterator از کاراکترهای آن دریافت کنیم. ما به آخرین کاراکتر در این خط اول علاقهمند هستیم، بنابراین متد last را فراخوانی میکنیم تا آخرین مورد در iterator را بازگرداند. این یک Option است زیرا ممکن است خط اول رشتهای خالی باشد؛ برای مثال، اگر text با یک خط خالی شروع شود اما کاراکترهایی در خطوط دیگر داشته باشد، مانند "\nhi". با این حال، اگر آخرین کاراکتری در خط اول وجود داشته باشد، در حالت Some بازگردانده میشود. عملگر ? در میانه به ما راهی مختصر برای بیان این منطق میدهد و اجازه میدهد تابع را در یک خط پیادهسازی کنیم. اگر نمیتوانستیم از عملگر ? روی Option استفاده کنیم، باید این منطق را با فراخوانی متدهای بیشتر یا یک عبارت match پیادهسازی میکردیم.
توجه داشته باشید که میتوانید از عملگر ? روی یک Result در یک تابع که یک Result بازمیگرداند استفاده کنید، و میتوانید از عملگر ? روی یک Option در یک تابع که یک Option بازمیگرداند استفاده کنید، اما نمیتوانید این دو را با هم ترکیب کنید. عملگر ? به طور خودکار یک Result را به یک Option یا برعکس تبدیل نمیکند؛ در این موارد، میتوانید از متدهایی مانند ok روی Result یا ok_or روی Option برای تبدیل صریح استفاده کنید.
تا کنون، تمام توابع main که استفاده کردهایم مقدار () بازمیگرداندند. تابع main خاص است زیرا نقطه ورود و خروج یک برنامه اجرایی است، و محدودیتهایی در نوع بازگشتی آن وجود دارد تا برنامه همانطور که انتظار میرود رفتار کند.
خوشبختانه، main میتواند یک Result<(), E> نیز بازگرداند. لیست ۹-۱۲ کد لیست ۹-۱۰ را دارد، اما نوع بازگشتی main را به Result<(), Box<dyn Error>> تغییر دادهایم و یک مقدار بازگشتی Ok(()) به انتهای آن اضافه کردهایم. این کد اکنون کامپایل میشود.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}main برای بازگرداندن Result<(), E> اجازه میدهد از عملگر ? روی مقادیر Result استفاده شود.نوع Box<dyn Error> یک trait object است،
که در فصل ۱۸ در بخش “استفاده از Trait Objectها برای مقادیر با انواع متفاوت”
دربارهی آن صحبت خواهیم کرد.
فعلاً میتوانید Box<dyn Error> را به معنای «هر نوع خطایی» در نظر بگیرید.
استفاده از ? روی یک مقدار Result در تابع main با نوع خطای Box<dyn Error> مجاز است،
زیرا این امکان را میدهد که هر مقدار Err زودتر بازگردانده شود.
حتی اگر بدنهی این تابع main فقط خطاهایی از نوع std::io::Error بازگرداند،
با مشخص کردن Box<dyn Error> در امضا، این امضا همچنان معتبر باقی خواهد ماند
حتی اگر بعداً کدی به main اضافه شود که خطاهای دیگری را بازمیگرداند.
وقتی یک تابع main یک Result<(), E> بازمیگرداند، برنامه اجرایی با مقدار 0 خارج میشود اگر main مقدار Ok(()) بازگرداند و با یک مقدار غیر صفر خارج میشود اگر main مقدار Err بازگرداند. برنامههای اجرایی نوشته شده در C هنگام خروج مقادیر صحیح بازمیگردانند: برنامههایی که با موفقیت خارج میشوند مقدار صحیح 0 را بازمیگردانند و برنامههایی که دچار خطا میشوند مقداری غیر از 0 بازمیگردانند. Rust نیز مقادیر صحیح را از برنامههای اجرایی بازمیگرداند تا با این قرارداد سازگار باشد.
تابع main میتواند هر نوعی را که ویژگی std::process::Termination را پیادهسازی میکند بازگرداند، که شامل تابع report است که یک ExitCode بازمیگرداند. مستندات کتابخانه استاندارد را برای اطلاعات بیشتر درباره پیادهسازی ویژگی Termination برای انواع خودتان مطالعه کنید.
اکنون که جزئیات فراخوانی panic! یا بازگرداندن Result را بررسی کردیم، بیایید به موضوع نحوه تصمیمگیری درباره اینکه کدامیک در چه مواردی مناسب است بازگردیم.
آیا باید از panic! استفاده کنیم یا نه؟
چگونه تصمیم میگیرید که چه زمانی باید panic! را فراخوانی کنید و چه زمانی باید یک Result بازگردانید؟ وقتی کد دچار خطا میشود، هیچ راهی برای بازیابی وجود ندارد. شما میتوانید در هر وضعیت خطایی، چه قابل بازیابی باشد و چه نباشد، panic! را فراخوانی کنید، اما در این صورت، شما به جای کد فراخوانیکننده تصمیم میگیرید که وضعیت غیرقابل بازیابی است. وقتی تصمیم میگیرید یک مقدار Result بازگردانید، به کد فراخوانیکننده گزینههایی میدهید. کد فراخوانیکننده میتواند انتخاب کند که تلاش کند خطا را به روشی که برای وضعیت خودش مناسب است بازیابی کند، یا میتواند تصمیم بگیرد که مقدار Err در این مورد غیرقابل بازیابی است و بنابراین panic! را فراخوانی کرده و خطای قابل بازیابی شما را به یک خطای غیرقابل بازیابی تبدیل کند. بنابراین، بازگرداندن Result یک انتخاب پیشفرض خوب است وقتی تابعی تعریف میکنید که ممکن است شکست بخورد.
در وضعیتهایی مانند مثالها، کد نمونهسازی (prototype) و آزمونها، مناسبتر است که کدی بنویسید که متوقف شود به جای بازگرداندن یک Result. بیایید بررسی کنیم چرا، سپس وضعیتهایی را بحث کنیم که کامپایلر نمیتواند بفهمد که شکست غیرممکن است، اما شما به عنوان یک انسان میتوانید. این فصل با برخی دستورالعملهای کلی درباره تصمیمگیری درباره اینکه آیا در کد کتابخانه باید از panic! استفاده کرد یا نه، به پایان خواهد رسید.
مثالها، کد نمونهسازی، و آزمونها
وقتی مثالی مینویسید تا یک مفهوم را توضیح دهید، همچنین افزودن کد مدیریت خطای قدرتمند میتواند مثال را کمتر واضح کند. در مثالها، این نکته فهمیده میشود که فراخوانی به متدی مانند unwrap که ممکن است متوقف شود، به عنوان یک جایگزین برای روشی که میخواهید برنامه شما خطاها را مدیریت کند در نظر گرفته میشود، که میتواند بسته به آنچه بقیه کد شما انجام میدهد متفاوت باشد.
به همین ترتیب، متدهای unwrap و expect بسیار مفید هستند وقتی که در حال نمونهسازی هستید و هنوز تصمیم نگرفتهاید که چگونه خطاها را مدیریت کنید. آنها نشانههای واضحی در کد شما میگذارند برای زمانی که آماده باشید برنامه خود را قدرتمندتر کنید.
اگر یک متد در یک آزمون شکست بخورد، میخواهید کل آزمون شکست بخورد، حتی اگر آن متد ویژگیای که تحت آزمون قرار دارد نباشد. از آنجا که panic! راهی است که یک آزمون به عنوان شکستخورده علامتگذاری میشود، فراخوانی unwrap یا expect دقیقاً همان چیزی است که باید اتفاق بیفتد.
مواردی که شما اطلاعات بیشتری نسبت به کامپایلر دارید
در زمانی که منطق دیگری در برنامه شما وجود دارد که تضمین میکند مقدار Result از نوع Ok خواهد بود،
اما این منطق چیزی نیست که کامپایلر بتواند آن را درک کند،
استفاده از expect نیز مناسب خواهد بود.
شما همچنان با یک مقدار Result مواجه هستید که باید آن را مدیریت کنید:
عملیاتی که فراخوانی میکنید بهصورت کلی ممکن است شکست بخورد،
حتی اگر در موقعیت خاص شما از نظر منطقی وقوع خطا غیرممکن باشد.
اگر با بررسی دستی کد بتوانید اطمینان حاصل کنید که هیچگاه با واریانت Err روبهرو نخواهید شد،
استفاده از expect کاملاً قابلقبول است،
به شرط آنکه دلیل این اطمینان خود را در قالب متن آرگومان expect مستندسازی کنید.
در اینجا یک مثال آورده شده است:
fn main() { use std::net::IpAddr; let home: IpAddr = "127.0.0.1" .parse() .expect("Hardcoded IP address should be valid"); }
ما یک نمونه IpAddr را با تجزیه یک رشته ثابتشده ایجاد میکنیم. ما میتوانیم ببینیم که 127.0.0.1 یک آدرس IP معتبر است، بنابراین استفاده از expect در اینجا قابل قبول است. با این حال، داشتن یک رشته ثابتشده و معتبر نوع بازگشتی متد parse را تغییر نمیدهد: ما همچنان یک مقدار Result دریافت میکنیم و کامپایلر همچنان ما را مجبور میکند که با Result برخورد کنیم، انگار که حالت Err ممکن است، زیرا کامپایلر به اندازه کافی هوشمند نیست تا ببیند این رشته همیشه یک آدرس IP معتبر است. اگر رشته آدرس IP از یک کاربر میآمد به جای اینکه در برنامه ثابت شده باشد و بنابراین امکان شکست وجود داشت، قطعاً میخواستیم که Result را به روشی قدرتمندتر مدیریت کنیم. اشاره به این فرض که این آدرس IP ثابتشده است، ما را ترغیب میکند که در صورت نیاز به دریافت آدرس IP از منبع دیگری در آینده، expect را به کد مدیریت خطای بهتر تغییر دهیم.
دستورالعملهایی برای مدیریت خطاها
توصیه میشود که کد شما زمانی که ممکن است به وضعیت نامناسبی برسد، دچار panic! شود. در این زمینه، یک وضعیت نامناسب زمانی رخ میدهد که برخی فرضیات، تضمینها، قراردادها، یا تغییرناپذیریها شکسته شوند، مانند زمانی که مقادیر نامعتبر، مقادیر متناقض، یا مقادیر گمشده به کد شما پاس داده میشوند—به علاوه یکی یا بیشتر از شرایط زیر:
- وضعیت نادرست (bad state) چیزی غیرمنتظره است، بر خلاف موقعیتهایی که احتمالاً گاهی اتفاق میافتند، مانند وارد کردن داده با فرمت نادرست توسط کاربر.
- کد شما پس از این نقطه باید به نبودن در چنین وضعیت نادرستی تکیه کند، بهجای آنکه در هر مرحله مشکل را بررسی کند.
- راه مناسبی برای رمزگذاری این اطلاعات در قالب typeهایی که استفاده میکنید وجود ندارد. در فصل ۱۸، در بخش “رمزگذاری وضعیتها و رفتارها بهصورت type” با مثالی منظور خود را توضیح خواهیم داد.
اگر کسی کد شما را فراخوانی کند و مقادیری که منطقی نیستند را پاس دهد، بهتر است که یک خطا بازگردانید تا کاربر کتابخانه بتواند تصمیم بگیرد که در آن مورد چه کاری انجام دهد. با این حال، در مواردی که ادامه دادن میتواند ناامن یا مضر باشد، بهترین انتخاب ممکن است فراخوانی panic! و هشدار به شخصی که از کتابخانه شما استفاده میکند درباره باگ در کد آنها باشد تا بتوانند آن را در حین توسعه رفع کنند. به همین ترتیب، panic! اغلب مناسب است اگر کد خارجی که از کنترل شما خارج است را فراخوانی میکنید و آن کد یک وضعیت نامعتبر بازمیگرداند که شما هیچ راهی برای رفع آن ندارید.
با این حال، زمانی که شکست مورد انتظار است، مناسبتر است که یک Result بازگردانید تا یک فراخوانی panic!. مثالها شامل پردازشی هستند که دادههای نادرست دریافت میکند یا یک درخواست HTTP که بازگشت وضعیت نشان میدهد که به محدودیت نرخ برخورد کردهاید. در این موارد، بازگرداندن یک Result نشان میدهد که شکست یک احتمال مورد انتظار است که کد فراخوانیکننده باید تصمیم بگیرد چگونه آن را مدیریت کند.
وقتی کد شما عملیاتی انجام میدهد که میتواند در صورت فراخوانی با مقادیر نامعتبر کاربر را در معرض خطر قرار دهد، کد شما باید ابتدا مقادیر را تأیید کند و اگر مقادیر نامعتبر هستند دچار panic! شود. این بیشتر به دلایل ایمنی است: تلاش برای انجام عملیات روی دادههای نامعتبر میتواند کد شما را در معرض آسیبپذیریها قرار دهد. این دلیل اصلی است که کتابخانه استاندارد اگر شما تلاش کنید به حافظه خارج از محدوده دسترسی پیدا کنید، دچار panic! میشود: تلاش برای دسترسی به حافظهای که به ساختار داده جاری تعلق ندارد یک مشکل امنیتی رایج است. توابع اغلب قراردادهایی دارند: رفتار آنها فقط در صورتی تضمین میشود که ورودیها نیازمندیهای خاصی را برآورده کنند. دچار panic! شدن وقتی که قرارداد نقض میشود منطقی است زیرا نقض قرارداد همیشه نشاندهنده یک باگ در طرف فراخوانیکننده است و نوع خطایی نیست که بخواهید کد فراخوانیکننده به طور صریح مدیریت کند. در واقع، هیچ راه معقولی برای بازیابی کد فراخوانیکننده وجود ندارد؛ برنامهنویسان فراخوانیکننده باید کد را اصلاح کنند. قراردادهای یک تابع، به خصوص زمانی که نقض آن باعث panic! میشود، باید در مستندات API تابع توضیح داده شوند.
با این حال، داشتن بررسیهای خطا در تمام توابع شما بسیار طولانی و ناخوشایند خواهد بود. خوشبختانه، شما میتوانید از سیستم نوع Rust (و در نتیجه بررسی نوعی که توسط کامپایلر انجام میشود) برای انجام بسیاری از بررسیها استفاده کنید. اگر تابع شما یک نوع خاص را به عنوان پارامتر داشته باشد، میتوانید با اطمینان از اینکه کامپایلر قبلاً تضمین کرده است که یک مقدار معتبر دارید، منطق کد خود را پیش ببرید. برای مثال، اگر شما یک نوع به جای یک Option داشته باشید، برنامه شما انتظار دارد که چیزی به جای هیچچیز وجود داشته باشد. سپس کد شما نیازی به مدیریت دو حالت برای حالتهای Some و None ندارد: فقط یک حالت برای داشتن یک مقدار به طور قطعی خواهد داشت. کدی که سعی میکند هیچچیز به تابع شما پاس دهد حتی کامپایل نخواهد شد، بنابراین تابع شما نیازی به بررسی این حالت در زمان اجرا ندارد. مثال دیگر استفاده از یک نوع عددی بدون علامت مانند u32 است که تضمین میکند پارامتر هرگز منفی نخواهد بود.
ایجاد انواع سفارشی برای اعتبارسنجی
بیایید ایده استفاده از سیستم نوع Rust برای اطمینان از داشتن یک مقدار معتبر را یک قدم فراتر ببریم و به ایجاد یک نوع سفارشی برای اعتبارسنجی نگاه کنیم. بازی حدس عدد در فصل ۲ را به یاد بیاورید که کد ما از کاربر خواست تا یک عدد بین ۱ تا ۱۰۰ حدس بزند. ما هرگز اعتبارسنجی نکردیم که حدس کاربر بین این اعداد باشد قبل از اینکه آن را با عدد مخفی مقایسه کنیم؛ فقط بررسی کردیم که حدس مثبت باشد. در این مورد، پیامدها چندان شدید نبودند: خروجی ما با پیامهای “خیلی بزرگ” یا “خیلی کوچک” همچنان درست بود. اما این میتواند بهبودی مفید باشد که کاربر را به سمت حدسهای معتبر هدایت کنیم و رفتار متفاوتی داشته باشیم وقتی کاربر عددی خارج از محدوده حدس میزند در مقابل زمانی که، برای مثال، حروف تایپ میکند.
یک راه برای انجام این کار این است که حدس را به جای فقط یک u32، به صورت یک i32 تجزیه کنیم تا اجازه دهیم اعداد منفی نیز در نظر گرفته شوند، و سپس یک بررسی برای اینکه عدد در محدوده است یا نه اضافه کنیم، مانند زیر:
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}عبارت if بررسی میکند که آیا مقدار ما خارج از محدوده است، به کاربر درباره مشکل اطلاع میدهد و continue را فراخوانی میکند تا تکرار بعدی حلقه شروع شود و درخواست یک حدس دیگر شود. بعد از عبارت if، میتوانیم با مقایسه بین guess و عدد مخفی ادامه دهیم، زیرا میدانیم که guess بین ۱ و ۱۰۰ است.
با این حال، این یک راهحل ایدهآل نیست: اگر بسیار حیاتی باشد که برنامه فقط بر روی مقادیر بین ۱ و ۱۰۰ عمل کند، و برنامه توابع زیادی با این نیاز داشته باشد، داشتن چنین بررسیهایی در هر تابع خستهکننده خواهد بود (و ممکن است عملکرد را تحت تأثیر قرار دهد).
در عوض، میتوانیم یک نوع جدید در یک ماژول اختصاصی تعریف کنیم
و اعتبارسنجیها (validations) را در تابعی قرار دهیم که وظیفهی ایجاد یک نمونه از آن نوع را دارد،
بهجای آنکه این اعتبارسنجیها را در همهجا تکرار کنیم.
به این ترتیب، استفاده از این نوع جدید در امضای توابع ایمن خواهد بود
و میتوان با اطمینان از مقادیری که دریافت میکنند استفاده کرد.
لیستینگ 9-13 یک روش برای تعریف نوع Guess را نشان میدهد
که تنها زمانی یک نمونه از Guess ایجاد میکند که تابع new مقداری بین 1 تا 100 دریافت کرده باشد.
#![allow(unused)] fn main() { pub struct Guess { value: i32, } impl Guess { pub fn new(value: i32) -> Guess { if value < 1 || value > 100 { panic!("Guess value must be between 1 and 100, got {value}."); } Guess { value } } pub fn value(&self) -> i32 { self.value } } }
Guess که تنها با مقادیری بین 1 تا 100 ادامه میدهدتوجه داشته باشید که این کد در فایل src/guessing_game.rs
بستگی به اضافه کردن یک اعلان ماژول به شکل mod guessing_game; در فایل src/lib.rs دارد
که در اینجا نشان داده نشده است.
درون فایل این ماژول جدید، یک struct به نام Guess تعریف کردهایم
که در همان ماژول قرار دارد و دارای یک فیلد به نام value است که یک مقدار از نوع i32 را نگه میدارد.
این همان مکانی است که عدد در آن ذخیره خواهد شد.
سپس یک تابع وابسته به نام new روی Guess پیادهسازی میکنیم که نمونههایی از مقادیر Guess ایجاد میکند. تابع new به گونهای تعریف شده که یک پارامتر به نام value از نوع i32 داشته باشد و یک Guess بازگرداند. کدی که در بدنه تابع new قرار دارد مقدار value را بررسی میکند تا مطمئن شود که بین ۱ و ۱۰۰ است. اگر مقدار value این آزمون را پاس نکند، یک فراخوانی به panic! انجام میدهیم، که به برنامهنویسی که کد فراخوانیکننده را مینویسد هشدار میدهد که باگی دارد که باید برطرف کند، زیرا ایجاد یک Guess با مقدار value خارج از این محدوده قرارداد تابع Guess::new را نقض میکند. شرایطی که ممکن است باعث panic! در Guess::new شود باید در مستندات عمومی API آن مورد بحث قرار گیرد؛ ما در فصل ۱۴ درباره قراردادهای مستندات که نشاندهنده احتمال وقوع panic! هستند صحبت خواهیم کرد. اگر مقدار value آزمون را پاس کند، یک Guess جدید با فیلد value تنظیم شده به پارامتر value ایجاد میکنیم و Guess را بازمیگردانیم.
در مرحلهی بعد، متدی به نام value پیادهسازی میکنیم که self را بهصورت رفرنس قرض میگیرد،
پارامتر دیگری ندارد، و یک مقدار i32 بازمیگرداند.
این نوع متد گاهی getter نامیده میشود، زیرا هدف آن دریافت دادهای از فیلدهای ساختار و بازگرداندن آن است.
این متد عمومی لازم است چون فیلد value در struct مربوط به Guess خصوصی است.
خصوصی بودن فیلد value اهمیت دارد تا کدی که از struct Guess استفاده میکند،
اجازه نداشته باشد مستقیماً value را مقداردهی کند:
کد خارج از ماژول guessing_game باید از تابع Guess::new برای ساخت نمونهای از Guess استفاده کند،
و به این ترتیب، اطمینان حاصل میشود که هیچ راهی برای ساخت یک Guess با مقدار valueای
که بررسیهای موجود در تابع Guess::new را نگذرانده، وجود ندارد.
تابعی که یک پارامتر میگیرد یا فقط اعدادی بین ۱ و ۱۰۰ بازمیگرداند میتواند در امضای خود اعلام کند که یک Guess میگیرد یا بازمیگرداند به جای یک i32 و نیازی به انجام بررسیهای اضافی در بدنه خود ندارد.
خلاصه
ویژگیهای مدیریت خطای Rust طراحی شدهاند تا به شما کمک کنند کدی قدرتمندتر بنویسید. ماکروی panic! نشان میدهد که برنامه شما در حالتی قرار دارد که نمیتواند آن را مدیریت کند و به شما امکان میدهد فرآیند را متوقف کنید به جای اینکه سعی کنید با مقادیر نامعتبر یا نادرست ادامه دهید. Enum Result از سیستم نوع Rust استفاده میکند تا نشان دهد که عملیات ممکن است به روشی شکست بخورد که کد شما میتواند از آن بازیابی کند. میتوانید از Result برای اطلاع دادن به کدی که کد شما را فراخوانی میکند استفاده کنید که باید موفقیت یا شکست احتمالی را نیز مدیریت کند. استفاده از panic! و Result در شرایط مناسب باعث میشود کد شما در برابر مشکلات اجتنابناپذیر قابل اطمینانتر شود.
حالا که راههای مفید استفاده کتابخانه استاندارد از جنریکها با Enums Option و Result را دیدهاید، درباره نحوه عملکرد جنریکها و نحوه استفاده از آنها در کد خود صحبت خواهیم کرد.
انواع جنریک، ویژگیها (Traits)، و طول عمرها (Lifetimes)
هر زبان برنامهنویسی ابزارهایی برای مدیریت موثر تکرار مفاهیم دارد. در Rust، یکی از این ابزارها جنریکها هستند: جایگزینهای انتزاعی برای انواع مشخص یا ویژگیهای دیگر. ما میتوانیم رفتار جنریکها یا نحوه ارتباط آنها با جنریکهای دیگر را بیان کنیم بدون اینکه بدانیم هنگام کامپایل و اجرای کد چه چیزی جایگزین آنها خواهد شد.
توابع میتوانند پارامترهایی از نوع جنریک بگیرند، به جای یک نوع مشخص مانند i32 یا String، به همان روشی که پارامترهایی با مقادیر ناشناخته میگیرند تا بتوانند کد مشابهی را روی مقادیر مشخص مختلف اجرا کنند. در واقع، ما قبلاً در فصل ۶ با Option<T>، در فصل ۸ با Vec<T> و HashMap<K, V>، و در فصل ۹ با Result<T, E> از جنریکها استفاده کردهایم. در این فصل، یاد خواهید گرفت که چگونه انواع، توابع، و متدهای خود را با جنریکها تعریف کنید!
ابتدا نحوه استخراج یک تابع برای کاهش تکرار کد را مرور میکنیم. سپس از همان تکنیک برای ایجاد یک تابع جنریک از دو تابع که تنها در نوع پارامترهایشان متفاوت هستند استفاده خواهیم کرد. همچنین توضیح خواهیم داد که چگونه میتوان از انواع جنریک در تعریف ساختار دادهها (struct) و شمارشها (enum) استفاده کرد.
سپس یاد میگیرید که چگونه از ویژگیها (Traits) برای تعریف رفتار به صورت جنریک استفاده کنید. میتوانید ویژگیها را با انواع جنریک ترکیب کنید تا نوع جنریک را محدود کنید که فقط آن نوعهایی را بپذیرد که رفتار خاصی دارند، به جای هر نوعی.
در نهایت، درباره طول عمرها (Lifetimes) صحبت خواهیم کرد: نوعی از جنریکها که به کامپایلر اطلاعاتی درباره نحوه ارتباط مراجع با یکدیگر میدهند. طول عمرها به ما اجازه میدهند اطلاعات کافی درباره مقادیر قرض گرفته شده به کامپایلر بدهیم تا اطمینان حاصل کند که مراجع در شرایط بیشتری معتبر خواهند بود.
حذف تکرار با استخراج یک تابع
جنریکها به ما اجازه میدهند که نوعهای مشخص را با یک جایگزین که نمایانگر چندین نوع است جایگزین کنیم تا تکرار کد را حذف کنیم. قبل از ورود به نحو جنریکها، ابتدا به نحوه حذف تکرار به روشی که شامل انواع جنریک نمیشود، با استخراج یک تابع که مقادیر مشخص را با یک جایگزین که نمایانگر مقادیر چندگانه است جایگزین میکند، نگاه خواهیم کرد. سپس از همان تکنیک برای استخراج یک تابع جنریک استفاده خواهیم کرد! با بررسی نحوه تشخیص کد تکراری که میتوانید به یک تابع استخراج کنید، شروع به تشخیص کد تکراری خواهید کرد که میتواند از جنریکها استفاده کند.
با برنامه کوتاه در لیست ۱۰-۱ که بزرگترین عدد را در یک لیست پیدا میکند، شروع میکنیم.
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); assert_eq!(*largest, 100); }
ما یک لیست از اعداد صحیح را در متغیر number_list ذخیره میکنیم و یک مرجع به اولین عدد در لیست را در متغیری به نام largest قرار میدهیم. سپس تمام اعداد لیست را پیمایش میکنیم و اگر عدد فعلی بزرگتر از عدد ذخیره شده در largest باشد، مرجع در آن متغیر را جایگزین میکنیم. با این حال، اگر عدد فعلی کوچکتر یا مساوی با بزرگترین عدد دیده شده تاکنون باشد، متغیر تغییری نمیکند و کد به عدد بعدی در لیست میرود. پس از بررسی تمام اعداد در لیست، largest باید به بزرگترین عدد اشاره کند که در این مورد ۱۰۰ است.
اکنون از ما خواسته شده است که بزرگترین عدد را در دو لیست مختلف اعداد پیدا کنیم. برای انجام این کار، میتوانیم انتخاب کنیم که کد در لیست ۱۰-۱ را تکرار کنیم و از همان منطق در دو مکان مختلف در برنامه استفاده کنیم، همانطور که در لیست ۱۰-۲ نشان داده شده است.
fn main() { let number_list = vec![34, 50, 25, 100, 65]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let mut largest = &number_list[0]; for number in &number_list { if number > largest { largest = number; } } println!("The largest number is {largest}"); }
اگرچه این کد کار میکند، تکرار کد خستهکننده و مستعد خطاست. همچنین وقتی بخواهیم کد را تغییر دهیم، باید به یاد داشته باشیم که آن را در مکانهای مختلف بهروزرسانی کنیم.
برای حذف این تکرار، یک انتزاع ایجاد خواهیم کرد با تعریف یک تابع که روی هر لیستی از اعداد صحیح که به عنوان پارامتر پاس داده میشود عمل میکند. این راهحل کد ما را واضحتر میکند و به ما اجازه میدهد مفهوم یافتن بزرگترین عدد در یک لیست را به صورت انتزاعی بیان کنیم.
در لیست ۱۰-۳، کدی که بزرگترین عدد را پیدا میکند در تابعی به نام largest استخراج میکنیم. سپس این تابع را فراخوانی میکنیم تا بزرگترین عدد را در دو لیست از لیست ۱۰-۲ پیدا کنیم. همچنین میتوانیم از این تابع روی هر لیست دیگری از مقادیر i32 که ممکن است در آینده داشته باشیم استفاده کنیم.
fn largest(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8]; let result = largest(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 6000); }
تابع largest یک پارامتر به نام list دارد که نمایانگر هر بخش مشخصی از مقادیر i32 است که ممکن است به تابع پاس دهیم. در نتیجه، وقتی تابع را فراخوانی میکنیم، کد روی مقادیر مشخصی که پاس میدهیم اجرا میشود.
به طور خلاصه، مراحل زیر را برای تغییر کد از لیست ۱۰-۲ به لیست ۱۰-۳ طی کردیم:
- کد تکراری را شناسایی کنید.
- کد تکراری را به بدنه یک تابع استخراج کرده و ورودیها و مقادیر بازگشتی آن کد را در امضای تابع مشخص کنید.
- دو نمونه از کد تکراری را به جای آن با فراخوانی تابع بهروزرسانی کنید.
در مرحله بعد، از همین مراحل با جنریکها برای کاهش تکرار کد استفاده خواهیم کرد. همانطور که بدنه تابع میتواند روی یک list انتزاعی به جای مقادیر مشخص عمل کند، جنریکها به کد اجازه میدهند که روی انواع انتزاعی عمل کند.
برای مثال، فرض کنید دو تابع داشتیم: یکی که بزرگترین مورد را در یک بخش از مقادیر i32 پیدا میکند و دیگری که بزرگترین مورد را در یک بخش از مقادیر char پیدا میکند. چگونه میتوانیم این تکرار را حذف کنیم؟ بیایید پیدا کنیم!
انواع داده جنریک
ما از جنریکها برای ایجاد تعریفهایی برای مواردی مانند امضای توابع یا ساختارها (struct) استفاده میکنیم، که سپس میتوانیم با انواع داده مشخص مختلف از آنها استفاده کنیم. بیایید ابتدا ببینیم چگونه میتوان توابع، ساختارها، شمارشها (enum)، و متدها را با استفاده از جنریکها تعریف کرد. سپس درباره اینکه جنریکها چگونه بر عملکرد کد تأثیر میگذارند صحبت خواهیم کرد.
در تعریف توابع
هنگام تعریف یک تابع که از جنریکها استفاده میکند، جنریکها را در امضای تابع قرار میدهیم، جایی که معمولاً نوع داده پارامترها و مقدار بازگشتی را مشخص میکنیم. این کار کد ما را انعطافپذیرتر میکند و به فراخوانیکنندگان تابع ما عملکرد بیشتری ارائه میدهد، در حالی که از تکرار کد جلوگیری میکند.
با ادامه تابع largest، لیست ۱۰-۴ دو تابع را نشان میدهد که هر دو بزرگترین مقدار را در یک بخش (slice) پیدا میکنند. سپس اینها را به یک تابع واحد که از جنریکها استفاده میکند ترکیب خواهیم کرد.
fn largest_i32(list: &[i32]) -> &i32 { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn largest_char(list: &[char]) -> &char { let mut largest = &list[0]; for item in list { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest_i32(&number_list); println!("The largest number is {result}"); assert_eq!(*result, 100); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest_char(&char_list); println!("The largest char is {result}"); assert_eq!(*result, 'y'); }
تابع largest_i32 همان تابعی است که در لیست ۱۰-۳ استخراج کردیم و بزرگترین مقدار i32 را در یک بخش پیدا میکند. تابع largest_char بزرگترین مقدار char را در یک بخش پیدا میکند. بدنه توابع دارای کد یکسانی هستند، بنابراین با معرفی یک پارامتر نوع جنریک در یک تابع واحد، تکرار را حذف میکنیم.
برای پارامتریسازی نوعها در یک تابع جدید، باید همانطور که برای پارامترهای مقداری (value parameters) نام مشخص میکنیم،
برای پارامتر نوع نیز یک نام تعیین کنیم.
میتوانید از هر شناسهای به عنوان نام پارامتر نوع استفاده کنید،
اما ما از T استفاده خواهیم کرد، چون طبق قرارداد، نام پارامترهای نوع در Rust کوتاه هستند—
اغلب تنها یک حرف—و همچنین طبق قرارداد نامگذاری نوعها در Rust بهصورت CamelCase نوشته میشوند.
T که مخفف type است، انتخاب پیشفرض اکثر برنامهنویسان Rust میباشد.
وقتی از یک پارامتر در بدنه تابع استفاده میکنیم، باید نام پارامتر را در امضا اعلام کنیم تا کامپایلر بداند آن نام به چه معناست. به طور مشابه، وقتی از نام پارامتر نوع در امضای تابع استفاده میکنیم، باید نام پارامتر نوع را قبل از استفاده از آن اعلام کنیم. برای تعریف تابع جنریک largest، نام نوعها را داخل پرانتزهای زاویهای، <>، بین نام تابع و لیست پارامتر قرار میدهیم، مانند زیر:
fn largest<T>(list: &[T]) -> &T {این تعریف را به این صورت میخوانیم: تابع largest بر روی یک نوع T جنریک است. این تابع یک پارامتر به نام list دارد، که یک بخش از مقادیر نوع T است. تابع largest یک مرجع به مقداری از همان نوع T بازمیگرداند.
لیستینگ 10-5 تعریف ترکیبی تابع largest را نشان میدهد که از نوع دادهی generic در امضای خود استفاده میکند.
این لیستینگ همچنین نشان میدهد که چگونه میتوان این تابع را با یک slice از مقادیر i32 یا مقادیر char فراخوانی کرد.
توجه داشته باشید که این کد هنوز قابل کامپایل نیست.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}largest با استفاده از پارامترهای نوع جنریک؛ این کد هنوز کامپایل نمیشوداگر همین حالا این کد را کامپایل کنیم، این خطا را دریافت میکنیم:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
متن راهنمای خطا به std::cmp::PartialOrd اشاره میکند که یک trait است،
و ما در بخش بعدی دربارهی traitها صحبت خواهیم کرد.
فعلاً بدانید که این خطا بیان میکند بدنهی تابع largest برای همهی نوعهایی که T میتواند باشد،
کار نخواهد کرد.
چون میخواهیم در بدنهی تابع مقادیری از نوع T را با هم مقایسه کنیم،
تنها میتوانیم از نوعهایی استفاده کنیم که مقادیر آنها قابل مقایسه (ترتیبپذیر) باشند.
برای فعال کردن امکان مقایسه، کتابخانهی استاندارد traitای به نام std::cmp::PartialOrd دارد
که میتوان آن را روی نوعها پیادهسازی کرد
(برای اطلاعات بیشتر دربارهی این trait، به ضمیمهی C مراجعه کنید).
برای اصلاح لیستینگ 10-5، میتوانیم پیشنهاد متن خطا را دنبال کنیم
و نوعهای معتبر برای T را تنها به آنهایی محدود کنیم که PartialOrd را پیادهسازی کردهاند.
در این صورت لیستینگ کامپایل خواهد شد، چون کتابخانهی استاندارد PartialOrd را روی هر دو نوع i32 و char پیادهسازی کرده است.
در تعریف ساختارها (Struct)
ما میتوانیم ساختارها را نیز به گونهای تعریف کنیم که از یک پارامتر نوع جنریک در یک یا چند فیلد استفاده کنند، با استفاده از نحو <>. لیست ۱۰-۶ ساختار Point<T> را تعریف میکند که مقادیر مختصات x و y از هر نوعی را نگه میدارد.
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
Point<T> که مقادیر x و y از نوع T را نگه میداردنحو استفاده از جنریکها در تعریف ساختارها مشابه استفاده آنها در تعریف توابع است. ابتدا نام پارامتر نوع را در داخل پرانتزهای زاویهای بلافاصله پس از نام ساختار اعلام میکنیم. سپس نوع جنریک را در تعریف ساختار استفاده میکنیم، جایی که در غیر این صورت نوع داده مشخص را مشخص میکردیم.
توجه داشته باشید که از آنجا که فقط یک نوع جنریک برای تعریف Point<T> استفاده کردهایم، این تعریف بیان میکند که ساختار Point<T> برای یک نوع T جنریک است و فیلدهای x و y هر دو از همان نوع هستند، هرچه که آن نوع باشد. اگر نمونهای از Point<T> ایجاد کنیم که مقادیر آن انواع مختلف داشته باشند، همانطور که در لیست ۱۰-۷ آمده است، کد ما کامپایل نخواهد شد.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}x و y باید از همان نوع باشند زیرا هر دو دارای نوع داده جنریک T هستند.در این مثال، وقتی مقدار عدد صحیح 5 را به x اختصاص میدهیم، به کامپایلر اطلاع میدهیم که نوع جنریک T برای این نمونه از Point<T> یک عدد صحیح خواهد بود. سپس وقتی 4.0 را برای y مشخص میکنیم، که تعریف کردهایم همان نوع x را داشته باشد، یک خطای عدم تطابق نوع دریافت میکنیم، مانند این:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
برای تعریف یک ساختار Point که در آن x و y هر دو جنریک هستند اما میتوانند انواع مختلفی داشته باشند، میتوانیم از پارامترهای نوع جنریک چندگانه استفاده کنیم. برای مثال، در لیست ۱۰-۸، تعریف Point را تغییر میدهیم تا برای نوعهای T و U جنریک باشد، جایی که x از نوع T و y از نوع U است.
struct Point<T, U> { x: T, y: U, } fn main() { let both_integer = Point { x: 5, y: 10 }; let both_float = Point { x: 1.0, y: 4.0 }; let integer_and_float = Point { x: 5, y: 4.0 }; }
Point<T, U> جنریک بر روی دو نوع، به طوری که x و y میتوانند مقادیری از انواع مختلف باشندحالا تمام نمونههای Point نشان داده شده معتبر هستند! شما میتوانید به تعداد دلخواه پارامترهای نوع جنریک در یک تعریف استفاده کنید، اما استفاده از تعداد زیاد خوانایی کد شما را دشوار میکند. اگر میبینید که نیاز به انواع جنریک زیادی در کد خود دارید، ممکن است نشاندهنده این باشد که کد شما نیاز به ساختاربندی مجدد به بخشهای کوچکتر دارد.
در تعریف شمارشها (Enum)
همانطور که با ساختارها انجام دادیم، میتوانیم شمارشها را به گونهای تعریف کنیم که نوع دادههای جنریک را در حالتهای خود نگه دارند. بیایید دوباره به شمارش Option<T> که کتابخانه استاندارد ارائه میدهد و در فصل ۶ از آن استفاده کردیم نگاه کنیم:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
این تعریف اکنون باید برای شما بیشتر معنا پیدا کند. همانطور که میبینید، شمارش Option<T> بر روی نوع T جنریک است و دو حالت دارد: Some که یک مقدار از نوع T را نگه میدارد و حالت None که هیچ مقداری را نگه نمیدارد. با استفاده از شمارش Option<T>، میتوانیم مفهوم انتزاعی یک مقدار اختیاری را بیان کنیم، و از آنجا که Option<T> جنریک است، میتوانیم از این انتزاع بدون توجه به نوع مقدار اختیاری استفاده کنیم.
شمارشها نیز میتوانند از انواع جنریک چندگانه استفاده کنند. تعریف شمارش Result که در فصل ۹ استفاده کردیم یک مثال است:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
شمارش Result بر روی دو نوع جنریک T و E است و دو حالت دارد: Ok که یک مقدار از نوع T نگه میدارد و Err که یک مقدار از نوع E نگه میدارد. این تعریف استفاده از شمارش Result را در هر جایی که یک عملیات ممکن است موفق شود (یک مقدار از نوع T بازگرداند) یا شکست بخورد (یک خطا از نوع E بازگرداند) آسان میکند. در واقع، این همان چیزی است که برای باز کردن یک فایل در لیست ۹-۳ استفاده کردیم، جایی که T با نوع std::fs::File پر شده بود وقتی فایل با موفقیت باز شد و E با نوع std::io::Error پر شده بود وقتی مشکلاتی در باز کردن فایل وجود داشت.
وقتی وضعیتهایی در کد خود را شناسایی کردید که چندین تعریف ساختار یا شمارش وجود دارد که فقط در نوع مقادیر نگهداری شده متفاوت هستند، میتوانید با استفاده از نوعهای جنریک از تکرار جلوگیری کنید.
در تعریف متدها
ما میتوانیم متدهایی را روی ساختارها و شمارشها پیادهسازی کنیم (همانطور که در فصل ۵ انجام دادیم) و از انواع جنریک در تعریف آنها نیز استفاده کنیم. لیست ۱۰-۹ ساختار Point<T> که در لیست ۱۰-۶ تعریف کردیم را نشان میدهد، با متدی به نام x که روی آن پیادهسازی شده است.
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
x روی ساختار Point<T> که یک مرجع به فیلد x از نوع T بازمیگردانددر اینجا، یک متد به نام x روی Point<T> تعریف کردهایم که یک مرجع به داده موجود در فیلد x بازمیگرداند.
توجه داشته باشید که باید T را بلافاصله بعد از impl اعلام کنیم تا بتوانیم از T برای مشخص کردن اینکه داریم متدها را روی نوع Point<T> پیادهسازی میکنیم، استفاده کنیم. با اعلام T به عنوان یک نوع جنریک بعد از impl، Rust میتواند تشخیص دهد که نوع موجود در پرانتزهای زاویهای در Point یک نوع جنریک است، نه یک نوع مشخص. میتوانستیم نامی متفاوت از پارامتر جنریک اعلامشده در تعریف ساختار برای این پارامتر جنریک انتخاب کنیم، اما استفاده از همان نام یک عرف است. اگر یک متد را درون یک impl که یک نوع جنریک اعلام میکند بنویسید، آن متد روی هر نمونهای از آن نوع تعریف میشود، بدون توجه به اینکه چه نوع مشخصی جایگزین نوع جنریک میشود.
همچنین میتوانیم محدودیتهایی بر روی نوعهای جنریک هنگام تعریف متدها روی یک نوع مشخص کنیم. میتوانیم، برای مثال، متدهایی را فقط روی نمونههای Point<f32> پیادهسازی کنیم، نه روی نمونههای Point<T> با هر نوع جنریک. در لیست ۱۰-۱۰ از نوع مشخص f32 استفاده کردهایم، به این معنی که هیچ نوعی را بعد از impl اعلام نمیکنیم.
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } impl Point<f32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
impl که فقط برای یک ساختار با یک نوع مشخص برای پارامتر نوع جنریک T اعمال میشوداین کد به این معنی است که نوع Point<f32> دارای یک متد distance_from_origin خواهد بود؛ سایر نمونههای Point<T> که T از نوع f32 نیستند، این متد را تعریف نخواهند کرد. این متد فاصله نقطه ما از نقطهای با مختصات (0.0, 0.0) را اندازهگیری میکند و از عملیات ریاضی استفاده میکند که فقط برای نوعهای اعداد اعشاری در دسترس هستند.
پارامترهای نوع جنریک در تعریف یک ساختار همیشه با آنهایی که در امضاهای متد همان ساختار استفاده میشوند یکسان نیستند. لیست ۱۰-۱۱ از نوعهای جنریک X1 و Y1 برای ساختار Point و X2 و Y2 برای امضای متد mixup استفاده میکند تا مثال را واضحتر کند. این متد یک نمونه جدید از Point ایجاد میکند با مقدار x از Point self (از نوع X1) و مقدار y از Point پاسدادهشده (از نوع Y2).
struct Point<X1, Y1> { x: X1, y: Y1, } impl<X1, Y1> Point<X1, Y1> { fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c' }; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
در تابع main، یک Point تعریف کردهایم که x آن یک i32 (با مقدار 5) و y آن یک f64 (با مقدار 10.4) است. متغیر p2 یک ساختار Point است که x آن یک قطعه رشته (با مقدار "Hello") و y آن یک char (با مقدار c) است. فراخوانی mixup روی p1 با آرگومان p2 به ما p3 را میدهد، که x آن یک i32 خواهد بود زیرا x از p1 آمده است. متغیر p3 یک char برای y خواهد داشت زیرا y از p2 آمده است. فراخوانی ماکرو println! مقدار p3.x = 5, p3.y = c را چاپ میکند.
هدف این مثال این است که وضعیتی را نشان دهد که در آن برخی پارامترهای جنریک با impl اعلام میشوند و برخی دیگر با تعریف متد اعلام میشوند. در اینجا، پارامترهای جنریک X1 و Y1 بعد از impl اعلام شدهاند زیرا با تعریف ساختار همراه هستند. پارامترهای جنریک X2 و Y2 بعد از fn mixup اعلام شدهاند زیرا فقط به متد مربوط هستند.
عملکرد کدی که از جنریکها استفاده میکند
ممکن است این سوال برای شما پیش بیاید که آیا هنگام استفاده از پارامترهای نوع جنریک، هزینهای در زمان اجرا وجود دارد یا خیر. خبر خوب این است که استفاده از انواع جنریک برنامه شما را کندتر از حالتی که از انواع مشخص استفاده میکردید، نمیکند.
Rust این کار را با انجام فرآیندی به نام تکریختسازی (monomorphization) روی کدی که از جنریکها استفاده میکند در زمان کامپایل انجام میدهد. تکریختسازی فرآیند تبدیل کد جنریک به کد مشخص است با پر کردن انواع مشخصی که هنگام کامپایل استفاده میشوند. در این فرآیند، کامپایلر برعکس مراحلی که برای ایجاد تابع جنریک در لیست ۱۰-۵ استفاده کردیم را انجام میدهد: کامپایلر به تمام جاهایی که کد جنریک فراخوانی شده نگاه میکند و کدی را برای انواع مشخصی که کد جنریک با آنها فراخوانی شده ایجاد میکند.
بیایید ببینیم این کار چگونه انجام میشود با استفاده از شمارش جنریک Option<T> در کتابخانه استاندارد:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
وقتی Rust این کد را کامپایل میکند، فرآیند تکریختسازی را انجام میدهد. در طول این فرآیند، کامپایلر مقادیر استفاده شده در نمونههای Option<T> را میخواند و دو نوع Option<T> را شناسایی میکند: یکی i32 و دیگری f64. به این ترتیب، تعریف جنریک Option<T> را به دو تعریف ویژه برای i32 و f64 گسترش میدهد و بنابراین تعریف جنریک را با تعریفهای مشخص جایگزین میکند.
نسخه تکریختسازی شده کد شبیه به چیزی به نظر میرسد (کامپایلر از نامهای متفاوتی استفاده میکند، اما برای توضیح از این نامها استفاده کردهایم):
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
شمارش جنریک Option<T> با تعریفهای مشخص ایجاد شده توسط کامپایلر جایگزین شده است. از آنجا که Rust کد جنریک را به کدی که نوع را در هر نمونه مشخص میکند کامپایل میکند، هیچ هزینهای در زمان اجرا برای استفاده از جنریکها پرداخت نمیکنیم. وقتی کد اجرا میشود، دقیقاً همانطور عمل میکند که اگر هر تعریف را به صورت دستی تکرار کرده بودیم. فرآیند تکریختسازی جنریکهای Rust را در زمان اجرا بسیار کارآمد میکند.
ویژگیها (Traits): تعریف رفتار مشترک
یک ویژگی (trait) عملکردی را که یک نوع خاص دارد تعریف میکند و میتواند با انواع دیگر به اشتراک بگذارد. ما میتوانیم از traitها برای تعریف رفتار مشترک به صورت انتزاعی استفاده کنیم. همچنین میتوانیم از محدودیتهای ویژگی (trait bounds) برای مشخص کردن اینکه یک نوع جنریک میتواند هر نوعی باشد که رفتار خاصی دارد، استفاده کنیم.
توجه: ویژگیها شبیه به مفهومی هستند که اغلب در زبانهای دیگر به نام interfaces شناخته میشود، البته با برخی تفاوتها.
تعریف یک trait
رفتار یک نوع شامل متدهایی است که میتوانیم روی آن نوع فراخوانی کنیم. انواع مختلف یک رفتار مشترک دارند اگر بتوانیم همان متدها را روی تمام آن انواع فراخوانی کنیم. تعریف ویژگیها راهی برای گروهبندی امضاهای متدها با هم است تا مجموعهای از رفتارها را که برای دستیابی به یک هدف خاص ضروری است، تعریف کنیم.
برای مثال، فرض کنید چندین struct داریم که انواع مختلفی از متن با اندازههای متفاوت را نگهداری میکنند:
یک ساختار NewsArticle که یک خبر را در مکان خاصی نگهداری میکند،
و یک SocialPost که حداکثر میتواند ۲۸۰ کاراکتر داشته باشد
بههمراه متادادهای که مشخص میکند آیا پست جدید، بازنشر (repost)، یا پاسخ به پست دیگری بوده است.
ما میخواهیم یک crate کتابخانهای برای جمعآوری رسانهها به نام aggregator بسازیم
که بتواند خلاصههایی از دادههایی که ممکن است در نمونههایی از NewsArticle یا SocialPost ذخیره شده باشند را نمایش دهد.
برای انجام این کار، به یک خلاصه از هر نوع نیاز داریم،
و این خلاصه را با فراخوانی متد summarize روی یک نمونه درخواست خواهیم کرد.
لیستینگ 10-12 تعریف یک trait عمومی به نام Summary را نشان میدهد که این رفتار را بیان میکند.
pub trait Summary {
fn summarize(&self) -> String;
}Summary که شامل رفتار ارائهشده توسط یک متد summarize استدر اینجا، یک ویژگی با استفاده از کلیدواژه trait و سپس نام ویژگی، که در اینجا Summary است، اعلام میکنیم. همچنین ویژگی را به عنوان pub اعلام میکنیم تا کرایتهایی که به این کرایت وابسته هستند نیز بتوانند از این ویژگی استفاده کنند، همانطور که در چند مثال خواهیم دید. در داخل آکولادها، امضاهای متدی را اعلام میکنیم که رفتارهای نوعهایی که این ویژگی را پیادهسازی میکنند توصیف میکنند، که در این مورد fn summarize(&self) -> String است.
بعد از امضای متد، به جای ارائه یک پیادهسازی در داخل آکولادها، از یک نقطهویرگول استفاده میکنیم. هر نوعی که این ویژگی را پیادهسازی میکند باید رفتار سفارشی خود را برای بدنه متد ارائه دهد. کامپایلر اطمینان خواهد داد که هر نوعی که ویژگی Summary را دارد، متد summarize را دقیقاً با این امضا تعریف خواهد کرد.
یک ویژگی میتواند چندین متد در بدنه خود داشته باشد: امضاهای متدها به صورت یک خط در هر خط فهرست میشوند و هر خط با یک نقطهویرگول پایان مییابد.
پیادهسازی یک ویژگی (trait) روی یک نوع
حالا که امضاهای مورد نظر برای متدهای trait به نام Summary را تعریف کردهایم،
میتوانیم آن را روی نوعهای موجود در گردآورندهی رسانهایمان پیادهسازی کنیم.
لیستینگ 10-13 پیادهسازی trait Summary را روی structای به نام NewsArticle نشان میدهد،
که از عنوان (headline)، نویسنده (author)، و مکان (location) برای ایجاد مقدار بازگشتی متد summarize استفاده میکند.
برای ساختار SocialPost، متد summarize را بهگونهای تعریف میکنیم که ابتدا نام کاربری بیاید
و سپس تمام متن پست نمایش داده شود، با این فرض که محتوای پست از پیش به ۲۸۰ کاراکتر محدود شده است.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Summary روی نوعهای NewsArticle و SocialPostپیادهسازی یک ویژگی روی یک نوع مشابه پیادهسازی متدهای معمولی است. تفاوت این است که بعد از impl، نام ویژگیای که میخواهیم پیادهسازی کنیم را قرار میدهیم، سپس از کلمه کلیدی for استفاده میکنیم و سپس نام نوعی که میخواهیم ویژگی را برای آن پیادهسازی کنیم مشخص میکنیم. درون بلوک impl، امضاهای متدی که تعریف ویژگی مشخص کردهاند را قرار میدهیم. به جای اضافه کردن یک نقطهویرگول بعد از هر امضا، از آکولادها استفاده میکنیم و بدنه متد را با رفتار خاصی که میخواهیم متدهای ویژگی برای نوع خاص داشته باشند پر میکنیم.
حالا که کتابخانه ویژگی Summary را روی NewsArticle و Tweet پیادهسازی کرده است، کاربران این کرایت میتوانند متدهای ویژگی را روی نمونههای NewsArticle و Tweet فراخوانی کنند، به همان روشی که متدهای معمولی را فراخوانی میکنیم. تنها تفاوت این است که کاربر باید ویژگی را به همراه نوعها به محدوده وارد کند. در اینجا مثالی از اینکه چگونه یک کرایت باینری میتواند از کرایت کتابخانه aggregator ما استفاده کند آورده شده است:
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}این کد مقدار زیر را چاپ میکند:
1 new post: horse_ebooks: of course, as you probably already know, people
سایر crateهایی که به crate aggregator وابسته هستند نیز میتوانند trait به نام Summary را وارد حوزه کنند
و آن را روی نوعهای خودشان پیادهسازی نمایند.
یک محدودیت مهم این است که تنها زمانی میتوانیم یک trait را روی یک نوع پیادهسازی کنیم
که یا trait یا نوع، یا هر دو، در crate ما محلی (local) باشند.
برای مثال، میتوانیم traitهای کتابخانهی استاندارد مانند Display را روی یک نوع سفارشی مانند SocialPost پیادهسازی کنیم
زیرا نوع SocialPost در crate aggregator محلی است.
همچنین میتوانیم trait Summary را روی Vec<T> در crate aggregator پیادهسازی کنیم
چون trait Summary در crate ما محلی است.
اما نمیتوانیم ویژگیهای خارجی را روی نوعهای خارجی پیادهسازی کنیم. برای مثال، نمیتوانیم ویژگی Display را روی Vec<T> در کرایت aggregator پیادهسازی کنیم زیرا Display و Vec<T> هر دو در کتابخانه استاندارد تعریف شدهاند و به کرایت aggregator محلی نیستند. این محدودیت بخشی از خاصیتی به نام انسجام (coherence) و به طور خاصتر قانون یتیم (orphan rule) است، که به این دلیل نامگذاری شده است که نوع والد وجود ندارد. این قانون اطمینان میدهد که کد دیگران نمیتواند کد شما را خراب کند و برعکس. بدون این قانون، دو کرایت میتوانستند همان ویژگی را برای همان نوع پیادهسازی کنند و Rust نمیدانست کدام پیادهسازی را استفاده کند.
پیادهسازیهای پیشفرض
گاهی اوقات مفید است که رفتار پیشفرضی برای برخی یا همه متدهای یک ویژگی داشته باشید به جای اینکه پیادهسازیها برای تمام متدها در هر نوع اجباری باشند. سپس، وقتی ویژگی را روی یک نوع خاص پیادهسازی میکنیم، میتوانیم رفتار پیشفرض هر متد را نگه داریم یا جایگزین کنیم.
در لیست ۱۰-۱۴، یک رشته پیشفرض برای متد summarize ویژگی Summary مشخص میکنیم به جای اینکه فقط امضای متد را تعریف کنیم، همانطور که در لیست ۱۰-۱۲ انجام دادیم.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Summary با یک پیادهسازی پیشفرض برای متد summarizeبرای استفاده از یک پیادهسازی پیشفرض برای خلاصه کردن نمونههای NewsArticle، یک بلوک impl خالی با impl Summary for NewsArticle {} مشخص میکنیم.
اگرچه دیگر متد summarize را مستقیماً روی NewsArticle تعریف نمیکنیم، یک پیادهسازی پیشفرض ارائه دادهایم و مشخص کردهایم که NewsArticle ویژگی Summary را پیادهسازی میکند. در نتیجه، همچنان میتوانیم متد summarize را روی یک نمونه از NewsArticle فراخوانی کنیم، مانند این:
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}این کد New article available! (Read more...) را چاپ میکند.
ایجاد یک پیادهسازی پیشفرض (default) نیازی به تغییر در پیادهسازی trait Summary برای SocialPost در لیستینگ 10-13 ندارد.
دلیل آن این است که سینتکس بازنویسی (override) یک پیادهسازی پیشفرض،
دقیقاً همان سینتکسی است که برای پیادهسازی یک متد از trait که پیادهسازی پیشفرض ندارد استفاده میشود.
پیادهسازیهای پیشفرض میتوانند متدهای دیگر را در همان ویژگی فراخوانی کنند، حتی اگر آن متدهای دیگر پیادهسازی پیشفرض نداشته باشند. به این روش، یک ویژگی میتواند مقدار زیادی عملکرد مفید ارائه دهد و فقط از پیادهسازان بخواهد که بخشی از آن را مشخص کنند. برای مثال، میتوانیم ویژگی Summary را به گونهای تعریف کنیم که یک متد summarize_author داشته باشد که پیادهسازی آن الزامی است و سپس یک متد summarize تعریف کنیم که یک پیادهسازی پیشفرض دارد و متد summarize_author را فراخوانی میکند:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}برای استفاده از این نسخه از Summary، فقط باید summarize_author را هنگامی که ویژگی را روی یک نوع پیادهسازی میکنیم، تعریف کنیم:
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}پس از اینکه summarize_author را تعریف کردیم، میتوانیم متد summarize را روی نمونههایی از struct به نام SocialPost فراخوانی کنیم،
و پیادهسازی پیشفرض متد summarize، از پیادهسازیای که برای summarize_author ارائه دادهایم استفاده خواهد کرد.
از آنجا که ما summarize_author را پیادهسازی کردهایم، trait به نام Summary
رفتار متد summarize را بدون نیاز به نوشتن کد اضافی در اختیار ما قرار داده است.
در اینجا نمونهای از این وضعیت آمده است:
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}این کد مقدار زیر را چاپ میکند:
1 new post: (Read more from @horse_ebooks...)
توجه داشته باشید که امکان فراخوانی پیادهسازی پیشفرض از یک پیادهسازی بازنویسی شده از همان متد وجود ندارد.
ویژگیها (traits) به عنوان پارامترها
حالا که میدانید چگونه یک trait را تعریف و پیادهسازی کنید،
میتوانیم بررسی کنیم که چگونه از traitها برای تعریف توابعی استفاده کنیم
که انواع مختلفی را بهعنوان پارامتر بپذیرند.
ما از trait Summary که روی نوعهای NewsArticle و SocialPost در لیستینگ 10-13 پیادهسازی کردیم،
استفاده خواهیم کرد تا تابعی به نام notify تعریف کنیم
که متد summarize را روی پارامتر item خود فراخوانی میکند—
پارامتری که از نوعی است که trait Summary را پیادهسازی کرده باشد.
برای این کار، از سینتکس impl Trait استفاده میکنیم، به این صورت:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}به جای استفاده از یک نوع مشخص برای پارامتر item،
از کلیدواژهی impl و نام trait استفاده میکنیم.
این پارامتر هر نوعی را میپذیرد که trait مشخصشده را پیادهسازی کرده باشد.
در بدنهی تابع notify، میتوانیم هر متدی از trait Summary را روی item فراخوانی کنیم،
مانند متد summarize.
میتوانیم notify را فراخوانی کرده و هر نمونهای از NewsArticle یا SocialPost را به آن پاس دهیم.
کدی که تابع را با نوعی دیگر، مانند String یا i32، فراخوانی کند کامپایل نخواهد شد،
زیرا این نوعها trait Summary را پیادهسازی نکردهاند.
نحو محدودیت ویژگی (Trait Bound Syntax)
نحو impl Trait برای موارد ساده مناسب است اما در واقع یک شکل کوتاهشده از یک فرم طولانیتر به نام محدودیت ویژگی (trait bound) است؛ به این صورت:
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}این فرم طولانی معادل مثال بخش قبلی است اما مفصلتر است. ما محدودیتهای ویژگی را با اعلام پارامتر نوع جنریک بعد از یک دونقطه و داخل پرانتزهای زاویهای قرار میدهیم.
نحو impl Trait در موارد ساده مناسب است و کد را مختصرتر میکند، در حالی که نحو کاملتر محدودیت ویژگی میتواند پیچیدگی بیشتری را در موارد دیگر بیان کند. برای مثال، میتوانیم دو پارامتر داشته باشیم که ویژگی Summary را پیادهسازی میکنند. انجام این کار با نحو impl Trait به این صورت است:
pub fn notify(item1: &impl Summary, item2: &impl Summary) {استفاده از impl Trait مناسب است اگر بخواهیم این تابع اجازه دهد item1 و item2 انواع مختلفی داشته باشند (به شرطی که هر دو نوع ویژگی Summary را پیادهسازی کنند). اما اگر بخواهیم هر دو پارامتر یک نوع یکسان داشته باشند، باید از محدودیت ویژگی استفاده کنیم، مانند این:
pub fn notify<T: Summary>(item1: &T, item2: &T) {نوع جنریک T که به عنوان نوع پارامترهای item1 و item2 مشخص شده است، تابع را محدود میکند به این صورت که نوع مشخص مقدار پاسدادهشده به عنوان آرگومان برای item1 و item2 باید یکسان باشد.
مشخص کردن محدودیتهای ویژگی چندگانه با نحو +
ما همچنین میتوانیم بیش از یک محدودیت ویژگی مشخص کنیم. فرض کنید میخواهیم notify از فرمتبندی نمایش (display formatting) و همچنین summarize روی item استفاده کند: در تعریف notify مشخص میکنیم که item باید هر دو ویژگی Display و Summary را پیادهسازی کند. این کار را میتوانیم با نحو + انجام دهیم:
pub fn notify(item: &(impl Summary + Display)) {نحو + همچنین با محدودیت ویژگی روی انواع جنریک معتبر است:
pub fn notify<T: Summary + Display>(item: &T) {با مشخص کردن این دو محدودیت ویژگی، بدنه notify میتواند متد summarize را فراخوانی کند و از {} برای فرمتبندی item استفاده کند.
محدودیتهای ویژگی واضحتر با بندهای where
استفاده از تعداد زیادی محدودیت ویژگی معایب خود را دارد. هر جنریک محدودیتهای ویژگی مخصوص به خود را دارد، بنابراین توابعی با چندین پارامتر نوع جنریک میتوانند شامل اطلاعات زیادی درباره محدودیتهای ویژگی بین نام تابع و لیست پارامترهای آن باشند، که باعث سخت شدن خواندن امضای تابع میشود. به همین دلیل، Rust نحو جایگزینی برای مشخص کردن محدودیتهای ویژگی در داخل یک بند where پس از امضای تابع ارائه میدهد. بنابراین، به جای نوشتن این:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {میتوانیم از یک بند where به این صورت استفاده کنیم:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}امضای این تابع کمتر شلوغ است: نام تابع، لیست پارامترها، و نوع بازگشتی به هم نزدیکتر هستند، مشابه یک تابع بدون محدودیتهای ویژگی زیاد.
بازگرداندن نوعهایی که ویژگیها را پیادهسازی میکنند
ما همچنین میتوانیم از نحو impl Trait در موقعیت بازگشتی استفاده کنیم تا مقداری از نوعی که یک ویژگی را پیادهسازی میکند بازگردانیم، همانطور که در اینجا نشان داده شده است:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}با استفاده از impl Summary برای نوع بازگشتی، مشخص میکنیم که تابع returns_summarizable
مقداری را بازمیگرداند که trait Summary را پیادهسازی میکند، بدون اینکه نوع مشخص آن را نام ببریم.
در این حالت، returns_summarizable یک SocialPost را بازمیگرداند،
اما کدی که این تابع را فراخوانی میکند نیازی به دانستن این موضوع ندارد.
توانایی مشخص کردن یک نوع بازگشتی تنها بر اساس ویژگیای که پیادهسازی میکند، به ویژه در زمینه closures و iterators مفید است، که در فصل ۱۳ به آنها میپردازیم. closures و iterators نوعهایی ایجاد میکنند که تنها کامپایلر آنها را میشناسد یا نوعهایی که بسیار طولانی هستند تا مشخص شوند. نحو impl Trait به شما اجازه میدهد که به طور مختصر مشخص کنید یک تابع نوعی که ویژگی Iterator را پیادهسازی میکند بازمیگرداند، بدون نیاز به نوشتن یک نوع بسیار طولانی.
با این حال، تنها زمانی میتوانید از impl Trait استفاده کنید که قرار است فقط یک نوع خاص را بازگردانید.
برای مثال، کدی که بسته به شرایط، یا یک NewsArticle یا یک SocialPost بازمیگرداند و
نوع بازگشتی آن به صورت impl Summary مشخص شده، کار نخواهد کرد:
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \
hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}بازگرداندن یکی از نوعهای NewsArticle یا SocialPost مجاز نیست، به دلیل محدودیتهایی که در پیادهسازی نحوه عملکرد نحوی impl Trait در کامپایلر وجود دارد.
نحوه نوشتن تابعی با چنین رفتاری را در بخش «استفاده از trait objectهایی که امکان داشتن مقادیر با نوعهای مختلف را میدهند» از فصل ۱۸ بررسی خواهیم کرد.
استفاده از محدودیتهای ویژگی برای پیادهسازی شرطی متدها
با استفاده از یک محدودیت ویژگی در یک بلوک impl که از پارامترهای نوع جنریک استفاده میکند، میتوانیم متدها را به طور شرطی برای نوعهایی که ویژگیهای مشخصشده را پیادهسازی میکنند پیادهسازی کنیم. برای مثال، نوع Pair<T> در لیست ۱۰-۱۵ همیشه تابع new را پیادهسازی میکند تا یک نمونه جدید از Pair<T> بازگرداند (به یاد داشته باشید از بخش “تعریف متدها” در فصل ۵ که Self یک نام مستعار برای نوع بلوک impl است که در اینجا Pair<T> است). اما در بلوک impl بعدی، Pair<T> فقط متد cmp_display را پیادهسازی میکند اگر نوع داخلی T ویژگی PartialOrd که مقایسه را ممکن میکند و ویژگی Display که چاپ را ممکن میکند، پیادهسازی کند.
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}ما همچنین میتوانیم یک ویژگی را به طور شرطی برای هر نوعی که ویژگی دیگری را پیادهسازی میکند، پیادهسازی کنیم. پیادهسازیهای یک ویژگی روی هر نوعی که محدودیتهای ویژگی را برآورده میکند پیادهسازیهای کلی (blanket implementations) نامیده میشوند و به طور گسترده در کتابخانه استاندارد Rust استفاده میشوند. برای مثال، کتابخانه استاندارد ویژگی ToString را روی هر نوعی که ویژگی Display را پیادهسازی میکند، پیادهسازی میکند. بلوک impl در کتابخانه استاندارد شبیه به این کد است:
impl<T: Display> ToString for T {
// --snip--
}از آنجا که کتابخانه استاندارد این پیادهسازی کلی را دارد، میتوانیم متد to_string تعریفشده توسط ویژگی ToString را روی هر نوعی که ویژگی Display را پیادهسازی میکند، فراخوانی کنیم. برای مثال، میتوانیم اعداد صحیح را به مقادیر String متناظرشان تبدیل کنیم مانند این:
#![allow(unused)] fn main() { let s = 3.to_string(); }
پیادهسازیهای کلی در مستندات ویژگی در بخش “Implementors” ظاهر میشوند.
ویژگیها و محدودیتهای ویژگی به ما امکان میدهند که کدی بنویسیم که از پارامترهای نوع جنریک برای کاهش تکرار استفاده کند اما همچنین به کامپایلر مشخص کند که میخواهیم نوع جنریک رفتار خاصی داشته باشد. سپس کامپایلر میتواند از اطلاعات محدودیت ویژگی استفاده کند تا بررسی کند که تمام نوعهای مشخص استفادهشده با کد ما رفتار صحیح را ارائه میدهند. در زبانهای تایپگذاری پویا، ما هنگام اجرا خطا دریافت میکنیم اگر یک متد روی یک نوع که آن متد را تعریف نکرده فراخوانی کنیم. اما Rust این خطاها را به زمان کامپایل منتقل میکند تا ما مجبور شویم مشکلات را قبل از اینکه کد ما اجرا شود برطرف کنیم. علاوه بر این، نیازی به نوشتن کدی نداریم که رفتار را در زمان اجرا بررسی کند زیرا قبلاً آن را در زمان کامپایل بررسی کردهایم. این کار عملکرد را بهبود میبخشد بدون اینکه انعطافپذیری جنریکها را قربانی کند.
اعتبارسنجی مراجع با طول عمرها
طول عمرها نوع دیگری از جنریکها هستند که ما قبلاً از آنها استفاده کردهایم. به جای اطمینان از اینکه یک نوع رفتار مورد نظر ما را دارد، طول عمرها تضمین میکنند که مراجع به اندازهای که نیاز داریم معتبر باقی میمانند.
جزئیاتی که در بخش “رفرنسها و قرضگیری” در فصل ۴ مطرح نکردیم، این است که هر رفرنس در Rust دارای یک lifetime است، یعنی حوزهای که آن رفرنس در آن معتبر است. بیشتر مواقع، lifetimeها بهصورت ضمنی و استنتاجشده هستند، درست مانند بیشتر مواقعی که نوعها بهصورت استنتاجشده هستند. ما تنها زمانی ملزم به افزودن annotation برای نوعها هستیم که چند نوع ممکن وجود داشته باشد. بهطور مشابه، زمانی که lifetimeهای رفرنسها ممکن است به چند شکل مختلف به هم مرتبط باشند، باید رابطهی آنها را با پارامترهای lifetime generic مشخص کنیم. Rust این الزام را دارد تا اطمینان حاصل شود که رفرنسهای واقعی که در زمان اجرا استفاده میشوند، قطعاً معتبر خواهند بود.
افزودن annotation برای lifetimeها حتی مفهومی نیست که اکثر زبانهای برنامهنویسی دیگر داشته باشند، بنابراین این موضوع برای شما غریب به نظر خواهد رسید. اگرچه در این فصل بهصورت کامل به lifetimeها نمیپردازیم، اما روشهای رایجی که ممکن است با سینتکس lifetime مواجه شوید را بررسی خواهیم کرد تا با این مفهوم آشنا شوید.
جلوگیری از مراجع آویزان (Dangling References) با طول عمرها
هدف اصلی طول عمرها جلوگیری از مراجع آویزان است، که باعث میشوند یک برنامه به دادههایی غیر از دادههایی که قرار بوده مراجعه کند اشاره کند. برنامهای را در نظر بگیرید که در لیست ۱۰-۱۶ نشان داده شده است و دارای یک محدوده خارجی و یک محدوده داخلی است.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}توجه: مثالهای لیستینگهای 10-16، 10-17، و 10-23 متغیرهایی را بدون مقداردهی اولیه اعلام میکنند، بنابراین نام متغیر در حوزهی بیرونی وجود دارد. در نگاه اول، این ممکن است بهنظر برسد که با عدم وجود مقدار null در Rust مغایرت دارد. اما اگر سعی کنیم متغیری را قبل از مقداردهی استفاده کنیم، خطای زمان کامپایل دریافت خواهیم کرد که نشان میدهد Rust واقعاً اجازهی وجود مقدار null را نمیدهد.
محدوده خارجی یک متغیر به نام r را بدون مقدار اولیه اعلام میکند، و محدوده داخلی یک متغیر به نام x را با مقدار اولیه 5 اعلام میکند. در داخل محدوده داخلی، تلاش میکنیم مقدار r را به عنوان یک مرجع به x تنظیم کنیم. سپس محدوده داخلی به پایان میرسد و سعی میکنیم مقدار موجود در r را چاپ کنیم. این کد کامپایل نخواهد شد زیرا مقداری که r به آن اشاره میکند قبل از اینکه سعی کنیم از آن استفاده کنیم از محدوده خارج شده است. پیام خطای زیر را دریافت میکنیم:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| --- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
پیام خطا میگوید که متغیر x “به اندازه کافی طول عمر ندارد.” دلیل این است که x وقتی محدوده داخلی در خط ۷ پایان مییابد، از محدوده خارج میشود. اما r همچنان برای محدوده خارجی معتبر است؛ زیرا محدوده آن بزرگتر است، میگوییم که “طول عمر بیشتری دارد.” اگر Rust به این کد اجازه کار کردن میداد، r به حافظهای اشاره میکرد که وقتی x از محدوده خارج شد آزاد شده است، و هر کاری که سعی میکردیم با r انجام دهیم به درستی کار نمیکرد. پس چگونه Rust تشخیص میدهد که این کد نامعتبر است؟ از یک بررسیکننده قرض (borrow checker) استفاده میکند.
بررسیکننده قرض (Borrow Checker)
کامپایلر Rust دارای یک بررسیکننده قرض است که محدودهها را مقایسه میکند تا تعیین کند که آیا تمام قرضها معتبر هستند یا خیر. لیست ۱۰-۱۷ همان کد لیست ۱۰-۱۶ را نشان میدهد اما با حاشیهنویسیهایی که طول عمر متغیرها را نشان میدهد.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+r و x که به ترتیب به نامهای 'a و 'b نامگذاری شدهانددر اینجا، طول عمر r را با 'a و طول عمر x را با 'b حاشیهنویسی کردهایم. همانطور که میبینید، بلوک داخلی 'b بسیار کوچکتر از بلوک طول عمر خارجی 'a است. در زمان کامپایل، Rust اندازه دو طول عمر را مقایسه میکند و میبیند که r دارای طول عمر 'a است اما به حافظهای اشاره میکند که طول عمر آن 'b است. برنامه رد میشود زیرا 'b کوتاهتر از 'a است: موضوع مرجع به اندازه مرجع زنده نیست.
لیست ۱۰-۱۸ کد را اصلاح میکند تا یک مرجع آویزان نداشته باشد و بدون هیچ خطایی کامپایل شود.
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {r}"); // | | // --+ | } // ----------+
در اینجا، x دارای طول عمر 'b است که در این مورد بزرگتر از 'a است. این بدان معناست که r میتواند به x اشاره کند زیرا Rust میداند که مرجع در r همیشه در حالی که x معتبر است، معتبر خواهد بود.
حال که میدانید lifetime رفرنسها کجا هستند و Rust چگونه lifetimeها را تحلیل میکند تا اطمینان یابد رفرنسها همیشه معتبر خواهند بود، بیایید lifetimeهای generic پارامترها و مقادیر بازگشتی را در زمینهی توابع بررسی کنیم.
طول عمرهای جنریک در توابع
ما تابعی خواهیم نوشت که طولانیترین قطعه رشته (string slice) را بازمیگرداند. این تابع دو قطعه رشته میگیرد و یک قطعه رشته بازمیگرداند. پس از پیادهسازی تابع longest، کد در لیست ۱۰-۱۹ باید The longest string is abcd را چاپ کند.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}main که تابع longest را فراخوانی میکند تا طولانیترین قطعه رشته را پیدا کندتوجه کنید که ما میخواهیم تابع پارامترهایی از نوع string slice دریافت کند،
که رفرنس هستند، نه رشتههای کامل، زیرا نمیخواهیم تابع longest مالک پارامترهایش باشد.
برای بحث بیشتر دربارهی دلیل انتخاب چنین پارامترهایی در لیستینگ 10-19،
به بخش “String Slices به عنوان پارامتر” در فصل ۴ مراجعه کنید.
اگر سعی کنیم تابع longest را همانطور که در لیست ۱۰-۲۰ نشان داده شده است پیادهسازی کنیم، کامپایل نمیشود.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}longest که طولانیترین قطعه رشته را بازمیگرداند اما هنوز کامپایل نمیشودبه جای آن، خطای زیر را دریافت میکنیم که درباره طول عمرها صحبت میکند:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
متن کمکی نشان میدهد که نوع بازگشتی نیاز به یک پارامتر طول عمر جنریک دارد زیرا Rust نمیتواند تشخیص دهد که مرجع بازگرداندهشده به x اشاره میکند یا به y. در واقع، ما هم نمیدانیم، زیرا بلوک if در بدنه این تابع یک مرجع به x بازمیگرداند و بلوک else یک مرجع به y بازمیگرداند!
وقتی این تابع را تعریف میکنیم، مقادیر مشخصی که به این تابع پاس داده میشوند را نمیدانیم، بنابراین نمیدانیم که آیا حالت if یا حالت else اجرا خواهد شد. همچنین طول عمرهای مشخص مراجع پاسدادهشده را نمیدانیم، بنابراین نمیتوانیم به محدودهها مانند لیستهای ۱۰-۱۷ و ۱۰-۱۸ نگاه کنیم تا تعیین کنیم که مرجعی که بازمیگردانیم همیشه معتبر خواهد بود. بررسیکننده قرض هم نمیتواند این موضوع را تعیین کند زیرا نمیداند چگونه طول عمرهای x و y به طول عمر مقدار بازگشتی مرتبط هستند. برای رفع این خطا، پارامترهای طول عمر جنریک اضافه میکنیم که رابطه بین مراجع را تعریف میکنند تا بررسیکننده قرض بتواند تحلیل خود را انجام دهد.
نحو حاشیهنویسی طول عمر
حاشیهنویسی طول عمر طول عمر هیچیک از مراجع را تغییر نمیدهد. بلکه، آنها روابط طول عمرهای چندین مرجع را بدون تأثیر بر طول عمرها توصیف میکنند. همانطور که توابع میتوانند هر نوعی را بپذیرند وقتی امضا یک پارامتر نوع جنریک را مشخص میکند، توابع میتوانند مراجع با هر طول عمری را بپذیرند با مشخص کردن یک پارامتر طول عمر جنریک.
حاشیهنویسی طول عمر دارای نحو کمی غیرمعمول است: نامهای پارامتر طول عمر باید با یک آپاستروف (') شروع شوند و معمولاً همه حروف کوچک و بسیار کوتاه هستند، مانند نوعهای جنریک. بیشتر افراد از نام 'a برای اولین حاشیهنویسی طول عمر استفاده میکنند. ما حاشیهنویسیهای پارامتر طول عمر را بعد از & یک مرجع قرار میدهیم و از یک فاصله برای جدا کردن حاشیهنویسی از نوع مرجع استفاده میکنیم.
در اینجا چند مثال آورده شده است: یک مرجع به یک i32 بدون پارامتر طول عمر، یک مرجع به یک i32 که یک پارامتر طول عمر به نام 'a دارد، و یک مرجع قابل تغییر به یک i32 که همچنین طول عمر 'a دارد:
&i32 // یک مرجع
&'a i32 // یک مرجع با طول عمر صریح
&'a mut i32 // یک مرجع قابل تغییر با طول عمر صریحیک حاشیهنویسی طول عمر به تنهایی معنای زیادی ندارد زیرا حاشیهنویسیها برای توضیح دادن به Rust هستند که پارامترهای طول عمر جنریک چندین مرجع چگونه به یکدیگر مرتبط هستند. بیایید بررسی کنیم که حاشیهنویسیهای طول عمر چگونه در زمینه تابع longest به یکدیگر مرتبط هستند.
حاشیهنویسی طول عمر در امضاهای توابع
برای استفاده از حاشیهنویسیهای طول عمر در امضاهای توابع، باید پارامترهای طول عمر جنریک را در داخل پرانتزهای زاویهای بین نام تابع و لیست پارامتر اعلام کنیم، همانطور که با پارامترهای نوع جنریک انجام دادیم.
ما میخواهیم امضا محدودیت زیر را بیان کند: مرجع بازگرداندهشده تا زمانی که هر دو پارامتر معتبر هستند معتبر خواهد بود. این رابطه بین طول عمرهای پارامترها و مقدار بازگشتی است. طول عمر را به نام 'a مینامیم و سپس آن را به هر مرجع اضافه میکنیم، همانطور که در لیست ۱۰-۲۱ نشان داده شده است.
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
longest که مشخص میکند تمام مراجع در امضا باید طول عمر یکسانی به نام 'a داشته باشنداین کد باید کامپایل شود و نتیجه مورد نظر ما را زمانی که با تابع main در لیست ۱۰-۱۹ استفاده میکنیم تولید کند.
امضای تابع اکنون به Rust میگوید که برای برخی طول عمر 'a، تابع دو پارامتر میگیرد که هر دو قطعه رشتههایی هستند که حداقل به مدت طول عمر 'a زندگی میکنند. امضای تابع همچنین به Rust میگوید که قطعه رشتهای که از تابع بازگردانده میشود حداقل به مدت طول عمر 'a زندگی میکند. در عمل، این بدان معناست که طول عمر مرجعی که توسط تابع longest بازگردانده میشود همان طول عمر کوچکتر مقادیر اشارهشده توسط آرگومانهای تابع است. این روابط چیزی است که ما میخواهیم Rust هنگام تحلیل این کد از آنها استفاده کند.
به یاد داشته باشید، وقتی پارامترهای طول عمر را در این امضای تابع مشخص میکنیم، طول عمر هیچیک از مقادیر پاسدادهشده یا بازگرداندهشده را تغییر نمیدهیم. بلکه، مشخص میکنیم که بررسیکننده قرض باید هر مقداری را که به این محدودیتها پایبند نیست رد کند. توجه داشته باشید که تابع longest نیازی به دانستن دقیق اینکه x و y چقدر زنده خواهند ماند ندارد، تنها اینکه برخی محدودهها میتوانند جایگزین 'a شوند که این امضا را برآورده کنند.
هنگام حاشیهنویسی طول عمرها در توابع، حاشیهنویسیها در امضای تابع قرار میگیرند، نه در بدنه تابع. حاشیهنویسیهای طول عمر بخشی از قرارداد تابع میشوند، مشابه انواع موجود در امضا. داشتن امضای تابع که شامل قرارداد طول عمر است به این معنی است که تحلیلی که کامپایلر Rust انجام میدهد میتواند سادهتر باشد. اگر مشکلی در نحوه حاشیهنویسی یک تابع یا نحوه فراخوانی آن وجود داشته باشد، خطاهای کامپایلر میتوانند به بخش مشخصی از کد ما و محدودیتها اشاره کنند. اگر، به جای آن، کامپایلر Rust استنتاج بیشتری درباره آنچه که قصد داریم روابط طول عمرها باشند انجام دهد، کامپایلر ممکن است فقط بتواند به استفادهای از کد ما اشاره کند که چندین مرحله دور از علت مشکل باشد.
وقتی مراجع مشخصی را به longest پاس میدهیم، طول عمر مشخصی که برای 'a جایگزین میشود بخشی از محدوده x است که با محدوده y همپوشانی دارد. به عبارت دیگر، طول عمر جنریک 'a طول عمر مشخصی را میگیرد که برابر با کوچکترین طول عمرهای x و y است. از آنجا که مرجع بازگرداندهشده را با همان پارامتر طول عمر 'a حاشیهنویسی کردهایم، مرجع بازگرداندهشده نیز برای مدت کوچکترین طول عمرهای x و y معتبر خواهد بود.
بیایید ببینیم حاشیهنویسی طول عمرها چگونه تابع longest را محدود میکند با پاس دادن مراجع که طول عمرهای مشخص مختلفی دارند. لیست ۱۰-۲۲ یک مثال ساده است.
fn main() { let string1 = String::from("long string is long"); { let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {result}"); } } fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } }
longest با مراجع به مقادیر String که طول عمرهای مشخص مختلفی دارنددر این مثال، string1 تا پایان محدوده خارجی معتبر است، string2 تا پایان محدوده داخلی معتبر است، و result به چیزی اشاره میکند که تا پایان محدوده داخلی معتبر است. این کد را اجرا کنید و خواهید دید که بررسیکننده قرض آن را تأیید میکند؛ کد کامپایل میشود و The longest string is long string is long را چاپ میکند.
حال، بیایید مثالی را امتحان کنیم که نشان دهد طول عمر مرجع در result باید کوچکترین طول عمر دو آرگومان باشد. اعلام متغیر result را به بیرون از محدوده داخلی منتقل میکنیم، اما مقداردهی به متغیر result را درون محدوده با string2 نگه میداریم. سپس println! که از result استفاده میکند را به بیرون از محدوده داخلی، پس از پایان محدوده داخلی منتقل میکنیم. کد در لیست ۱۰-۲۳ کامپایل نمیشود.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}result پس از اینکه string2 از محدوده خارج شده استوقتی تلاش میکنیم این کد را کامپایل کنیم، خطای زیر را دریافت میکنیم:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| -------- borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
این خطا نشان میدهد که برای اینکه result برای دستور println! معتبر باشد، string2 باید تا پایان محدوده خارجی معتبر باشد. Rust این را میداند زیرا طول عمرهای پارامترهای تابع و مقادیر بازگشتی را با استفاده از همان پارامتر طول عمر 'a حاشیهنویسی کردهایم.
به عنوان انسان، میتوانیم به این کد نگاه کنیم و ببینیم که string1 طولانیتر از string2 است، و بنابراین، result یک مرجع به string1 خواهد داشت. زیرا string1 هنوز از محدوده خارج نشده است، یک مرجع به string1 برای دستور println! همچنان معتبر خواهد بود. با این حال، کامپایلر نمیتواند ببیند که این مرجع در این مورد معتبر است. ما به Rust گفتهایم که طول عمر مرجع بازگرداندهشده توسط تابع longest همان طول عمر کوچکترین مرجعهای پاسدادهشده است. بنابراین، بررسیکننده قرض کد در لیست ۱۰-۲۳ را به عنوان داشتن یک مرجع نامعتبر احتمالی رد میکند.
سعی کنید آزمایشهای بیشتری طراحی کنید که مقادیر و طول عمر مراجع پاسدادهشده به تابع longest و نحوه استفاده از مرجع بازگرداندهشده را تغییر دهند. فرضیاتی درباره اینکه آیا آزمایشهای شما بررسیکننده قرض را پاس میکنند یا نه ایجاد کنید؛ سپس بررسی کنید که آیا درست میگویید!
تفکر بر اساس طول عمرها
نحوه نیاز شما به مشخص کردن پارامترهای طول عمر به آنچه که تابع شما انجام میدهد بستگی دارد. برای مثال، اگر پیادهسازی تابع longest را تغییر دهیم تا همیشه اولین پارامتر را به جای طولانیترین قطعه رشته بازگرداند، نیازی به مشخص کردن طول عمر برای پارامتر y نخواهیم داشت. کد زیر کامپایل میشود:
fn main() { let string1 = String::from("abcd"); let string2 = "efghijklmnopqrstuvwxyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {result}"); } fn longest<'a>(x: &'a str, y: &str) -> &'a str { x }
ما یک پارامتر طول عمر 'a برای پارامتر x و نوع بازگشتی مشخص کردهایم، اما برای پارامتر y نه، زیرا طول عمر y هیچ رابطهای با طول عمر x یا مقدار بازگشتی ندارد.
هنگام بازگرداندن یک مرجع از یک تابع، پارامتر طول عمر برای نوع بازگشتی باید با پارامتر طول عمر یکی از پارامترها مطابقت داشته باشد. اگر مرجع بازگرداندهشده به یکی از پارامترها اشاره نکند، باید به مقداری که در این تابع ایجاد شده است اشاره کند. با این حال، این یک مرجع آویزان خواهد بود زیرا مقدار در پایان تابع از محدوده خارج میشود. به این پیادهسازی ناموفق تابع longest که کامپایل نمیشود توجه کنید:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}در اینجا، حتی اگر یک پارامتر طول عمر 'a برای نوع بازگشتی مشخص کرده باشیم، این پیادهسازی کامپایل نمیشود زیرا طول عمر مقدار بازگشتی به هیچ وجه به طول عمر پارامترها مرتبط نیست. پیام خطایی که دریافت میکنیم به این شکل است:
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
مشکل این است که result از محدوده خارج میشود و در پایان تابع longest پاک میشود. همچنین سعی میکنیم یک مرجع به result را از تابع بازگردانیم. هیچ راهی وجود ندارد که بتوانیم پارامترهای طول عمری مشخص کنیم که مرجع آویزان را تغییر دهد، و Rust به ما اجازه نمیدهد یک مرجع آویزان ایجاد کنیم. در این مورد، بهترین راه حل این است که یک نوع داده مالک (owned) به جای یک مرجع بازگردانیم تا تابع فراخوانیکننده مسئول پاکسازی مقدار باشد.
در نهایت، نحو طول عمرها درباره ارتباط دادن طول عمرهای پارامترها و مقادیر بازگشتی توابع است. وقتی این ارتباط برقرار شد، Rust اطلاعات کافی برای اجازه دادن به عملیاتهای ایمن از نظر حافظه و منع عملیاتهایی که باعث ایجاد اشارهگر (Pointer)های آویزان یا نقض ایمنی حافظه میشوند، دارد.
حاشیهنویسی طول عمر در تعریف ساختارها
تا کنون، ساختارهایی که تعریف کردهایم همه دارای نوعهای مالک بودهاند. میتوانیم ساختارهایی را تعریف کنیم که مراجع نگه میدارند، اما در این صورت باید برای هر مرجعی در تعریف ساختار یک حاشیهنویسی طول عمر اضافه کنیم. لیست ۱۰-۲۴ یک ساختار به نام ImportantExcerpt دارد که یک قطعه رشته نگه میدارد.
struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
این ساختار دارای یک فیلد به نام part است که یک قطعه رشته نگه میدارد، که یک مرجع است. همانند نوعهای داده جنریک، ما نام پارامتر طول عمر جنریک را در داخل پرانتزهای زاویهای بعد از نام ساختار اعلام میکنیم تا بتوانیم پارامتر طول عمر را در بدنه تعریف ساختار استفاده کنیم. این حاشیهنویسی به این معنی است که یک نمونه از ImportantExcerpt نمیتواند بیشتر از مرجعی که در فیلد part خود نگه میدارد زنده بماند.
تابع main در اینجا یک نمونه از ساختار ImportantExcerpt ایجاد میکند که یک مرجع به اولین جمله از String که توسط متغیر novel نگه داشته میشود، نگه میدارد. دادههای novel قبل از ایجاد نمونه ImportantExcerpt وجود دارند. علاوه بر این، novel تا بعد از خروج ImportantExcerpt از محدوده از محدوده خارج نمیشود، بنابراین مرجع در نمونه ImportantExcerpt معتبر است.
حذف طول عمر (Lifetime Elision)
آموختید که هر مرجع دارای یک طول عمر است و شما باید برای توابع یا ساختارهایی که از مراجع استفاده میکنند پارامترهای طول عمر مشخص کنید. با این حال، ما تابعی در لیست ۴-۹ داشتیم که دوباره در لیست ۱۰-۲۵ نشان داده شده است، که بدون حاشیهنویسی طول عمر کامپایل شد.
fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } fn main() { let my_string = String::from("hello world"); // first_word works on slices of `String`s let word = first_word(&my_string[..]); let my_string_literal = "hello world"; // first_word works on slices of string literals let word = first_word(&my_string_literal[..]); // Because string literals *are* string slices already, // this works too, without the slice syntax! let word = first_word(my_string_literal); }
دلیل اینکه این تابع بدون حاشیهنویسی طول عمر کامپایل میشود تاریخی است: در نسخههای اولیه (قبل از 1.0) از Rust، این کد کامپایل نمیشد زیرا هر مرجع نیاز به یک طول عمر صریح داشت. در آن زمان، امضای تابع به این صورت نوشته میشد:
fn first_word<'a>(s: &'a str) -> &'a str {پس از نوشتن مقدار زیادی کد Rust، تیم Rust متوجه شد که برنامهنویسان Rust در موقعیتهای خاصی حاشیهنویسیهای طول عمر یکسانی را بارها و بارها وارد میکردند. این موقعیتها قابل پیشبینی بودند و از چند الگوی تعیینکننده پیروی میکردند. توسعهدهندگان این الگوها را در کد کامپایلر برنامهریزی کردند تا بررسیکننده قرض بتواند طول عمرها را در این موقعیتها استنتاج کند و نیازی به حاشیهنویسی صریح نباشد.
این بخش از تاریخ Rust مرتبط است زیرا ممکن است الگوهای تعیینکننده بیشتری ظاهر شوند و به کامپایلر اضافه شوند. در آینده، حتی حاشیهنویسیهای طول عمر کمتری ممکن است لازم باشد.
الگوهایی که در تحلیل مراجع Rust برنامهریزی شدهاند قوانین حذف طول عمر (lifetime elision rules) نامیده میشوند. اینها قوانینی نیستند که برنامهنویسان باید رعایت کنند؛ بلکه مجموعهای از موارد خاص هستند که کامپایلر آنها را در نظر میگیرد و اگر کد شما با این موارد مطابقت داشته باشد، نیازی به نوشتن طول عمرها به صورت صریح نخواهید داشت.
قواعد elision نمیتوانند inference کامل انجام دهند. اگر پس از اعمال این قواعد همچنان ابهامی دربارهی lifetime رفرنسها وجود داشته باشد، کامپایلر حدس نمیزند که lifetime باقیماندهها باید چه باشد. به جای حدس زدن، کامپایلر خطایی نمایش میدهد که میتوانید با اضافه کردن annotationهای lifetime آن را رفع کنید.
طول عمرهای روی پارامترهای تابع یا متد طول عمر ورودی (input lifetimes) نامیده میشوند، و طول عمرهای روی مقادیر بازگشتی طول عمر خروجی (output lifetimes) نامیده میشوند.
کامپایلر از سه قانون برای تشخیص طول عمر مراجع استفاده میکند وقتی که حاشیهنویسیهای صریح وجود ندارند. قانون اول برای طول عمرهای ورودی اعمال میشود، و قانون دوم و سوم برای طول عمرهای خروجی. اگر کامپایلر به انتهای این سه قانون برسد و هنوز مراجع وجود داشته باشند که نتواند طول عمرهای آنها را تشخیص دهد، کامپایلر با یک خطا متوقف میشود. این قوانین به تعاریف fn و همچنین بلوکهای impl اعمال میشوند.
- قانون اول: کامپایلر یک پارامتر طول عمر به هر پارامتر که یک مرجع است اختصاص میدهد. به عبارت دیگر، یک تابع با یک پارامتر یک پارامتر طول عمر میگیرد:
fn foo<'a>(x: &'a i32)؛ یک تابع با دو پارامتر دو پارامتر طول عمر جداگانه میگیرد:fn foo<'a, 'b>(x: &'a i32, y: &'b i32)؛ و به همین ترتیب. - قانون دوم: اگر دقیقاً یک پارامتر طول عمر ورودی وجود داشته باشد، آن طول عمر به تمام پارامترهای طول عمر خروجی اختصاص داده میشود:
fn foo<'a>(x: &'a i32) -> &'a i32. - قانون سوم: اگر چندین پارامتر طول عمر ورودی وجود داشته باشد، اما یکی از آنها
&selfیا&mut selfباشد زیرا این یک متد است، طول عمرselfبه تمام پارامترهای طول عمر خروجی اختصاص داده میشود. این قانون سوم خواندن و نوشتن متدها را بسیار آسانتر میکند زیرا نمادهای کمتری لازم است.
بیایید وانمود کنیم که ما کامپایلر هستیم. این قوانین را برای تشخیص طول عمر مراجع در امضای تابع first_word در لیست ۱۰-۲۵ اعمال میکنیم. امضا بدون هیچ طول عمری که با مراجع مرتبط باشد شروع میشود:
fn first_word(s: &str) -> &str {سپس کامپایلر قانون اول را اعمال میکند که مشخص میکند هر پارامتر طول عمر خاص خود را دریافت میکند. ما آن را طبق معمول 'a مینامیم، بنابراین امضا اکنون به این صورت است:
fn first_word<'a>(s: &'a str) -> &str {قانون دوم اعمال میشود زیرا دقیقاً یک طول عمر ورودی وجود دارد. قانون دوم مشخص میکند که طول عمر یک پارامتر ورودی به طول عمر خروجی اختصاص داده میشود، بنابراین امضا اکنون به این صورت است:
fn first_word<'a>(s: &'a str) -> &'a str {حالا تمام مراجع در این امضای تابع طول عمر دارند و کامپایلر میتواند تحلیل خود را بدون نیاز به برنامهنویس برای حاشیهنویسی طول عمرها در این امضای تابع ادامه دهد.
بیایید به یک مثال دیگر نگاه کنیم، این بار با استفاده از تابع longest که در ابتدا هیچ پارامتر طول عمری نداشت، همانطور که در لیست ۱۰-۲۰ کار خود را با آن شروع کردیم:
fn longest(x: &str, y: &str) -> &str {بیایید قانون اول را اعمال کنیم: هر پارامتر طول عمر خاص خود را دریافت میکند. این بار دو پارامتر داریم، بنابراین دو طول عمر داریم:
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {میبینید که قانون دوم اعمال نمیشود زیرا بیش از یک طول عمر ورودی وجود دارد. قانون سوم نیز اعمال نمیشود زیرا longest یک تابع است و نه یک متد، بنابراین هیچ یک از پارامترها self نیستند. پس از عبور از تمام سه قانون، هنوز طول عمر نوع بازگشتی را تعیین نکردهایم. به همین دلیل است که هنگام تلاش برای کامپایل کد در لیست ۱۰-۲۰ خطا گرفتیم: کامپایلر قوانین حذف طول عمر را مرور کرد اما همچنان نتوانست تمام طول عمرهای مراجع در امضا را تعیین کند.
از آنجا که قانون سوم واقعاً فقط در امضاهای متد اعمال میشود، به بررسی طول عمرها در آن زمینه میپردازیم تا ببینیم چرا قانون سوم باعث میشود که اغلب نیازی به حاشیهنویسی طول عمر در امضاهای متد نداشته باشیم.
حاشیهنویسی طول عمر در تعریف متدها
وقتی متدهایی را روی یک struct دارای lifetime پیادهسازی میکنیم،
از همان سینتکسی استفاده میکنیم که برای پارامترهای نوع generic به کار میرود،
همانطور که در لیستینگ 10-11 نشان داده شده است.
مکان اعلام و استفاده از پارامترهای lifetime بستگی به این دارد که آیا این lifetimeها
مرتبط با فیلدهای struct هستند یا پارامترها و مقادیر بازگشتی متد.
نامهای طول عمر برای فیلدهای ساختار همیشه باید بعد از کلمه کلیدی impl اعلام شوند و سپس بعد از نام ساختار استفاده شوند، زیرا این طول عمرها بخشی از نوع ساختار هستند.
در امضاهای متد در داخل بلوک impl، مراجع ممکن است به طول عمر مراجع در فیلدهای ساختار مرتبط باشند، یا ممکن است مستقل باشند. علاوه بر این، قوانین حذف طول عمر اغلب باعث میشوند که حاشیهنویسی طول عمر در امضاهای متد ضروری نباشد. بیایید به چند مثال با استفاده از ساختار ImportantExcerpt که در لیست ۱۰-۲۴ تعریف کردیم، نگاه کنیم.
ابتدا از متدی به نام level استفاده میکنیم که تنها پارامتر آن مرجعی به self است و مقدار بازگشتی آن یک i32 است که به چیزی اشاره نمیکند:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
اعلام پارامتر طول عمر بعد از impl و استفاده از آن بعد از نام نوع الزامی است، اما ما نیازی به حاشیهنویسی طول عمر مرجع به self نداریم زیرا قانون اول حذف اعمال میشود.
در اینجا مثالی است که قانون سوم حذف طول عمر اعمال میشود:
struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {announcement}"); self.part } } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().unwrap(); let i = ImportantExcerpt { part: first_sentence, }; }
دو طول عمر ورودی وجود دارد، بنابراین Rust قانون اول حذف طول عمر را اعمال میکند و طول عمرهای جداگانهای به &self و announcement میدهد. سپس، چون یکی از پارامترها &self است، نوع بازگشتی طول عمر &self را دریافت میکند، و تمام طول عمرها در نظر گرفته شدهاند.
طول عمر استاتیک
یک طول عمر خاص که باید درباره آن صحبت کنیم 'static است، که نشان میدهد مرجع مورد نظر میتواند برای کل مدت اجرای برنامه زنده بماند. تمام رشتههای لیتری دارای طول عمر 'static هستند، که میتوانیم آن را به این صورت حاشیهنویسی کنیم:
#![allow(unused)] fn main() { let s: &'static str = "I have a static lifetime."; }
متن این رشته مستقیماً در باینری برنامه ذخیره میشود، که همیشه در دسترس است. بنابراین، طول عمر تمام رشتههای لیتری 'static است.
ممکن است در پیامهای خطا پیشنهادهایی برای استفاده از طول عمر 'static ببینید. اما قبل از مشخص کردن طول عمر 'static برای یک مرجع، فکر کنید که آیا مرجعی که دارید واقعاً برای کل مدت اجرای برنامه زنده است یا خیر، و آیا میخواهید چنین باشد. بیشتر اوقات، یک پیام خطا که طول عمر 'static را پیشنهاد میدهد نتیجه تلاش برای ایجاد یک مرجع آویزان یا ناسازگاری طول عمرهای موجود است. در چنین مواردی، راه حل این است که این مشکلات را برطرف کنید، نه اینکه طول عمر 'static را مشخص کنید.
پارامترهای نوع جنریک، محدودیت ویژگی، و طول عمرها با هم
بیایید به طور مختصر به نحو مشخص کردن پارامترهای نوع جنریک، محدودیت ویژگی، و طول عمرها در یک تابع نگاه کنیم!
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest_with_an_announcement( string1.as_str(), string2, "Today is someone's birthday!", ); println!("The longest string is {result}"); } use std::fmt::Display; fn longest_with_an_announcement<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Announcement! {ann}"); if x.len() > y.len() { x } else { y } }
این تابع longest از لیست ۱۰-۲۱ است که طولانیترین قطعه رشته را بازمیگرداند. اما اکنون یک پارامتر اضافی به نام ann دارد که از نوع جنریک T است، که میتواند با هر نوعی که ویژگی Display را پیادهسازی میکند، پر شود، همانطور که توسط بند where مشخص شده است. این پارامتر اضافی با استفاده از {} چاپ خواهد شد، به همین دلیل محدودیت ویژگی Display ضروری است. از آنجا که طول عمرها نوعی جنریک هستند، اعلام طول عمر 'a و پارامتر نوع جنریک T در همان لیست داخل پرانتزهای زاویهای بعد از نام تابع قرار میگیرند.
خلاصه
در این فصل مطالب زیادی را پوشش دادیم! حالا که با پارامترهای نوع جنریک، ویژگیها و محدودیتهای ویژگی، و پارامترهای طول عمر جنریک آشنا شدید، آماده هستید تا کدی بدون تکرار بنویسید که در بسیاری از موقعیتهای مختلف کار کند. پارامترهای نوع جنریک به شما اجازه میدهند که کد را روی انواع مختلف اعمال کنید. ویژگیها و محدودیتهای ویژگی اطمینان حاصل میکنند که حتی با اینکه نوعها جنریک هستند، رفتار مورد نیاز کد را خواهند داشت. شما یاد گرفتید چگونه از حاشیهنویسی طول عمر استفاده کنید تا اطمینان حاصل شود که این کد انعطافپذیر هیچ مرجع آویزانی نخواهد داشت. و تمام این تحلیلها در زمان کامپایل انجام میشود، که بر عملکرد زمان اجرا تأثیری ندارد!
باور کنید یا نه، مطالب بیشتری برای یادگیری در مورد موضوعاتی که در این فصل بحث شد وجود دارد: فصل ۱۸ به اشیاء ویژگی (trait objects) میپردازد، که راه دیگری برای استفاده از ویژگیها است. همچنین سناریوهای پیچیدهتری وجود دارد که شامل حاشیهنویسی طول عمر هستند و فقط در سناریوهای بسیار پیشرفته به آنها نیاز خواهید داشت. برای این موارد، باید مرجع Rust را مطالعه کنید. اما بعد از این، یاد خواهید گرفت که چگونه تستهایی در Rust بنویسید تا مطمئن شوید کد شما همانطور که باید کار میکند.
نوشتن تستهای خودکار
در مقالهی خود در سال ۱۹۷۲ با عنوان «برنامهنویس فروتن»، اَدسگر و. دایکسترا بیان کرد که «تست برنامه میتواند راهی بسیار مؤثر برای نشان دادن وجود باگها باشد، اما برای اثبات عدم وجود آنها کاملاً ناکافی است.» این بدان معنا نیست که نباید تا حد امکان تلاش کنیم برنامه را تست کنیم!
درستی در برنامههای ما میزان انطباق کد ما با آنچه که قصد انجامش را داریم، است. Rust با نگرانی بالایی درباره درستی برنامهها طراحی شده است، اما درستی پیچیده و اثبات آن آسان نیست. سیستم نوع Rust بخش عظیمی از این بار را به دوش میکشد، اما سیستم نوع نمیتواند همه چیز را پوشش دهد. به همین دلیل، Rust شامل پشتیبانی برای نوشتن تستهای خودکار نرمافزار است.
فرض کنید یک تابع به نام add_two مینویسیم که ۲ را به هر عددی که به آن پاس داده شود اضافه میکند. امضای این تابع یک عدد صحیح به عنوان پارامتر میپذیرد و یک عدد صحیح به عنوان نتیجه بازمیگرداند. هنگامی که این تابع را پیادهسازی و کامپایل میکنیم، Rust تمام بررسیهای نوع و قرضگیری را که تا کنون آموختهاید انجام میدهد تا اطمینان حاصل شود که، به عنوان مثال، ما یک مقدار String یا یک مرجع نامعتبر را به این تابع پاس نمیدهیم. اما Rust نمیتواند بررسی کند که این تابع دقیقاً همان کاری را که ما قصد داریم انجام دهد، که بازگرداندن پارامتر به علاوه ۲ است نه مثلاً پارامتر به علاوه ۱۰ یا پارامتر منهای ۵۰! اینجا جایی است که تستها وارد میشوند.
ما میتوانیم تستهایی بنویسیم که، به عنوان مثال، تأیید میکنند که وقتی 3 را به تابع add_two پاس میدهیم، مقدار بازگردانده شده 5 است. میتوانیم این تستها را هر زمان که تغییری در کد خود ایجاد میکنیم اجرا کنیم تا مطمئن شویم که هر رفتار درستی که وجود داشته تغییر نکرده است.
تستنویسی یک مهارت پیچیده است: اگرچه نمیتوانیم در یک فصل تمام جزئیات مربوط به نحوه نوشتن تستهای خوب را پوشش دهیم، در این فصل درباره مکانیک تسهیلات تست Rust بحث خواهیم کرد. درباره حاشیهنویسیها و ماکروهایی که هنگام نوشتن تستها در اختیار دارید صحبت خواهیم کرد، رفتار پیشفرض و گزینههای ارائهشده برای اجرای تستها را بررسی خواهیم کرد، و نحوه سازماندهی تستها به تستهای واحد و تستهای یکپارچه را یاد خواهیم گرفت.
چگونه تست بنویسیم
تستها توابعی در Rust هستند که بررسی میکنند کد غیرتستی به شکل مورد انتظار کار میکند. بدنه توابع تست معمولاً این سه عمل را انجام میدهد:
- تنظیم هر داده یا وضعیت مورد نیاز.
- اجرای کدی که میخواهید تست کنید.
- تأیید اینکه نتایج همان چیزی است که انتظار دارید.
بیایید به ویژگیهایی که Rust به طور خاص برای نوشتن تستهایی که این اقدامات را انجام میدهند فراهم کرده است نگاهی بیندازیم. این ویژگیها شامل ویژگی test، چند ماکرو و ویژگی should_panic هستند.
آناتومی یک تابع تست
در سادهترین حالت، یک تست در Rust یک تابع است که با ویژگی test حاشیهنویسی شده است. ویژگیها متادادههایی درباره بخشهای کد Rust هستند؛ یک مثال ویژگی derive است که در فصل ۵ با ساختارها استفاده کردیم. برای تغییر یک تابع به یک تابع تست، #[test] را به خط قبل از fn اضافه کنید. وقتی تستهای خود را با فرمان cargo test اجرا میکنید، Rust یک باینری تست رانر ایجاد میکند که توابع حاشیهنویسیشده را اجرا میکند و گزارش میدهد که آیا هر تابع تست موفق یا ناموفق بوده است.
هر زمان که یک پروژه کتابخانهای جدید با Cargo ایجاد میکنیم، یک ماژول تست با یک تابع تست در آن به صورت خودکار برای ما تولید میشود. این ماژول یک قالب برای نوشتن تستهای شما فراهم میکند تا نیازی به جستجوی ساختار و نحو دقیق هر بار که یک پروژه جدید شروع میکنید نداشته باشید. میتوانید هر تعداد تابع تست اضافی و هر تعداد ماژول تست اضافی که میخواهید اضافه کنید!
ما برخی از جنبههای نحوه عملکرد تستها را با آزمایش قالب تست قبل از اینکه واقعاً کدی را تست کنیم بررسی خواهیم کرد. سپس تستهایی در دنیای واقعی مینویسیم که برخی کدهایی که نوشتهایم را فراخوانی میکنند و تأیید میکنند که رفتار آن صحیح است.
بیایید یک پروژه کتابخانهای جدید به نام adder ایجاد کنیم که دو عدد را با هم جمع کند:
$ cargo new adder --lib
Created library `adder` project
$ cd adder
محتویات فایل src/lib.rs در کتابخانه adder شما باید شبیه به لیست ۱۱-۱ باشد.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}cargo new تولید میشوداین فایل با یک تابع نمونه به نام add شروع میشود تا چیزی برای تست کردن داشته باشیم.
فعلاً روی تابع it_works تمرکز میکنیم. به حاشیهنویسی #[test] توجه کنید: این ویژگی نشان میدهد که این یک تابع تست است، بنابراین تست رانر میداند که این تابع را به عنوان یک تست در نظر بگیرد. ممکن است توابع غیرتستی نیز در ماژول tests داشته باشیم که به تنظیم سناریوهای مشترک یا انجام عملیاتهای مشترک کمک میکنند، بنابراین همیشه باید مشخص کنیم کدام توابع تست هستند.
بدنه تابع نمونه از ماکرو assert_eq! استفاده میکند تا اطمینان حاصل کند که result، که حاوی نتیجه فراخوانی add با مقادیر ۲ و ۲ است، برابر با ۴ باشد. این اطمینان به عنوان یک مثال از فرمت یک تست معمولی عمل میکند. بیایید آن را اجرا کنیم تا ببینیم این تست پاس میشود.
فرمان cargo test تمام تستهای پروژه ما را اجرا میکند، همانطور که در لیست ۱۱-۲ نشان داده شده است.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo تست را کامپایل و اجرا کرد. خط running 1 test را میبینیم. خط بعدی نام تابع تست تولیدشده را نشان میدهد، که tests::it_works نام دارد، و نتیجه اجرای آن تست ok است. خلاصه کلی test result: ok. نشان میدهد که تمام تستها پاس شدهاند، و بخشی که 1 passed; 0 failed را میخواند تعداد تستهایی که پاس شدهاند یا ناموفق بودهاند را نشان میدهد.
امکان علامتگذاری یک تست بهعنوان ignored وجود دارد تا در یک اجرای خاص اجرا نشود؛
ما این موضوع را در بخش “نادیده گرفتن برخی تستها مگر در صورت درخواست خاص”
در ادامهی این فصل بررسی خواهیم کرد.
چون در اینجا این کار را انجام ندادهایم، خلاصه نشاندهندهی 0 ignored است.
همچنین میتوانیم آرگومانی به دستور cargo test بدهیم تا فقط تستهایی اجرا شوند که نامشان با رشتهای مطابقت دارد؛
این کار filtering نامیده میشود و در بخش “اجرای زیرمجموعهای از تستها بر اساس نام” بررسی خواهد شد.
در اینجا تستها فیلتر نشدهاند، بنابراین انتهای خلاصه 0 filtered out را نشان میدهد.
آمار 0 measured برای تستهای بنچمارک است که عملکرد را اندازهگیری میکنند. تستهای بنچمارک، در زمان نوشتن این متن، فقط در نسخه شبانه Rust موجود هستند. برای اطلاعات بیشتر مستندات مربوط به تستهای بنچمارک را ببینید.
قسمت بعدی خروجی تست که از Doc-tests adder شروع میشود، مربوط به نتایج تستهای مستندات است.
فعلاً تست مستنداتی نداریم، اما Rust میتواند هر نمونه کدی که در مستندات API ما آمده است را کامپایل کند.
این ویژگی به هماهنگ نگهداشتن مستندات و کد شما کمک میکند!
در بخش “نظرات مستندات بهعنوان تست” در فصل ۱۴، نحوهی نوشتن تستهای مستندات را بررسی خواهیم کرد.
فعلاً خروجی Doc-tests را نادیده میگیریم.
بیایید تست را مطابق نیازهای خود شخصیسازی کنیم. ابتدا نام تابع it_works را به یک نام دیگر، مانند exploration تغییر دهید، به این صورت:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}سپس دوباره cargo test را اجرا کنید. خروجی اکنون به جای it_works نام exploration را نشان میدهد:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
حالا یک تست دیگر اضافه میکنیم، اما این بار تستی مینویسیم که شکست بخورد! تستها زمانی شکست میخورند که چیزی در تابع تست باعث ایجاد panic شود. هر تست در یک نخ (thread) جدید اجرا میشود، و وقتی نخ اصلی میبیند که یک نخ تست متوقف شده است، تست به عنوان شکستخورده علامتگذاری میشود. در فصل ۹، درباره اینکه سادهترین راه برای panic کردن فراخوانی ماکروی panic! است صحبت کردیم. تابع جدیدی به نام another وارد کنید تا فایل src/lib.rs شما شبیه به لیست ۱۱-۳ شود.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}panic! شکست میخورددوباره تستها را با استفاده از cargo test اجرا کنید. خروجی باید شبیه به لیست ۱۱-۴ باشد، که نشان میدهد تست exploration موفق شده است و another شکست خورده است.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
به جای ok، در خط test tests::another عبارت FAILED نمایش داده میشود.
دو بخش جدید بین نتایج فردی و خلاصه ظاهر میشوند:
اولی دلیل دقیق هر شکست تست را نمایش میدهد.
در این مورد، جزئیات نشان میدهد که tests::another شکست خورده زیرا در خط ۱۷ فایل src/lib.rs
با پیام Make this test fail دچار panic شده است.
بخش بعدی فقط نام تمام تستهای شکستخورده را فهرست میکند،
که وقتی تعداد تستها زیاد و خروجی شکست تستها مفصل است، مفید است.
میتوانیم از نام تست شکستخورده استفاده کنیم تا فقط آن تست را اجرا کنیم و راحتتر آن را اشکالزدایی کنیم؛
در بخش “کنترل نحوهی اجرای تستها” بیشتر دربارهی روشهای اجرای تست صحبت خواهیم کرد.
حالا که دیدید نتایج تست در سناریوهای مختلف چگونه به نظر میرسند، بیایید به برخی از ماکروهای دیگر به جز panic! که در تستها مفید هستند نگاهی بیندازیم.
بررسی نتایج با ماکروی assert!
ماکروی assert! که توسط کتابخانه استاندارد ارائه شده است، زمانی مفید است که بخواهید اطمینان حاصل کنید که یک شرط در یک تست به true ارزیابی میشود. ماکروی assert! یک آرگومان میگیرد که به یک مقدار بولی ارزیابی میشود. اگر مقدار true باشد، هیچ اتفاقی نمیافتد و تست پاس میشود. اگر مقدار false باشد، ماکروی assert! فراخوانی panic! را انجام میدهد تا باعث شکست تست شود. استفاده از ماکروی assert! به ما کمک میکند تا بررسی کنیم که کد ما همانطور که قصد داریم عمل میکند.
در فصل ۵، لیست ۵-۱۵، از یک ساختار Rectangle و یک متد can_hold استفاده کردیم، که در لیست ۱۱-۵ دوباره تکرار شده است. این کد را در فایل src/lib.rs قرار دهید، سپس با استفاده از ماکروی assert! چند تست برای آن بنویسید.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}Rectangle و متد can_hold آن از فصل ۵متد can_hold یک مقدار بولی بازمیگرداند، که به این معنی است که یک مورد استفاده عالی برای ماکروی assert! است. در لیست ۱۱-۶، ما تستی مینویسیم که متد can_hold را با ایجاد یک نمونه از Rectangle که عرض ۸ و ارتفاع ۷ دارد آزمایش میکند و تأیید میکند که میتواند نمونه دیگری از Rectangle که عرض ۵ و ارتفاع ۱ دارد را در خود جای دهد.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}can_hold که بررسی میکند آیا یک مستطیل بزرگتر میتواند واقعاً یک مستطیل کوچکتر را در خود جای دهدبه خط use super::*; در داخل ماژول tests توجه کنید. ماژول tests یک ماژول معمولی است که از قوانین دیدپذیری معمولی که در فصل ۷ در بخش “مسیرها برای اشاره به یک مورد در درخت ماژول” پوشش دادیم پیروی میکند. از آنجا که ماژول tests یک ماژول داخلی است، باید کدی که در ماژول خارجی است را به دامنه ماژول داخلی بیاوریم. در اینجا از یک glob استفاده میکنیم، بنابراین هر چیزی که در ماژول خارجی تعریف کنیم برای این ماژول tests در دسترس است.
تست خود را larger_can_hold_smaller نامگذاری کردهایم، و دو نمونه Rectangle که نیاز داشتیم را ایجاد کردهایم. سپس ماکروی assert! را فراخوانی کردیم و نتیجه فراخوانی larger.can_hold(&smaller) را به آن پاس دادیم. این عبارت قرار است true بازگرداند، بنابراین تست ما باید پاس شود. بیایید ببینیم چه اتفاقی میافتد!
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
پاس شد! حالا یک تست دیگر اضافه کنیم، این بار تأیید میکنیم که یک مستطیل کوچکتر نمیتواند یک مستطیل بزرگتر را در خود جای دهد:
Filename: src/lib.rs
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}از آنجا که نتیجه صحیح تابع can_hold در این مورد false است، باید آن نتیجه را قبل از پاس دادن به ماکروی assert! منفی کنیم. به این ترتیب، تست ما زمانی پاس میشود که can_hold مقدار false را بازگرداند:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
دو تست که پاس میشوند! حالا بیایید ببینیم وقتی باگی به کد خود وارد میکنیم چه اتفاقی برای نتایج تست ما میافتد. پیادهسازی متد can_hold را با جایگزینی علامت بزرگتر (>) با علامت کوچکتر (<) هنگام مقایسه عرضها تغییر میدهیم:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}اجرای تستها اکنون خروجی زیر را تولید میکند:
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:28:9:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
تستهای ما باگ را پیدا کردند! از آنجا که larger.width مقدار 8 و smaller.width مقدار 5 دارد، مقایسه عرضها در can_hold اکنون false بازمیگرداند: ۸ کمتر از ۵ نیست.
تست برابری با ماکروهای assert_eq! و assert_ne!
یک روش معمول برای بررسی عملکرد، تست برابری بین نتیجه کد تحت تست و مقدار مورد انتظار است. میتوانید این کار را با استفاده از ماکروی assert! و پاس دادن یک عبارت با استفاده از عملگر == انجام دهید. با این حال، این یک تست بسیار معمول است که کتابخانه استاندارد یک جفت ماکرو—assert_eq! و assert_ne!—برای انجام این تست به صورت راحتتر فراهم کرده است. این ماکروها به ترتیب دو آرگومان را برای برابری یا نابرابری مقایسه میکنند. اگر ادعا شکست بخورد، این ماکروها دو مقدار را نیز چاپ میکنند، که مشاهده دلیل شکست تست را آسانتر میکند. در مقابل، ماکروی assert! فقط نشان میدهد که یک مقدار false برای عبارت == دریافت کرده است، بدون چاپ مقادیری که منجر به مقدار false شدهاند.
در لیست ۱۱-۷، تابعی به نام add_two مینویسیم که ۲ را به پارامتر خود اضافه میکند، سپس این تابع را با استفاده از ماکروی assert_eq! تست میکنیم.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}add_two با استفاده از ماکروی assert_eq!بیایید بررسی کنیم که آیا پاس میشود!
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
ما متغیری به نام result ایجاد میکنیم که نتیجهی فراخوانی add_two(2) را نگه میدارد.
سپس result و عدد 4 را بهعنوان آرگومان به ماکروی assert_eq! میدهیم.
خط خروجی این تست به شکل test tests::it_adds_two ... ok است،
و متن ok نشان میدهد که تست ما با موفقیت گذشت!
pub fn add_two(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}تستها را دوباره اجرا کنید:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:12:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
تست ما باگ را پیدا کرد! تست tests::it_adds_two شکست خورد،
و پیام نشان میدهد که ادعای ناموفق left == right بوده است و مقدارهای left و right چیستند.
این پیام به ما کمک میکند تا فرآیند اشکالزدایی را شروع کنیم:
آرگومان left که نتیجهی فراخوانی add_two(2) بود، مقدار 5 داشت،
اما آرگومان right مقدار 4 بود.
میتوانید تصور کنید که این موضوع زمانی که تعداد زیادی تست اجرا میشود، چقدر مفید است.
توجه کنید که در برخی زبانها و فریمورکهای تست، پارامترهای تابع ادعای برابری (assertion)
به نامهای expected و actual شناخته میشوند و ترتیب آرگومانها اهمیت دارد.
اما در Rust، این پارامترها left و right نامیده میشوند و ترتیب مقدار مورد انتظار و مقدار تولید شده توسط کد اهمیت ندارد.
میتوانیم ادعای این تست را به صورت assert_eq!(4, result) نیز بنویسیم،
که نتیجهی همان پیام شکست با عنوان assertion `left == right` failed را خواهد داشت.
ماکروی assert_ne! زمانی پاس میشود که دو مقداری که به آن میدهیم برابر نباشند و شکست میخورد اگر برابر باشند. این ماکرو برای مواردی مفید است که مطمئن نیستیم یک مقدار چه خواهد بود، اما میدانیم که مقدار به طور قطع چه نباید باشد. برای مثال، اگر تابعی را تست میکنیم که تضمین شده است ورودی خود را به نوعی تغییر دهد، اما نحوه تغییر ورودی به روز هفتهای که تستهای خود را اجرا میکنیم بستگی دارد، بهترین چیزی که میتوانیم تأیید کنیم این است که خروجی تابع برابر با ورودی نیست.
در پسزمینه، ماکروهای assert_eq! و assert_ne! به ترتیب از عملگرهای == و != استفاده میکنند. وقتی ادعا شکست میخورد، این ماکروها آرگومانهای خود را با استفاده از قالببندی دیباگ چاپ میکنند، که به این معنی است که مقادیر مقایسهشده باید ویژگیهای PartialEq و Debug را پیادهسازی کنند. تمام نوعهای اولیه و بیشتر نوعهای کتابخانه استاندارد این ویژگیها را پیادهسازی میکنند. برای ساختارها و انومهایی که خودتان تعریف میکنید، باید PartialEq را برای تأیید برابری این نوعها پیادهسازی کنید. همچنین باید Debug را برای چاپ مقادیر زمانی که ادعا شکست میخورد پیادهسازی کنید. از آنجا که هر دو ویژگی قابل اشتقاق هستند، همانطور که در لیست ۵-۱۲ فصل ۵ اشاره شد، این معمولاً به سادگی افزودن حاشیهنویسی #[derive(PartialEq, Debug)] به تعریف ساختار یا انوم شما است. برای جزئیات بیشتر در مورد این ویژگیها و سایر ویژگیهای قابل اشتقاق، به ضمیمه ج، “ویژگیهای قابل اشتقاق” مراجعه کنید.
افزودن پیامهای شکست سفارشی
شما همچنین میتوانید یک پیام سفارشی را بهعنوان آرگومانهای اختیاری به ماکروهای assert!، assert_eq! و assert_ne! اضافه کنید تا همراه با پیام شکست چاپ شود.
هر آرگومانی که پس از آرگومانهای ضروری وارد شود، به ماکرو format! (که در بخش “ادغام با عملگر + یا ماکرو format!” در فصل ۸ توضیح داده شده) ارسال میشود،
پس میتوانید یک رشتهی قالب (format string) حاوی جاینگهدارهای {} و مقادیری برای جایگذاری در آنها ارسال کنید.
پیامهای سفارشی برای مستندسازی معنای یک assertion مفید هستند؛
وقتی تست شکست میخورد، درک بهتری از مشکل کد خواهید داشت.
برای مثال، فرض کنید تابعی داریم که افراد را با نامشان خوشامد میگوید و میخواهیم تست کنیم که نامی که به تابع پاس میدهیم در خروجی ظاهر میشود:
Filename: src/lib.rs
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}نیازمندیهای این برنامه هنوز مورد توافق قرار نگرفتهاند، و ما تقریباً مطمئن هستیم که متن Hello در ابتدای پیام خوشامد تغییر خواهد کرد. تصمیم گرفتیم که نمیخواهیم وقتی نیازمندیها تغییر میکنند، تست را بهروزرسانی کنیم، بنابراین به جای بررسی برابری دقیق با مقدار بازگشتی از تابع greeting، فقط تأیید میکنیم که خروجی شامل متن پارامتر ورودی است.
حالا بیایید یک باگ به این کد وارد کنیم با تغییر greeting بهطوری که name را شامل نشود تا ببینیم پیام شکست تست پیشفرض چگونه است:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}اجرای این تست خروجی زیر را تولید میکند:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
assertion failed: result.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
این نتیجه فقط نشان میدهد که ادعا شکست خورده است و خطی که ادعا در آن قرار دارد کدام است. یک پیام شکست مفیدتر مقدار بازگشتی از تابع greeting را چاپ میکرد. بیایید یک پیام شکست سفارشی اضافه کنیم که از یک رشته قالب با یک نگهدارنده که با مقدار واقعی بازگشتی از تابع greeting پر شده است، تشکیل شده باشد:
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}حالا وقتی تست را اجرا میکنیم، یک پیام خطای اطلاعرسانتر دریافت خواهیم کرد:
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
ما میتوانیم مقدار واقعیای که در خروجی تست دریافت کردیم را ببینیم، که به ما کمک میکند تا اشکالزدایی کنیم که چه اتفاقی افتاد به جای آنچه که انتظار داشتیم اتفاق بیفتد.
بررسی پانیک با should_panic
علاوه بر بررسی مقادیر بازگشتی، مهم است که بررسی کنیم کد ما شرایط خطا را همانطور که انتظار داریم مدیریت میکند. برای مثال، نوع Guess را که در فصل ۹، لیست ۹-۱۳ ایجاد کردیم در نظر بگیرید. سایر کدهایی که از Guess استفاده میکنند به این تضمین وابسته هستند که نمونههای Guess فقط مقادیر بین ۱ و ۱۰۰ را شامل میشوند. میتوانیم تستی بنویسیم که اطمینان حاصل کند که تلاش برای ایجاد یک نمونه Guess با مقداری خارج از این بازه منجر به پانیک میشود.
این کار را با افزودن ویژگی should_panic به تابع تست خود انجام میدهیم. اگر کد داخل تابع پانیک کند، تست پاس میشود؛ اگر کد داخل تابع پانیک نکند، تست شکست میخورد.
لیست ۱۱-۸ یک تست را نشان میدهد که بررسی میکند شرایط خطای Guess::new زمانی که انتظار داریم رخ میدهند.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}panic! میشودما ویژگی #[should_panic] را بعد از ویژگی #[test] و قبل از تابع تستی که به آن اعمال میشود قرار میدهیم. بیایید به نتیجهای که وقتی این تست پاس میشود نگاه کنیم:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
به نظر خوب میآید! حالا بیایید یک باگ در کد خود وارد کنیم با حذف شرطی که تابع new را مجبور میکند اگر مقدار بیشتر از ۱۰۰ باشد پانیک کند:
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}وقتی تست در لیست ۱۱-۸ را اجرا میکنیم، شکست میخورد:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
در این مورد پیام خیلی مفیدی دریافت نمیکنیم، اما وقتی به تابع تست نگاه میکنیم، میبینیم که با #[should_panic] حاشیهنویسی شده است. شکست به این معناست که کدی که در تابع تست قرار دارد باعث یک پانیک نشده است.
تستهایی که از should_panic استفاده میکنند میتوانند دقیق نباشند. یک تست should_panic حتی اگر تست برای دلیلی غیر از آنچه انتظار داشتیم پانیک کند، پاس میشود. برای دقیقتر کردن تستهای should_panic، میتوانیم یک پارامتر اختیاری expected به ویژگی should_panic اضافه کنیم. تست رانر اطمینان حاصل میکند که پیام شکست شامل متن ارائهشده است. برای مثال، کد تغییر دادهشده برای Guess در لیست ۱۱-۹ را در نظر بگیرید که تابع new با پیامهای مختلف بسته به اینکه مقدار خیلی کوچک یا خیلی بزرگ باشد پانیک میکند.
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}panic! با یک پیام پانیک که حاوی یک زیررشته مشخص استاین تست پاس میشود زیرا مقداری که در پارامتر expected ویژگی should_panic قرار دادهایم یک زیررشته از پیامی است که تابع Guess::new با آن پانیک میکند. میتوانستیم کل پیام پانیکی که انتظار داریم را مشخص کنیم، که در این مورد میشد Guess value must be less than or equal to 100, got 200. آنچه انتخاب میکنید بستگی به این دارد که چه مقدار از پیام پانیک منحصر به فرد یا پویا است و چقدر میخواهید تست شما دقیق باشد. در این مورد، یک زیررشته از پیام پانیک کافی است تا اطمینان حاصل شود که کد در تابع تست مورد else if value > 100 را اجرا میکند.
برای دیدن اینکه وقتی یک تست should_panic با یک پیام expected شکست میخورد چه اتفاقی میافتد، بیایید دوباره یک باگ به کد خود وارد کنیم با جابهجا کردن بدنههای بلوکهای if value < 1 و else if value > 100:
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}این بار وقتی تست should_panic را اجرا میکنیم، شکست خواهد خورد:
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
Guess value must be greater than or equal to 1, got 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: `"Guess value must be greater than or equal to 1, got 200."`,
expected substring: `"less than or equal to 100"`
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
پیام شکست نشان میدهد که این تست همانطور که انتظار داشتیم پانیک کرد، اما پیام پانیک شامل رشته مورد انتظار less than or equal to 100 نبود. پیام پانیکی که در این مورد دریافت کردیم Guess value must be greater than or equal to 1, got 200. بود. حالا میتوانیم شروع به پیدا کردن محل باگ کنیم!
استفاده از Result<T, E> در تستها
تستهای ما تا اینجا همه زمانی که شکست میخورند پانیک میکنند. همچنین میتوانیم تستهایی بنویسیم که از Result<T, E> استفاده کنند! در اینجا تست لیست ۱۱-۱ را بازنویسی کردهایم تا از Result<T, E> استفاده کند و به جای پانیک کردن، یک Err بازگرداند:
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}تابع it_works اکنون نوع بازگشتی Result<(), String> دارد. در بدنه تابع، به جای فراخوانی ماکروی assert_eq!، وقتی تست پاس میشود Ok(()) و وقتی تست شکست میخورد یک Err با یک String داخل آن بازمیگردانیم.
نوشتن تستهایی که یک Result<T, E> بازمیگردانند به شما اجازه میدهد از عملگر سوالی ? در بدنه تستها استفاده کنید، که میتواند راهی راحت برای نوشتن تستهایی باشد که اگر هر عملیاتی در آنها یک واریانت Err بازگرداند، شکست بخورند.
شما نمیتوانید از حاشیهنویسی #[should_panic] در تستهایی که از Result<T, E> استفاده میکنند استفاده کنید. برای تأیید اینکه یک عملیات یک واریانت Err بازمیگرداند، از عملگر سوالی روی مقدار Result<T, E> استفاده نکنید. در عوض، از assert!(value.is_err()) استفاده کنید.
حالا که چندین روش برای نوشتن تستها را یاد گرفتید، بیایید نگاهی به آنچه هنگام اجرای تستها اتفاق میافتد بیندازیم و گزینههای مختلفی را که میتوانیم با cargo test استفاده کنیم بررسی کنیم.
کنترل نحوه اجرای تستها
دقیقاً همانطور که cargo run کد شما را کامپایل کرده و باینری حاصل را اجرا میکند، cargo test کد شما را در حالت تست کامپایل کرده و باینری تست حاصل را اجرا میکند. رفتار پیشفرض باینری تولیدشده توسط cargo test این است که تمام تستها را به صورت موازی اجرا کرده و خروجی تولید شده در طول اجرای تستها را ضبط کند. این کار از نمایش خروجی جلوگیری کرده و خواندن خروجی مرتبط با نتایج تست را آسانتر میکند. با این حال، میتوانید با مشخص کردن گزینههای خط فرمان این رفتار پیشفرض را تغییر دهید.
برخی گزینههای خط فرمان به cargo test میروند و برخی دیگر به باینری تست حاصل ارسال میشوند. برای جدا کردن این دو نوع آرگومان، آرگومانهایی که به cargo test میروند را ذکر کنید و سپس جداکننده -- و آرگومانهایی که به باینری تست میروند را بیاورید. اجرای cargo test --help گزینههایی را نمایش میدهد که میتوانید با cargo test استفاده کنید، و اجرای cargo test -- --help گزینههایی را که میتوانید پس از جداکننده استفاده کنید نمایش میدهد. این گزینهها همچنین در بخش “تستها” از کتاب rustc مستند شدهاند.
اجرای تستها به صورت موازی یا متوالی
وقتی چندین تست را اجرا میکنید، به طور پیشفرض این تستها به صورت موازی با استفاده از نخها (threads) اجرا میشوند، به این معنی که سریعتر به پایان میرسند و بازخورد سریعتری دریافت میکنید. از آنجا که تستها به صورت همزمان اجرا میشوند، باید اطمینان حاصل کنید که تستهای شما به یکدیگر یا به هیچ حالت مشترکی، از جمله یک محیط مشترک مانند دایرکتوری کاری جاری یا متغیرهای محیطی، وابسته نیستند.
برای مثال، فرض کنید هر یک از تستهای شما کدی را اجرا میکند که یک فایل به نام test-output.txt روی دیسک ایجاد کرده و دادههایی در آن فایل مینویسد. سپس هر تست دادههای موجود در آن فایل را خوانده و تأیید میکند که فایل شامل یک مقدار خاص است، که در هر تست متفاوت است. چون تستها به طور همزمان اجرا میشوند، ممکن است یک تست فایل را در زمانی که تست دیگری در حال نوشتن و خواندن فایل است، بازنویسی کند. در این صورت، تست دوم شکست خواهد خورد، نه به این دلیل که کد اشتباه است بلکه به این دلیل که تستها در هنگام اجرای موازی با یکدیگر تداخل پیدا کردهاند. یک راهحل این است که مطمئن شوید هر تست به یک فایل متفاوت مینویسد؛ راهحل دیگر این است که تستها را یکی یکی اجرا کنید.
اگر نمیخواهید تستها به صورت موازی اجرا شوند یا اگر میخواهید کنترل بیشتری بر تعداد نخهای استفادهشده داشته باشید، میتوانید فلگ --test-threads و تعداد نخهایی که میخواهید استفاده کنید را به باینری تست ارسال کنید. به مثال زیر توجه کنید:
$ cargo test -- --test-threads=1
ما تعداد نخهای تست را به 1 تنظیم کردیم، به برنامه میگوییم از هیچ موازیسازی استفاده نکند. اجرای تستها با یک نخ بیشتر از اجرای آنها به صورت موازی طول میکشد، اما تستها در صورتی که حالت مشترکی داشته باشند با یکدیگر تداخل پیدا نمیکنند.
نمایش خروجی توابع
به طور پیشفرض، اگر یک تست پاس شود، کتابخانه تست Rust هر چیزی که به خروجی استاندارد چاپ شده را ضبط میکند. برای مثال، اگر در یک تست از println! استفاده کنیم و تست پاس شود، خروجی println! را در ترمینال نخواهیم دید؛ فقط خطی که نشان میدهد تست پاس شده است را خواهیم دید. اگر یک تست شکست بخورد، هر چیزی که به خروجی استاندارد چاپ شده باشد را همراه با پیام شکست خواهیم دید.
برای مثال، لیست ۱۱-۱۰ یک تابع ساده دارد که مقدار پارامتر خود را چاپ کرده و مقدار ۱۰ را بازمیگرداند، همچنین یک تست که پاس میشود و یک تست که شکست میخورد.
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}println! استفاده میکندوقتی این تستها را با cargo test اجرا میکنیم، خروجی زیر را خواهیم دید:
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
توجه کنید که در هیچ جای این خروجی I got the value 4 که هنگام اجرای تست پاسشده چاپ میشود، نمیبینیم. این خروجی ضبط شده است. خروجی تست شکستخورده، I got the value 8، در بخش خلاصه خروجی تست ظاهر میشود که علت شکست تست را نیز نشان میدهد.
اگر بخواهیم مقادیر چاپشده برای تستهای پاسشده را نیز ببینیم، میتوانیم به Rust بگوییم که خروجی تستهای موفق را با استفاده از --show-output نیز نمایش دهد:
$ cargo test -- --show-output
وقتی تستهای لیست ۱۱-۱۰ را دوباره با فلگ --show-output اجرا میکنیم، خروجی زیر را خواهیم دید:
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
اجرای زیرمجموعهای از تستها با نام
گاهی اوقات، اجرای یک مجموعه کامل از تستها میتواند زمان زیادی ببرد. اگر در حال کار روی کدی در یک بخش خاص هستید، ممکن است بخواهید فقط تستهای مربوط به آن کد را اجرا کنید. میتوانید با پاس دادن نام یا نامهای تستهایی که میخواهید اجرا کنید به cargo test، انتخاب کنید که کدام تستها اجرا شوند.
برای نشان دادن نحوه اجرای یک زیرمجموعه از تستها، ابتدا سه تست برای تابع add_two خود ایجاد میکنیم، همانطور که در لیست ۱۱-۱۱ نشان داده شده است، و انتخاب میکنیم کدامیک را اجرا کنیم.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}اگر تستها را بدون پاس دادن هیچ آرگومانی اجرا کنیم، همانطور که قبلاً دیدیم، تمام تستها به صورت موازی اجرا میشوند:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
اجرای تستهای منفرد
میتوانیم نام هر تابع تست را به cargo test پاس دهیم تا فقط همان تست اجرا شود:
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
فقط تستی با نام one_hundred اجرا شد؛ دو تست دیگر با این نام مطابقت نداشتند. خروجی تست به ما اطلاع میدهد که تستهای بیشتری وجود داشتهاند که اجرا نشدهاند و در انتها 2 filtered out را نمایش میدهد.
نمیتوانیم به این روش نام چندین تست را مشخص کنیم؛ فقط اولین مقداری که به cargo test داده میشود استفاده خواهد شد. اما راهی برای اجرای چندین تست وجود دارد.
فیلتر کردن برای اجرای چندین تست
میتوانیم بخشی از یک نام تست را مشخص کنیم، و هر تستی که نامش با آن مقدار مطابقت داشته باشد اجرا خواهد شد. برای مثال، چون دو تا از نامهای تستهای ما شامل add هستند، میتوانیم آن دو را با اجرای cargo test add اجرا کنیم:
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
این فرمان تمام تستهایی که add در نامشان دارند را اجرا کرد و تستی با نام one_hundred را فیلتر کرد. همچنین توجه داشته باشید که ماژولی که یک تست در آن ظاهر میشود بخشی از نام تست میشود، بنابراین میتوانیم تمام تستهای یک ماژول را با فیلتر کردن روی نام ماژول اجرا کنیم.
نادیده گرفتن برخی تستها مگر اینکه صریحاً درخواست شوند
گاهی اوقات چند تست خاص میتوانند بسیار وقتگیر باشند، بنابراین ممکن است بخواهید آنها را در اکثر اجراهای cargo test حذف کنید. به جای لیست کردن تمام تستهایی که میخواهید اجرا کنید، میتوانید تستهای وقتگیر را با استفاده از ویژگی ignore حاشیهنویسی کنید تا آنها را حذف کنید، همانطور که در اینجا نشان داده شده است:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}بعد از #[test]، خط #[ignore] را به تستی که میخواهیم حذف کنیم اضافه میکنیم. حالا وقتی تستهای خود را اجرا میکنیم، it_works اجرا میشود، اما expensive_test اجرا نمیشود:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
تابع expensive_test به عنوان ignored فهرست شده است. اگر بخواهیم فقط تستهای نادیدهگرفتهشده را اجرا کنیم، میتوانیم از cargo test -- --ignored استفاده کنیم:
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
با کنترل اینکه کدام تستها اجرا میشوند، میتوانید مطمئن شوید که نتایج cargo test شما به سرعت بازگردانده میشوند. وقتی در نقطهای هستید که منطقی است نتایج تستهای ignored را بررسی کنید و زمان برای انتظار نتایج دارید، میتوانید به جای آن cargo test -- --ignored را اجرا کنید. اگر میخواهید تمام تستها را اجرا کنید، چه نادیدهگرفتهشده و چه نشده، میتوانید cargo test -- --include-ignored را اجرا کنید.
سازماندهی تستها
همانطور که در ابتدای فصل ذکر شد، تستنویسی یک رشته پیچیده است، و افراد مختلف از اصطلاحات و سازماندهی متفاوتی استفاده میکنند. جامعه Rust تستها را به دو دسته اصلی تقسیم میکند: تستهای واحد و تستهای یکپارچه. تستهای واحد کوچک و متمرکزتر هستند، یک ماژول را به طور جداگانه در یک زمان تست میکنند و میتوانند رابطهای خصوصی را تست کنند. تستهای یکپارچه کاملاً خارجی نسبت به کتابخانه شما هستند و از کد شما همانطور که هر کد خارجی دیگری استفاده میکند، تنها از طریق رابط عمومی استفاده میکنند و ممکن است چندین ماژول را در هر تست بررسی کنند.
نوشتن هر دو نوع تست برای اطمینان از اینکه قطعات کتابخانه شما به صورت جداگانه و با هم کار میکنند، مهم است.
تستهای واحد
هدف تستهای واحد این است که هر واحد کد را به طور جداگانه از سایر کدها تست کنند تا به سرعت مشخص شود که کد کجا به درستی کار میکند و کجا نه. تستهای واحد را در دایرکتوری src در هر فایل با کدی که تست میکنند قرار میدهید. کنوانسیون این است که یک ماژول به نام tests در هر فایل ایجاد کنید تا توابع تست را در آن قرار دهید و ماژول را با cfg(test) حاشیهنویسی کنید.
ماژول تستها و #[cfg(test)]
حاشیهنویسی #[cfg(test)] روی ماژول tests به Rust میگوید که کد تست فقط وقتی که cargo test اجرا شود کامپایل و اجرا شود، نه وقتی که cargo build اجرا شود. این باعث صرفهجویی در زمان کامپایل وقتی فقط میخواهید کتابخانه را بسازید میشود و فضای کمتری در نتیجه کامپایلشده میگیرد زیرا تستها شامل نمیشوند. مشاهده خواهید کرد که چون تستهای یکپارچه در یک دایرکتوری جداگانه قرار میگیرند، نیازی به حاشیهنویسی #[cfg(test)] ندارند. با این حال، چون تستهای واحد در همان فایلهایی که کد قرار دارد قرار میگیرند، از #[cfg(test)] استفاده میکنید تا مشخص کنید که نباید در نتیجه کامپایلشده قرار گیرند.
به یاد بیاورید وقتی پروژه جدید adder را در بخش اول این فصل تولید کردیم، Cargo این کد را برای ما تولید کرد:
Filename: src/lib.rs
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}روی ماژول tests که به طور خودکار تولید شده است، ویژگی cfg مخفف پیکربندی است و به Rust میگوید که آیتم زیر فقط در صورت وجود یک گزینه پیکربندی مشخص گنجانده شود. در این مورد، گزینه پیکربندی test است، که توسط Rust برای کامپایل و اجرای تستها ارائه میشود. با استفاده از ویژگی cfg، Cargo کد تست ما را فقط در صورتی که تستها را به طور فعال با cargo test اجرا کنیم، کامپایل میکند. این شامل هر تابع کمکی که ممکن است در این ماژول باشد نیز میشود، علاوه بر توابعی که با #[test] حاشیهنویسی شدهاند.
تست توابع خصوصی
در جامعه تستنویسی بحثهایی درباره اینکه آیا توابع خصوصی باید مستقیماً تست شوند یا نه وجود دارد، و برخی زبانها تست کردن توابع خصوصی را دشوار یا غیرممکن میکنند. صرف نظر از اینکه از کدام ایدئولوژی تستنویسی پیروی میکنید، قوانین خصوصیسازی Rust به شما اجازه میدهند توابع خصوصی را تست کنید. کدی که در لیست ۱۱-۱۲ با تابع خصوصی internal_adder ارائه شده است را در نظر بگیرید.
pub fn add_two(a: u64) -> u64 {
internal_adder(a, 2)
}
fn internal_adder(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}توجه داشته باشید که تابع internal_adder بهصورت pub علامتگذاری نشده است.
تستها فقط کد Rust هستند و ماژول tests نیز یک ماژول عادی دیگر است.
همانطور که در بخش “مسیرها برای ارجاع به یک آیتم در درخت ماژول” بحث کردیم،
آیتمهای ماژولهای فرزند میتوانند از آیتمهای ماژولهای والد خود استفاده کنند.
در این تست، با استفاده از use super::* تمام آیتمهای ماژول والد tests وارد حوزه میشوند،
و سپس تست میتواند تابع internal_adder را فراخوانی کند.
اگر فکر میکنید توابع خصوصی نباید تست شوند، در Rust هیچ اجباری برای انجام این کار وجود ندارد.
تستهای یکپارچه
در Rust، تستهای یکپارچه کاملاً خارجی نسبت به کتابخانه شما هستند. آنها از کتابخانه شما همانطور که هر کد دیگری استفاده میکند استفاده میکنند، که به این معنی است که فقط میتوانند توابعی را که بخشی از رابط عمومی کتابخانه شما هستند فراخوانی کنند. هدف آنها این است که بررسی کنند آیا قسمتهای مختلف کتابخانه شما با یکدیگر به درستی کار میکنند یا نه. واحدهای کدی که به تنهایی به درستی کار میکنند میتوانند هنگام یکپارچهسازی مشکل داشته باشند، بنابراین پوشش تست کد یکپارچه نیز مهم است. برای ایجاد تستهای یکپارچه، ابتدا به یک دایرکتوری به نام tests نیاز دارید.
دایرکتوری tests
ما یک دایرکتوری به نام tests در سطح بالای دایرکتوری پروژه خود، در کنار src ایجاد میکنیم. Cargo میداند که باید به دنبال فایلهای تست یکپارچه در این دایرکتوری بگردد. سپس میتوانیم به هر تعداد فایل تست که میخواهیم ایجاد کنیم، و Cargo هر یک از فایلها را به عنوان یک crate جداگانه کامپایل میکند.
بیایید یک تست یکپارچه ایجاد کنیم. با کدی که هنوز در فایل src/lib.rs از لیست ۱۱-۱۲ قرار دارد، یک دایرکتوری tests ایجاد کنید و یک فایل جدید به نام tests/integration_test.rs بسازید. ساختار دایرکتوری شما باید به این صورت باشد:
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
کد موجود در لیست ۱۱-۱۳ را در فایل tests/integration_test.rs وارد کنید.
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}adderهر فایل در دایرکتوری tests یک crate جداگانه است، بنابراین باید کتابخانه خود را به دامنه هر crate تست وارد کنیم. به همین دلیل، در بالای کد use adder::add_two; را اضافه میکنیم، که در تستهای واحد نیازی به آن نداشتیم.
نیازی نیست هیچ کدی در فایل tests/integration_test.rs را با #[cfg(test)] علامتگذاری کنیم. Cargo دایرکتوری tests را به طور خاص مدیریت میکند و فایلهای موجود در این دایرکتوری را فقط زمانی که cargo test اجرا کنیم کامپایل میکند. اکنون cargo test را اجرا کنید:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
سه بخش خروجی شامل تستهای واحد، تست یکپارچه، و تستهای مستندات هستند. توجه داشته باشید که اگر هر تستی در یک بخش شکست بخورد، بخشهای بعدی اجرا نخواهند شد. برای مثال، اگر یک تست واحد شکست بخورد، هیچ خروجیای برای تستهای یکپارچه و مستندات وجود نخواهد داشت زیرا آن تستها فقط در صورتی اجرا میشوند که تمام تستهای واحد پاس شوند.
بخش اول برای تستهای واحد همان چیزی است که قبلاً دیدهایم: یک خط برای هر تست واحد (یکی به نام internal که در لیست ۱۱-۱۲ اضافه کردیم) و سپس یک خط خلاصه برای تستهای واحد.
بخش تستهای یکپارچه با خط Running tests/integration_test.rs شروع میشود. سپس یک خط برای هر تابع تست در آن تست یکپارچه و یک خط خلاصه برای نتایج تست یکپارچه دقیقاً قبل از شروع بخش Doc-tests adder وجود دارد.
هر فایل تست یکپارچه بخش خاص خود را دارد، بنابراین اگر فایلهای بیشتری در دایرکتوری tests اضافه کنیم، بخشهای بیشتری برای تستهای یکپارچه خواهیم داشت.
ما هنوز میتوانیم یک تابع تست خاص در یکپارچه را با مشخص کردن نام تابع تست به عنوان یک آرگومان برای cargo test اجرا کنیم. برای اجرای تمام تستهای یک فایل تست یکپارچه خاص، از آرگومان --test برای cargo test به همراه نام فایل استفاده کنید:
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
این فرمان فقط تستهای موجود در فایل tests/integration_test.rs را اجرا میکند.
زیرماژولها در تستهای یکپارچه
با اضافه کردن تستهای یکپارچه بیشتر، ممکن است بخواهید فایلهای بیشتری در دایرکتوری tests برای کمک به سازماندهی آنها ایجاد کنید؛ برای مثال، میتوانید توابع تست را بر اساس عملکردی که تست میکنند گروهبندی کنید. همانطور که قبلاً ذکر شد، هر فایل در دایرکتوری tests به عنوان یک crate جداگانه کامپایل میشود، که برای ایجاد دامنههای جداگانه مفید است تا بیشتر شبیه نحوه استفاده کاربران نهایی از crate شما باشد. با این حال، این به این معنی است که فایلهای موجود در دایرکتوری tests رفتار یکسانی با فایلهای موجود در src ندارند، همانطور که در فصل ۷ درباره جدا کردن کد به ماژولها و فایلها آموختید.
این رفتار متفاوت فایلهای دایرکتوری tests بیشترین توجه را زمانی جلب میکند که مجموعهای از توابع کمکی برای استفاده در چندین فایل تست یکپارچه دارید و سعی میکنید مراحل بخش “جدا کردن ماژولها به فایلهای مختلف” در فصل ۷ را برای استخراج آنها به یک ماژول مشترک دنبال کنید. برای مثال، اگر tests/common.rs ایجاد کنیم و یک تابع به نام setup در آن قرار دهیم، میتوانیم کدی به setup اضافه کنیم که میخواهیم از چندین تابع تست در چندین فایل تست فراخوانی کنیم:
Filename: tests/common.rs
pub fn setup() {
// setup code specific to your library's tests would go here
}وقتی دوباره تستها را اجرا میکنیم، یک بخش جدید در خروجی تست برای فایل common.rs خواهیم دید، حتی اگر این فایل هیچ تابع تستی ندارد و تابع setup را از هیچ جایی فراخوانی نکردهایم:
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
داشتن common در نتایج تست با running 0 tests نمایش داده شده برای آن، چیزی نبود که میخواستیم. ما فقط میخواستیم برخی کدها را با دیگر فایلهای تست یکپارچه به اشتراک بگذاریم. برای جلوگیری از نمایش common در خروجی تست، به جای ایجاد tests/common.rs، فایل tests/common/mod.rs را ایجاد میکنیم. اکنون ساختار دایرکتوری پروژه به این شکل است:
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
این روش نامگذاری قدیمیتر است که Rust نیز آن را میشناسد و در بخش “مسیرهای فایل جایگزین” در فصل ۷ به آن اشاره کردیم.
نامگذاری فایل به این صورت به Rust میگوید که ماژول common را به عنوان یک فایل تست یکپارچه (integration test) در نظر نگیرد.
وقتی کد تابع setup را به فایل tests/common/mod.rs منتقل کنیم و فایل tests/common.rs را حذف کنیم،
بخش مربوطه در خروجی تست دیگر ظاهر نخواهد شد.
فایلهای موجود در زیرشاخههای دایرکتوری tests به صورت crateهای جداگانه کامپایل نمیشوند
و در خروجی تست نیز بخش مجزایی ندارند.
پس از ایجاد tests/common/mod.rs، میتوانیم از آن به عنوان یک ماژول در هر یک از فایلهای تست یکپارچه استفاده کنیم. در اینجا یک مثال از فراخوانی تابع setup از تست it_adds_two در tests/integration_test.rs آمده است:
Filename: tests/integration_test.rs
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}توجه داشته باشید که اعلان mod common; مشابه اعلان ماژولی است که در لیست ۷-۲۱ نشان دادیم. سپس، در تابع تست، میتوانیم تابع common::setup() را فراخوانی کنیم.
تستهای یکپارچه برای crateهای دودویی
اگر پروژه ما یک crate دودویی باشد که فقط شامل یک فایل src/main.rs است و فایل src/lib.rs ندارد، نمیتوانیم تستهای یکپارچه را در دایرکتوری tests ایجاد کنیم و توابع تعریفشده در فایل src/main.rs را با یک عبارت use به دامنه وارد کنیم. فقط crateهای کتابخانهای توابعی را که سایر crateها میتوانند استفاده کنند در معرض قرار میدهند؛ crateهای دودویی برای اجرای مستقل طراحی شدهاند.
این یکی از دلایلی است که پروژههای Rust که یک دودویی ارائه میدهند، معمولاً یک فایل src/main.rs ساده دارند که به منطق موجود در فایل src/lib.rs فراخوانی میکند. با استفاده از این ساختار، تستهای یکپارچه میتوانند crate کتابخانهای را با use تست کنند تا قابلیت مهم را در دسترس قرار دهند. اگر قابلیت مهم کار کند، مقدار کمی کد در فایل src/main.rs نیز کار خواهد کرد، و نیازی به تست آن مقدار کم از کد نیست.
خلاصه
ویژگیهای تستنویسی در Rust راهی برای مشخص کردن نحوه عملکرد کد فراهم میکنند تا اطمینان حاصل شود که کد همانطور که انتظار میرود کار میکند، حتی زمانی که تغییراتی در آن ایجاد میکنید. تستهای واحد بخشهای مختلف یک کتابخانه را به طور جداگانه آزمایش میکنند و میتوانند جزئیات پیادهسازی خصوصی را تست کنند. تستهای یکپارچه بررسی میکنند که آیا بخشهای مختلف کتابخانه به درستی با یکدیگر کار میکنند یا نه، و از رابط عمومی کتابخانه برای تست کد به همان روشی که کد خارجی از آن استفاده میکند، استفاده میکنند. حتی با وجود اینکه سیستم نوعها و قوانین مالکیت در Rust به جلوگیری از برخی انواع باگها کمک میکند، تستها همچنان برای کاهش باگهای منطقی که به نحوه عملکرد مورد انتظار کد مربوط میشوند، مهم هستند.
بیایید دانش خود را که در این فصل و فصلهای قبلی یاد گرفتید، ترکیب کرده و روی یک پروژه کار کنیم!
یک پروژه ورودی/خروجی: ساخت یک برنامه خط فرمان
این فصل مروری بر بسیاری از مهارتهایی است که تا کنون آموختهاید و همچنین بررسی چند ویژگی دیگر از کتابخانه استاندارد. ما یک ابزار خط فرمان خواهیم ساخت که با ورودی/خروجی فایل و خط فرمان تعامل میکند تا برخی از مفاهیم Rust را که اکنون در اختیار دارید تمرین کنیم.
سرعت، ایمنی، خروجی تکباینری و پشتیبانی چندپلتفرمی Rust، آن را به زبانی ایدهآل برای ایجاد ابزارهای خط فرمان تبدیل میکند. بنابراین برای پروژه خود، نسخهای از ابزار جستجوی خط فرمان کلاسیک grep (globally search a regular expression and print) را خواهیم ساخت. در سادهترین حالت، grep یک فایل مشخص را برای یک رشته مشخص جستجو میکند. برای انجام این کار، grep به عنوان آرگومانهای خود مسیر فایل و یک رشته را دریافت میکند. سپس فایل را میخواند، خطوطی که شامل آرگومان رشته هستند را پیدا میکند و آن خطوط را چاپ میکند.
در طول مسیر، نشان خواهیم داد که چگونه ابزار خط فرمان ما از ویژگیهای ترمینال استفاده کند که بسیاری از ابزارهای خط فرمان دیگر از آنها استفاده میکنند. مقدار یک متغیر محیطی را برای اجازه به کاربر برای پیکربندی رفتار ابزار خود میخوانیم. همچنین پیامهای خطا را به جریان کنسول خطای استاندارد (stderr) به جای خروجی استاندارد (stdout) چاپ میکنیم تا مثلاً کاربر بتواند خروجی موفقیتآمیز را به یک فایل هدایت کند در حالی که هنوز پیامهای خطا را روی صفحه مشاهده میکند.
یکی از اعضای جامعه Rust، Andrew Gallant، نسخهای کامل، بسیار سریع از grep به نام ripgrep ایجاد کرده است. در مقایسه، نسخه ما نسبتاً ساده خواهد بود، اما این فصل به شما برخی از دانشهای پایهای که برای درک پروژههای واقعی مانند ripgrep نیاز دارید را خواهد داد.
پروژه grep ما ترکیبی از تعدادی مفاهیمی است که تاکنون آموختهاید:
- سازماندهی کد (فصل ۷)
- استفاده از بردارها و رشتهها (فصل ۸)
- مدیریت خطاها (فصل ۹)
- استفاده از صفات و طول عمرها در موارد مناسب (فصل ۱۰)
- نوشتن تستها (فصل ۱۱)
همچنین به طور مختصر به معرفی closures، iterators، و trait objects میپردازیم که به طور کامل در فصل ۱۳ و فصل ۱۸ پوشش داده خواهند شد.
پذیرش آرگومانهای خط فرمان
بیایید با استفاده از cargo new یک پروژه جدید ایجاد کنیم. پروژه خود را minigrep مینامیم تا آن را از ابزار grep که ممکن است در سیستم شما وجود داشته باشد متمایز کنیم.
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
اولین کار این است که minigrep آرگومانهای خط فرمان خود، شامل مسیر فایل و رشتهای برای جستجو، را بپذیرد. به عبارت دیگر، میخواهیم بتوانیم برنامه خود را با cargo run، دو خط تیره برای نشان دادن اینکه آرگومانهای بعدی برای برنامه ما هستند و نه برای cargo، یک رشته برای جستجو و یک مسیر فایل برای جستجو اجرا کنیم، مانند زیر:
$ cargo run -- searchstring example-filename.txt
در حال حاضر، برنامهای که توسط cargo new تولید شده است نمیتواند آرگومانهایی که به آن میدهیم را پردازش کند. برخی کتابخانههای موجود در crates.io میتوانند برای نوشتن برنامهای که آرگومانهای خط فرمان را بپذیرد کمک کنند، اما چون شما تازه با این مفهوم آشنا میشوید، بیایید این قابلیت را خودمان پیادهسازی کنیم.
خواندن مقادیر آرگومانها
برای اینکه minigrep بتواند مقادیر آرگومانهای خط فرمان را که به آن میدهیم بخواند، به تابع std::env::args که در کتابخانه استاندارد Rust ارائه شده است نیاز خواهیم داشت. این تابع یک iterator از آرگومانهای خط فرمانی که به minigrep داده شده است بازمیگرداند. ما در فصل ۱۳ به طور کامل iteratorها را پوشش خواهیم داد. در حال حاضر، فقط باید دو نکته درباره iteratorها بدانید: iteratorها یک سری مقادیر تولید میکنند و ما میتوانیم تابع collect را روی یک iterator فراخوانی کنیم تا آن را به یک collection، مانند یک بردار، که شامل تمام عناصر تولیدشده توسط iterator است، تبدیل کنیم.
کد موجود در لیست ۱۲-۱ به برنامه minigrep شما اجازه میدهد تا هر آرگومان خط فرمانی که به آن داده شده را بخواند و سپس مقادیر را به یک بردار جمعآوری کند.
use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
ابتدا ماژول std::env را با یک دستور use به دامنه وارد میکنیم تا بتوانیم از تابع args آن استفاده کنیم. توجه کنید که تابع std::env::args در دو سطح ماژول تو در تو قرار دارد. همانطور که در فصل ۷ بحث کردیم، در مواردی که تابع موردنظر در بیش از یک ماژول تو در تو قرار دارد، ترجیح میدهیم ماژول والد را به دامنه وارد کنیم نه تابع. با این کار، میتوانیم به راحتی از توابع دیگر std::env استفاده کنیم. همچنین این روش کمتر مبهم است نسبت به اضافه کردن use std::env::args و سپس فراخوانی تابع با فقط args، چون args ممکن است به راحتی با یک تابع تعریفشده در ماژول جاری اشتباه گرفته شود.
تابع args و یونیکد نامعتبر
توجه داشته باشید که std::env::args اگر هر آرگومانی شامل یونیکد نامعتبر باشد، پانیک خواهد کرد. اگر برنامه شما نیاز به پذیرش آرگومانهایی با یونیکد نامعتبر دارد، به جای آن از std::env::args_os استفاده کنید. این تابع یک iterator بازمیگرداند که مقادیر OsString به جای String تولید میکند. ما برای سادگی std::env::args را اینجا انتخاب کردهایم زیرا مقادیر OsString بسته به پلتفرم متفاوت هستند و کار با آنها پیچیدهتر از مقادیر String است.
در اولین خط از تابع main، ما تابع env::args را فراخوانی میکنیم و بلافاصله از تابع collect استفاده میکنیم تا iterator را به یک بردار که شامل تمام مقادیر تولیدشده توسط iterator است، تبدیل کنیم. میتوانیم از تابع collect برای ایجاد انواع مختلفی از collectionها استفاده کنیم، بنابراین نوع args را به طور صریح با ذکر میکنیم که میخواهیم یک بردار از رشتهها داشته باشیم. با اینکه به ندرت نیاز به ذکر نوعها در Rust دارید، تابع collect یکی از تابعهایی است که اغلب باید نوع آن را ذکر کنید، زیرا Rust نمیتواند نوع collection مورد نظر شما را استنباط کند.
در نهایت، بردار را با استفاده از ماکروی debug چاپ میکنیم. بیایید ابتدا کد را بدون آرگومان اجرا کنیم و سپس با دو آرگومان:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
توجه کنید که اولین مقدار در بردار "target/debug/minigrep" است، که نام باینری ما است. این رفتار با لیست آرگومانها در زبان C مطابقت دارد و به برنامهها اجازه میدهد از نامی که با آن اجرا شدهاند، در اجرای خود استفاده کنند. دسترسی به نام برنامه اغلب مفید است، مثلاً برای چاپ آن در پیامها یا تغییر رفتار برنامه بر اساس نام مستعار خط فرمانی که برای اجرای برنامه استفاده شده است. اما برای اهداف این فصل، آن را نادیده میگیریم و فقط دو آرگومان مورد نیاز را ذخیره میکنیم.
ذخیره مقادیر آرگومانها در متغیرها
در حال حاضر، برنامه قادر به دسترسی به مقادیر مشخصشده به عنوان آرگومانهای خط فرمان است. اکنون نیاز داریم مقادیر دو آرگومان را در متغیرهایی ذخیره کنیم تا بتوانیم از آنها در بقیه برنامه استفاده کنیم. این کار را در لیست ۱۲-۲ انجام میدهیم.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}همانطور که هنگام چاپ بردار مشاهده کردیم، نام برنامه اولین مقدار در بردار را در args[0] اشغال میکند، بنابراین آرگومانها را از اندیس (index)۱ شروع میکنیم. اولین آرگومان که minigrep دریافت میکند، رشتهای است که میخواهیم جستجو کنیم، بنابراین یک مرجع به اولین آرگومان را در متغیر query قرار میدهیم. آرگومان دوم مسیر فایل خواهد بود، بنابراین یک مرجع به آرگومان دوم را در متغیر file_path قرار میدهیم.
ما به طور موقت مقادیر این متغیرها را چاپ میکنیم تا اثبات کنیم که کد همانطور که میخواهیم کار میکند. بیایید دوباره این برنامه را با آرگومانهای test و sample.txt اجرا کنیم:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
عالی است، برنامه کار میکند! مقادیر آرگومانهای مورد نیاز ما در متغیرهای درست ذخیره میشوند. بعداً برخی از خطاها را مدیریت خواهیم کرد، مثل وقتی که کاربر هیچ آرگومانی ارائه نمیدهد؛ فعلاً، آن شرایط را نادیده میگیریم و روی افزودن قابلیت خواندن فایل تمرکز میکنیم.
خواندن یک فایل
اکنون قابلیت خواندن فایل مشخصشده در آرگومان file_path را اضافه میکنیم. ابتدا به یک فایل نمونه برای تست نیاز داریم: از یک فایل با مقدار کمی متن در چندین خط که برخی کلمات در آن تکرار شدهاند استفاده میکنیم. لیست ۱۲-۳ شامل شعری از امیلی دیکینسون است که به خوبی برای این منظور مناسب است! یک فایل به نام poem.txt در سطح اصلی پروژه خود ایجاد کنید و شعر “I’m Nobody! Who are you?” را وارد کنید.
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
با متن در جای خود، فایل src/main.rs را ویرایش کرده و کدی برای خواندن فایل اضافه کنید، همانطور که در لیست ۱۲-۴ نشان داده شده است.
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}ابتدا بخشی مرتبط از کتابخانه استاندارد را با یک دستور use وارد میکنیم: برای مدیریت فایلها به std::fs نیاز داریم.
در تابع main، دستور جدید fs::read_to_string مقدار file_path را میگیرد، آن فایل را باز میکند و مقداری از نوع std::io::Result<String> را که شامل محتوای فایل است، بازمیگرداند.
پس از آن، دوباره یک دستور موقت println! اضافه میکنیم که مقدار contents را پس از خواندن فایل چاپ میکند تا مطمئن شویم برنامه تا اینجا کار میکند.
بیایید این کد را با هر رشتهای به عنوان اولین آرگومان خط فرمان (چون هنوز بخش جستجو را پیادهسازی نکردهایم) و فایل poem.txt به عنوان آرگومان دوم اجرا کنیم:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
عالی است! کد محتوای فایل را خواند و سپس چاپ کرد. اما کد چند نقص دارد. در حال حاضر، تابع main چندین مسئولیت دارد: به طور کلی، توابع واضحتر و آسانتر برای نگهداری هستند اگر هر تابع فقط مسئول یک ایده باشد. مشکل دیگر این است که ما خطاها را به خوبی مدیریت نمیکنیم. برنامه هنوز کوچک است، بنابراین این مشکلات مشکل بزرگی نیستند، اما با رشد برنامه، رفع آنها به صورت تمیز سختتر خواهد شد. بهتر است که زودتر در فرایند توسعه برنامه شروع به بازسازی کنیم، زیرا بازسازی کدهای کمتر بسیار آسانتر است. در مرحله بعد این کار را انجام خواهیم داد.
Refactoring to Improve Modularity and Error Handling
To improve our program, we’ll fix four problems that have to do with the
program’s structure and how it’s handling potential errors. First, our main
function now performs two tasks: it parses arguments and reads files. As our
program grows, the number of separate tasks the main function handles will
increase. As a function gains responsibilities, it becomes more difficult to
reason about, harder to test, and harder to change without breaking one of its
parts. It’s best to separate functionality so each function is responsible for
one task.
This issue also ties into the second problem: although query and file_path
are configuration variables to our program, variables like contents are used
to perform the program’s logic. The longer main becomes, the more variables
we’ll need to bring into scope; the more variables we have in scope, the harder
it will be to keep track of the purpose of each. It’s best to group the
configuration variables into one structure to make their purpose clear.
The third problem is that we’ve used expect to print an error message when
reading the file fails, but the error message just prints Should have been able to read the file. Reading a file can fail in a number of ways: for
example, the file could be missing, or we might not have permission to open it.
Right now, regardless of the situation, we’d print the same error message for
everything, which wouldn’t give the user any information!
Fourth, we use expect to handle an error, and if the user runs our program
without specifying enough arguments, they’ll get an index out of bounds error
from Rust that doesn’t clearly explain the problem. It would be best if all the
error-handling code were in one place so future maintainers had only one place
to consult the code if the error-handling logic needed to change. Having all the
error-handling code in one place will also ensure that we’re printing messages
that will be meaningful to our end users.
Let’s address these four problems by refactoring our project.
Separation of Concerns for Binary Projects
The organizational problem of allocating responsibility for multiple tasks to
the main function is common to many binary projects. As a result, the Rust
community has developed guidelines for splitting the separate concerns of a
binary program when main starts getting large. This process has the following
steps:
- Split your program into a main.rs file and a lib.rs file and move your program’s logic to lib.rs.
- As long as your command line parsing logic is small, it can remain in main.rs.
- When the command line parsing logic starts getting complicated, extract it from main.rs and move it to lib.rs.
The responsibilities that remain in the main function after this process
should be limited to the following:
- Calling the command line parsing logic with the argument values
- Setting up any other configuration
- Calling a
runfunction in lib.rs - Handling the error if
runreturns an error
This pattern is about separating concerns: main.rs handles running the
program and lib.rs handles all the logic of the task at hand. Because you
can’t test the main function directly, this structure lets you test all of
your program’s logic by moving it into functions in lib.rs. The code that
remains in main.rs will be small enough to verify its correctness by reading
it. Let’s rework our program by following this process.
Extracting the Argument Parser
We’ll extract the functionality for parsing arguments into a function that
main will call to prepare for moving the command line parsing logic to
src/lib.rs. Listing 12-5 shows the new start of main that calls a new
function parse_config, which we’ll define in src/main.rs for the moment.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}parse_config از mainما همچنان آرگومانهای خط فرمان را به یک بردار جمعآوری میکنیم، اما به جای اینکه مقدار آرگومان در اندیس (index)۱ را به متغیر query و مقدار آرگومان در اندیس (index)۲ را به متغیر file_path در تابع main اختصاص دهیم، کل بردار را به تابع parse_config ارسال میکنیم. تابع parse_config سپس منطق مشخص میکند که کدام آرگومان در کدام متغیر قرار میگیرد و مقادیر را به تابع main بازمیگرداند. ما همچنان متغیرهای query و file_path را در main ایجاد میکنیم، اما main دیگر مسئول تعیین ارتباط آرگومانهای خط فرمان و متغیرها نیست.
این تغییر ممکن است برای برنامه کوچک ما زیادهروی به نظر برسد، اما ما در حال بازسازی کد به صورت گامهای کوچک و تدریجی هستیم. پس از اعمال این تغییر، دوباره برنامه را اجرا کنید تا اطمینان حاصل کنید که تجزیه آرگومان همچنان کار میکند. بررسی مداوم پیشرفت کد کمک میکند تا در صورت بروز مشکلات، علت آنها را سریعتر شناسایی کنید.
گروهبندی مقادیر پیکربندی
میتوانیم یک گام کوچک دیگر برای بهبود بیشتر تابع parse_config برداریم. در حال حاضر، ما یک tuple بازمیگردانیم، اما بلافاصله آن tuple را به قسمتهای جداگانه تقسیم میکنیم. این نشانهای است که شاید هنوز انتزاع درستی نداریم.
نشانه دیگری که نشان میدهد جا برای بهبود وجود دارد، قسمت config در parse_config است، که نشان میدهد دو مقداری که بازمیگردانیم به هم مرتبط هستند و هر دو بخشی از یک مقدار پیکربندی هستند. ما در حال حاضر این معنا را در ساختار دادهها به جز با گروهبندی دو مقدار در یک tuple منتقل نمیکنیم؛ در عوض، این دو مقدار را در یک struct قرار میدهیم و به هر یک از فیلدهای struct نامی معنادار میدهیم. انجام این کار درک نحوه ارتباط مقادیر مختلف و هدف آنها را برای نگهداریکنندگان آینده این کد آسانتر میکند.
لیست ۱۲-۶ بهبودهای تابع parse_config را نشان میدهد.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}parse_config برای بازگرداندن یک نمونه از struct Configما یک ساختار جدید به نام Config تعریف کردهایم که دارای فیلدهایی با نامهای query و file_path است. امضای تابع parse_config اکنون نشان میدهد که این تابع یک مقدار Config را بازمیگرداند. در بدنه تابع parse_config، جایی که قبلاً اسلایسهای رشتهای را که به مقادیر String در args اشاره میکردند بازمیگرداندیم، اکنون Config را طوری تعریف میکنیم که دارای مقادیر String متعلق به خود باشد.
متغیر args در تابع main مالک مقادیر آرگومان است و فقط به تابع parse_config اجازه قرض گرفتن آنها را میدهد، به این معنی که اگر Config بخواهد مالک مقادیر در args شود، قوانین قرضگیری Rust را نقض میکنیم.
چندین روش برای مدیریت دادههای String وجود دارد؛ سادهترین و شاید ناکارآمدترین روش، فراخوانی متد clone روی مقادیر است. این کار یک کپی کامل از دادهها برای نمونه Config ایجاد میکند که مالک آن است. این روش زمان و حافظه بیشتری نسبت به ذخیره یک مرجع به دادهها نیاز دارد. با این حال، کپی کردن دادهها باعث میشود که کد ما بسیار ساده شود زیرا نیازی به مدیریت طول عمر مراجع نداریم؛ در این شرایط، از دست دادن کمی کارایی برای دستیابی به سادگی ارزشمند است.
هزینهها و مزایای استفاده از clone
در بین بسیاری از برنامهنویسان Rust، تمایلی به استفاده از clone برای رفع مشکلات مالکیت به دلیل هزینه اجرای آن وجود دارد. در فصل ۱۳، یاد خواهید گرفت که چگونه در این نوع موقعیتها از روشهای کارآمدتر استفاده کنید. اما در حال حاضر، کپی کردن چند رشته برای ادامه پیشرفت اشکالی ندارد زیرا این کپیها فقط یکبار انجام میشوند و مسیر فایل و رشته جستجوی شما بسیار کوچک هستند. بهتر است یک برنامه کارا که کمی ناکارآمد است داشته باشید تا اینکه در اولین تلاش خود برای نوشتن کد، بهینهسازی بیش از حد انجام دهید. با تجربه بیشتر در Rust، شروع با راهحل کارآمدتر آسانتر خواهد بود، اما در حال حاضر استفاده از clone کاملاً قابل قبول است.
ما تابع main را بهروزرسانی کردیم تا نمونهای از Config که توسط parse_config بازگردانده میشود را در یک متغیر به نام config قرار دهد، و کدی که قبلاً از متغیرهای جداگانه query و file_path استفاده میکرد، اکنون از فیلدهای موجود در struct Config استفاده میکند.
اکنون کد ما بهوضوح نشان میدهد که query و file_path به هم مرتبط هستند و هدف آنها تنظیم نحوه کار برنامه است. هر کدی که از این مقادیر استفاده میکند میداند که باید آنها را در نمونه config در فیلدهایی که نام آنها برای هدفشان انتخاب شده است، پیدا کند.
ایجاد سازنده برای Config
تا اینجا، منطق مسئول تجزیه آرگومانهای خط فرمان را از main استخراج کرده و در تابع parse_config قرار دادهایم. این کار به ما کمک کرد ببینیم که مقادیر query و file_path به هم مرتبط هستند و این رابطه باید در کد ما منتقل شود. سپس یک struct به نام Config اضافه کردیم تا هدف مشترک query و file_path را نامگذاری کنیم و بتوانیم نام مقادیر را بهعنوان فیلدهای struct از تابع parse_config بازگردانیم.
حالا که هدف تابع parse_config ایجاد یک نمونه از Config است، میتوانیم parse_config را از یک تابع معمولی به یک تابع با نام new تغییر دهیم که به struct Config مرتبط است. این تغییر کد را بهصورت idiomaticتر میکند. ما میتوانیم نمونههایی از انواع موجود در کتابخانه استاندارد، مانند String، را با فراخوانی String::new ایجاد کنیم. به همین ترتیب، با تغییر parse_config به تابع new مرتبط با Config، میتوانیم نمونههایی از Config را با فراخوانی Config::new ایجاد کنیم. لیست ۱۲-۷ تغییرات لازم را نشان میدهد.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}parse_config به Config::newما تابع main را که در آن parse_config را فراخوانی میکردیم بهروزرسانی کردهایم تا بهجای آن Config::new را فراخوانی کند. نام parse_config را به new تغییر داده و آن را در یک بلوک impl قرار دادهایم که تابع new را به Config مرتبط میکند. کد را دوباره کامپایل کنید تا مطمئن شوید که کار میکند.
رفع مشکلات مدیریت خطا
حالا روی رفع مشکلات مدیریت خطا کار میکنیم. به خاطر بیاورید که تلاش برای دسترسی به مقادیر موجود در بردار args در اندیس (index)۱ یا ۲ باعث میشود برنامه در صورت داشتن کمتر از سه آیتم، دچار وحشت شود. برنامه را بدون هیچ آرگومانی اجرا کنید؛ این حالت به شکل زیر خواهد بود:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
خط index out of bounds: the len is 1 but the index is 1 یک پیام خطا است که برای برنامهنویسان در نظر گرفته شده است. این پیام به کاربران نهایی کمکی نمیکند تا بفهمند باید چه کار کنند. حالا این مشکل را رفع میکنیم.
بهبود پیام خطا
در لیست ۱۲-۸، یک بررسی در تابع new اضافه میکنیم که بررسی میکند آیا آرایه بهاندازه کافی طولانی است تا بتوان به اندیسهای ۱ و ۲ دسترسی داشت. اگر طول آرایه کافی نباشد، برنامه دچار وحشت میشود و یک پیام خطای بهتر نمایش میدهد.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}این کد شبیه به تابع Guess::new که در لیست ۹-۱۳ نوشتیم است، جایی که وقتی آرگومان value خارج از محدوده مقادیر معتبر بود، panic! فراخوانی کردیم. به جای بررسی محدوده مقادیر، در اینجا بررسی میکنیم که طول args حداقل برابر با 3 باشد و بقیه تابع میتواند با فرض اینکه این شرط برقرار شده است، عمل کند. اگر args کمتر از سه آیتم داشته باشد، این شرط true خواهد بود و ما ماکرو panic! را برای خاتمه برنامه بلافاصله فراخوانی میکنیم.
با این چند خط اضافی در new، بیایید دوباره برنامه را بدون هیچ آرگومانی اجرا کنیم تا ببینیم اکنون پیام خطا چگونه است:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
این خروجی بهتر است: اکنون یک پیام خطای منطقی داریم. با این حال، هنوز اطلاعات اضافی داریم که نمیخواهیم به کاربران خود ارائه دهیم. شاید تکنیکی که در لیست ۹-۱۳ استفاده کردیم بهترین گزینه برای اینجا نباشد: یک فراخوانی به panic! برای مشکل برنامهنویسی مناسبتر است تا یک مشکل استفاده، همانطور که در فصل ۹ بحث شد. در عوض، از تکنیک دیگری که در فصل ۹ یاد گرفتید استفاده میکنیم—بازگرداندن یک Result که نشاندهنده موفقیت یا خطا است.
بازگرداندن یک Result به جای فراخوانی panic!
ما میتوانیم به جای آن، یک مقدار Result بازگردانیم که در صورت موفقیت شامل یک نمونه از Config باشد و در صورت خطا مشکل را توصیف کند. همچنین قصد داریم نام تابع را از new به build تغییر دهیم زیرا بسیاری از برنامهنویسان انتظار دارند که توابع new هرگز شکست نخورند. وقتی Config::build با main ارتباط برقرار میکند، میتوانیم از نوع Result برای اعلام مشکل استفاده کنیم. سپس میتوانیم main را تغییر دهیم تا یک واریانت Err را به یک پیام خطای عملیتر برای کاربران خود تبدیل کنیم، بدون متنهای اضافی مربوط به thread 'main' و RUST_BACKTRACE که یک فراخوانی به panic! ایجاد میکند.
لیست ۱۲-۹ تغییراتی را که باید در مقدار بازگشتی تابع که اکنون آن را Config::build مینامیم و بدنه تابع برای بازگرداندن یک Result ایجاد کنیم، نشان میدهد. توجه داشته باشید که این کد تا زمانی که main را نیز بهروزرسانی نکنیم کامپایل نمیشود، که این کار را در لیست بعدی انجام خواهیم داد.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Result از Config::buildتابع build و بازگشت مقدار Result
تابع build ما اکنون یک مقدار Result را بازمیگرداند که در صورت موفقیت شامل یک نمونه از Config و در صورت خطا یک مقدار رشتهای ثابت (string literal) است. مقادیر خطای ما همیشه رشتههای ثابت با طول عمر 'static خواهند بود.
ما دو تغییر در بدنه تابع ایجاد کردهایم: به جای فراخوانی panic! زمانی که کاربر آرگومانهای کافی ارائه نمیدهد، اکنون یک مقدار Err بازمیگردانیم و مقدار بازگشتی Config را در یک Ok قرار دادهایم. این تغییرات باعث میشوند تابع با امضای نوع جدید خود سازگار باشد.
بازگرداندن مقدار Err از Config::build به تابع main اجازه میدهد که مقدار Result بازگشتی از تابع build را مدیریت کرده و در صورت بروز خطا، فرآیند را به شکلی تمیزتر خاتمه دهد.
فراخوانی Config::build و مدیریت خطاها
برای مدیریت حالت خطا و چاپ یک پیام دوستانه برای کاربر، باید تابع main را بهروزرسانی کنیم تا مقدار Result بازگرداندهشده توسط Config::build را مدیریت کند. این کار در لیست ۱۲-۱۰ نشان داده شده است. همچنین مسئولیت خاتمه دادن ابزار خط فرمان با کد خطای غیر صفر را از panic! گرفته و به صورت دستی پیادهسازی خواهیم کرد. کد خروجی غیر صفر به عنوان یک قرارداد برای اعلام وضعیت خطا به فرآیندی که برنامه ما را فراخوانده است، استفاده میشود.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Configدر این لیستینگ، ما از متدی استفاده کردهایم که هنوز جزئیات آن را بهطور کامل پوشش ندادهایم: unwrap_or_else. این متد که در استاندارد کتابخانه Rust برای Result<T, E> تعریف شده است، به ما امکان میدهد مدیریت خطاهای سفارشی و بدون استفاده از panic! را تعریف کنیم. اگر مقدار Result از نوع Ok باشد، رفتار این متد مشابه unwrap است: مقدار داخلی که Ok در خود قرار داده را بازمیگرداند. با این حال، اگر مقدار از نوع Err باشد، این متد کدی را که در closure تعریف کردهایم اجرا میکند. Closure یک تابع ناشناس است که آن را تعریف کرده و بهعنوان آرگومان به unwrap_or_else ارسال میکنیم.
ما closures را به تفصیل در فصل ۱۳ توضیح خواهیم داد. فعلاً کافی است بدانید که unwrap_or_else مقدار داخلی Err را به closure میدهد. در اینجا، مقدار استاتیک "not enough arguments" که در لیستینگ 12-9 اضافه کردیم، به closure ارسال شده و به آرگومان err تخصیص داده میشود، که بین خط عمودیها قرار دارد. کد درون closure سپس میتواند از مقدار err استفاده کند.
ما همچنین یک خط جدید use اضافه کردهایم تا process را از کتابخانه استاندارد به محدوده بیاوریم. کدی که در حالت خطا اجرا میشود تنها شامل دو خط است: ابتدا مقدار err را چاپ میکنیم و سپس process::exit را فراخوانی میکنیم. تابع process::exit بلافاصله برنامه را متوقف کرده و عددی که بهعنوان کد وضعیت خروج ارسال شده است را بازمیگرداند. این روش شبیه مدیریت مبتنی بر panic! است که در لیستینگ 12-8 استفاده کردیم، اما دیگر خروجی اضافی تولید نمیشود. حالا آن را آزمایش کنیم:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
عالی! این خروجی برای کاربران ما بسیار دوستانهتر است.
Extracting Logic from main
Now that we’ve finished refactoring the configuration parsing, let’s turn to
the program’s logic. As we stated in “Separation of Concerns for Binary
Projects”, we’ll
extract a function named run that will hold all the logic currently in the
main function that isn’t involved with setting up configuration or handling
errors. When we’re done, main will be concise and easy to verify by
inspection, and we’ll be able to write tests for all the other logic.
Listing 12-11 shows the extracted run function. For now, we’re just making
the small, incremental improvement of extracting the function. We’re still
defining the function in src/main.rs.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:\n{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run از mainبا این تغییرات، main اکنون تابع run را فراخوانی میکند و مسئولیت اجرای منطق اصلی برنامه را به آن واگذار میکند. این جداسازی باعث میشود تابع main سادهتر شود و ما بتوانیم تستهای دقیقی برای بخشهای مختلف کد بنویسیم. این روش به بهبود قابلیت نگهداری و خوانایی کد کمک شایانی میکند.
بازگرداندن خطاها از تابع run
اکنون که منطق باقیمانده برنامه را در تابع run جدا کردهایم، میتوانیم مانند Config::build در لیستینگ 12-9، مدیریت خطا را بهبود بخشیم. به جای اجازه دادن به برنامه برای اجرای panic با فراخوانی expect، تابع run در صورت بروز مشکل یک Result<T, E> بازمیگرداند. این رویکرد به ما امکان میدهد منطق مرتبط با مدیریت خطا را به صورت کاربرپسندانهای در تابع main متمرکز کنیم. تغییرات لازم برای امضا و بدنه تابع run در لیستینگ 12-12 نشان داده شده است:
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run برای بازگرداندن Resultتغییرات مهم
-
تغییر نوع بازگشتی:
نوع بازگشتی تابع
runبهResult<(), Box<dyn Error>>تغییر داده شده است. این تابع قبلاً نوع واحد (()) را بازمیگرداند، که همچنان برای حالت موفقیت حفظ شده است. برای نوع خطا از یک شیء صفات به نامBox<dyn Error>استفاده کردهایم (و با استفاده ازuse،std::error::Errorرا به محدوده آوردهایم). در فصل 18 بیشتر درباره شیء صفات صحبت خواهیم کرد. فعلاً کافی است بدانید کهBox<dyn Error>به این معنا است که تابع میتواند نوعی از مقدار را که صفتErrorرا پیادهسازی کرده بازگرداند، بدون اینکه نوع خاصی را مشخص کند. کلمه کلیدیdynبه معنای دینامیک است. -
حذف
expectو استفاده از عملگر?: به جای استفاده ازpanic!در صورت بروز خطا، عملگر?مقدار خطا را از تابع جاری بازمیگرداند تا فراخوانیکننده بتواند آن را مدیریت کند. -
بازگرداندن مقدار
Okدر حالت موفقیت: تابعrunاکنون در حالت موفقیت مقدارOkرا بازمیگرداند. ما نوع موفقیت تابع را به عنوان()در امضا تعریف کردهایم، که به این معنا است که باید مقدار نوع واحد را در مقدارOkقرار دهیم. نحوOk(())ممکن است در ابتدا کمی عجیب به نظر برسد، اما استفاده از()به این صورت روش استاندارد برای نشان دادن این است که تابعrunتنها برای تأثیرات جانبی فراخوانی شده و مقداری بازنمیگرداند که به آن نیاز داشته باشیم.
بررسی کد
اجرای این کد باعث میشود که کد کامپایل شود اما یک هشدار نمایش دهد:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust به ما یادآوری میکند که کد ما مقدار Result را نادیده گرفته است و این مقدار ممکن است نشاندهنده بروز خطا باشد. اما ما بررسی نمیکنیم که آیا خطایی رخ داده است یا خیر، و کامپایلر به ما یادآوری میکند که احتمالاً نیاز به مدیریت خطا در این بخش داریم. اکنون این مشکل را اصلاح خواهیم کرد.
مدیریت خطاهای بازگرداندهشده از run در main
ما خطاها را بررسی کرده و با استفاده از تکنیکی مشابه آنچه در Config::build در لیست ۱۲-۱۰ استفاده کردیم مدیریت میکنیم، اما با یک تفاوت کوچک:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:\n{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}ما به جای unwrap_or_else از if let استفاده میکنیم تا بررسی کنیم آیا run یک مقدار Err بازمیگرداند یا خیر و در صورت وقوع، process::exit(1) را فراخوانی کنیم. تابع run مقداری بازنمیگرداند که بخواهیم به همان شیوهای که Config::build نمونه Config را بازمیگرداند آن را unwrap کنیم. از آنجایی که run در صورت موفقیت مقدار () بازمیگرداند، ما فقط به شناسایی یک خطا اهمیت میدهیم، بنابراین نیازی به unwrap_or_else برای بازگرداندن مقدار آن نداریم، که تنها () خواهد بود.
بدنههای if let و unwrap_or_else در هر دو حالت یکسان هستند: ما خطا را چاپ کرده و خارج میشویم.
Splitting Code into a Library Crate
Our minigrep project is looking good so far! Now we’ll split the
src/main.rs file and put some code into the src/lib.rs file. That way, we
can test the code and have a src/main.rs file with fewer responsibilities.
Let’s move all the code that isn’t in the main function from src/main.rs to
src/lib.rs:
- The
runfunction definition - The relevant
usestatements - The definition of
Config - The
Config::buildfunction definition
The contents of src/lib.rs should have the signatures shown in Listing 12-13 (we’ve omitted the bodies of the functions for brevity). Note that this won’t compile until we modify src/main.rs in Listing 12-14.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}Config and run into src/lib.rsWe’ve made liberal use of the pub keyword: on Config, on its fields and its
build method, and on the run function. We now have a library crate that has
a public API we can test!
Now we need to bring the code we moved to src/lib.rs into the scope of the binary crate in src/main.rs, as shown in Listing 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::search;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}minigrep library crate in src/main.rsWe add a use minigrep::Config line to bring the Config type from the
library crate into the binary crate’s scope, and we prefix the run function
with our crate name. Now all the functionality should be connected and should
work. Run the program with cargo run and make sure everything works correctly.
وای! این یک کار سخت بود، اما ما خودمان را برای موفقیت در آینده آماده کردیم. اکنون مدیریت خطاها بسیار آسانتر شده است و کد ما ماژولارتر شده است. از اینجا به بعد تقریباً تمام کارهای ما در فایل src/lib.rs انجام خواهد شد.
بیایید از این ماژولاریت جدید برای انجام کاری استفاده کنیم که با کد قبلی دشوار بود اما با کد جدید آسان است: نوشتن چند تست!
توسعه قابلیتهای کتابخانه با توسعه آزمونمحور (TDD) یا همان (Test-Driven Development)
اکنون که منطق جستوجو را در فایل src/lib.rs و جدا از تابع main داریم، نوشتن تست برای عملکرد اصلی کد بسیار آسانتر شده است.
میتوانیم توابع را مستقیماً با آرگومانهای مختلف فراخوانی کنیم و مقادیر بازگشتی را بررسی کنیم، بدون آنکه نیاز باشد باینری خود را از طریق خط فرمان اجرا کنیم.
در این بخش، منطق جستجو را با استفاده از فرآیند توسعه آزمونمحور (TDD) به برنامه minigrep اضافه خواهیم کرد. مراحل این فرآیند به شرح زیر است:
- نوشتن یک تست که شکست میخورد و اجرای آن برای اطمینان از اینکه به دلیلی که انتظار داشتید شکست میخورد.
- نوشتن یا تغییر کد به اندازهای که تست جدید پاس شود.
- بازسازی کدی که به تازگی اضافه یا تغییر داده شده و اطمینان از اینکه تستها همچنان پاس میشوند.
- تکرار از مرحله ۱!
TDD تنها یکی از روشهای نوشتن نرمافزار است، اما میتواند به طراحی بهتر کد کمک کند. نوشتن تست قبل از نوشتن کدی که تست را پاس میکند، کمک میکند تا پوشش تست بالا در طول فرآیند حفظ شود.
ما با استفاده از TDD پیادهسازی قابلیت جستجوی رشته کوئری در محتوای فایل و تولید لیستی از خطوط مطابق با کوئری را توسعه خواهیم داد. این قابلیت را در تابعی به نام search اضافه خواهیم کرد.
نوشتن یک تست که شکست میخورد
در فایل src/lib.rs، یک ماژول tests با یک تابع تست اضافه میکنیم، همانطور که در [فصل ۱۱][ch11-anatomy] انجام دادیم.
تابع تست، رفتاری را که از تابع search انتظار داریم مشخص میکند: این تابع یک query و متنی برای جستوجو دریافت میکند، و تنها خطوطی از متن را که شامل query هستند بازمیگرداند.
لیست ۱۲-۱۵ این تست را نشان میدهد.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search به منظور پیادهسازی عملکرد مورد انتظاراین تست به دنبال رشته "duct" میگردد. متنی که در آن جستجو میکنیم شامل سه خط است که تنها یکی از آنها شامل "duct" است (توجه داشته باشید که بکاسلش بعد از علامت نقل قول بازکننده به Rust میگوید که کاراکتر newline در ابتدای محتویات این literal رشته قرار ندهد). ما تأیید میکنیم که مقدار بازگردانده شده از تابع search تنها شامل خطی است که انتظار داریم.
هنوز قادر به اجرای این تست و مشاهده شکست آن نیستیم زیرا تست حتی کامپایل نمیشود: تابع search هنوز وجود ندارد! بر اساس اصول TDD، ما تنها به اندازهای کد اضافه میکنیم که تست کامپایل و اجرا شود، با اضافه کردن یک تعریف از تابع search که همیشه یک بردار خالی بازمیگرداند، همانطور که در لیست ۱۲-۱۶ نشان داده شده است. سپس تست باید کامپایل و شکست بخورد زیرا یک بردار خالی با یک بردار شامل خط "safe, fast, productive." مطابقت ندارد.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search تا تست ما کامپایل شودحال بیایید بررسی کنیم که چرا نیاز داریم یک lifetime صریح با نام 'a در امضای تابع search تعریف کنیم و این lifetime را با آرگومان contents و مقدار بازگشتی استفاده کنیم.
به یاد بیاورید که در فصل ۱۰، پارامترهای lifetime مشخص میکردند که lifetime کدام آرگومان با lifetime مقدار بازگشتی مرتبط است.
در اینجا، مشخص میکنیم که بردار بازگشتی باید شامل برشهایی از رشته باشد که به بخشهایی از آرگومان contents رفرنس میدهند (نه آرگومان query).
متوجه میشوید که ما نیاز داریم یک طول عمر صریح 'a در امضای تابع search تعریف کنیم و از آن طول عمر با آرگومان contents و مقدار بازگشتی استفاده کنیم. به یاد داشته باشید که در فصل ۱۰ توضیح دادیم که پارامترهای طول عمر مشخص میکنند کدام طول عمر آرگومان به طول عمر مقدار بازگشتی متصل است. در این مورد، ما مشخص میکنیم که بردار بازگشتی باید شامل برشهای رشتهای باشد که به برشهای آرگومان contents اشاره دارند (نه آرگومان query).
به عبارت دیگر، به Rust میگوییم دادهای که توسط تابع search بازگردانده میشود به اندازه دادهای که به تابع search در آرگومان contents منتقل میشود زنده خواهد بود. این مهم است! دادهای که توسط یک برش مرجع داده میشود باید معتبر باشد تا مرجع نیز معتبر باشد؛ اگر کامپایلر فرض کند که ما در حال ساختن برشهای رشتهای از query هستیم به جای contents، بررسیهای ایمنی را به اشتباه انجام خواهد داد.
اگر طول عمرها را فراموش کنیم و سعی کنیم این تابع را کامپایل کنیم، این خطا را دریافت خواهیم کرد:
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
کامپایلر Rust نمیتواند بهصورت خودکار تشخیص دهد که کدامیک از دو پارامتر باید به مقدار بازگشتی مرتبط باشد، بنابراین باید این موضوع را بهصراحت به آن اعلام کنیم.
توجه داشته باشید که متن راهنمای خطا پیشنهاد میدهد که برای همه پارامترها و نوع بازگشتی، از یک پارامتر lifetime مشترک استفاده شود، که این پیشنهاد نادرست است!
از آنجا که contents پارامتری است که تمام متن ما را در بر دارد و ما قصد داریم بخشهایی از آن متن را که با جستجو مطابقت دارند بازگردانیم، میدانیم که فقط contents باید با مقدار بازگشتی از طریق نگارش lifetime مرتبط شود.
دیگر زبانهای برنامهنویسی نیازی ندارند آرگومانها را به مقادیر بازگشتی در امضا متصل کنید، اما این تمرین با گذشت زمان آسانتر میشود. ممکن است بخواهید این مثال را با مثالهای موجود در بخش “اعتبارسنجی مراجع با طول عمر” از فصل ۱۰ مقایسه کنید.
نوشتن کدی برای پاس کردن تست
در حال حاضر، تست ما به دلیل اینکه همیشه یک بردار خالی بازمیگرداند، شکست میخورد. برای رفع این مشکل و پیادهسازی search، برنامه ما باید این مراحل را دنبال کند:
- تکرار از طریق هر خط از محتوای فایل.
- بررسی اینکه آیا خط شامل رشته کوئری ما هست یا نه.
- اگر خط شامل کوئری بود، آن را به لیست مقادیر بازگشتی اضافه کنیم.
- اگر نبود، کاری انجام ندهیم.
- لیست نتایجی که مطابقت دارند را بازگردانیم.
بیایید هر مرحله را یکییکی اجرا کنیم، با تکرار از طریق خطوط شروع میکنیم.
تکرار از طریق خطوط با متد lines
Rust یک متد مفید برای مدیریت تکرار خط به خط در رشتهها ارائه میدهد که به طور مناسبی lines نامیده شده است و همانطور که در لیست ۱۲-۱۷ نشان داده شده کار میکند. توجه داشته باشید که این کد هنوز کامپایل نخواهد شد.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}contentsمتد lines یک iterator برمیگرداند. ما در فصل ۱۳ عمیقاً در مورد iteratorها صحبت خواهیم کرد، اما به یاد داشته باشید که قبلاً این روش استفاده از یک iterator را در لیست ۳-۵ دیدید، جایی که از یک حلقه for با یک iterator برای اجرای کدی روی هر آیتم در یک مجموعه استفاده کردیم.
جستجو در هر خط برای کوئری
اکنون، بررسی خواهیم کرد که آیا خط فعلی شامل رشته کوئری ما هست یا نه. خوشبختانه، رشتهها یک متد مفید به نام contains دارند که این کار را برای ما انجام میدهد! یک فراخوانی به متد contains را در تابع search اضافه کنید، همانطور که در لیست ۱۲-۱۸ نشان داده شده است. توجه داشته باشید که این کد همچنان کامپایل نخواهد شد.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}query هست یا نهدر حال حاضر، ما در حال ایجاد قابلیتهای بیشتر هستیم. برای اینکه کد کامپایل شود، نیاز داریم مقداری را از بدنه تابع بازگردانیم همانطور که در امضای تابع اشاره کردیم.
ذخیره خطوط مطابق
برای تکمیل این تابع، نیاز داریم روشی برای ذخیره خطوط مطابق که میخواهیم بازگردانیم داشته باشیم. برای این کار، میتوانیم یک بردار mutable قبل از حلقه for ایجاد کنیم و با استفاده از متد push یک خط را در بردار ذخیره کنیم. بعد از حلقه for، بردار را بازمیگردانیم، همانطور که در لیست ۱۲-۱۹ نشان داده شده است.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}اکنون تابع search باید فقط خطوطی را که شامل query هستند بازگرداند، و تست ما باید پاس شود. بیایید تست را اجرا کنیم:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
تست ما پاس شد، بنابراین میدانیم که کار میکند!
در این مرحله، میتوانیم فرصتهایی برای بازسازی پیادهسازی تابع جستجو در نظر بگیریم و در عین حال تستها را پاس نگه داریم تا همان قابلیت را حفظ کنیم. کد در تابع جستجو چندان بد نیست، اما از برخی ویژگیهای مفید iteratorها استفاده نمیکند. ما در فصل ۱۳ به این مثال بازخواهیم گشت، جایی که iteratorها را با جزئیات بررسی میکنیم و به نحوه بهبود آن میپردازیم.
استفاده از تابع search در تابع run
اکنون که تابع search کار میکند و تست شده است، باید تابع search را از تابع run فراخوانی کنیم. ما باید مقدار config.query و contents که run از فایل میخواند را به تابع search بدهیم. سپس run هر خطی که از search برگردانده شده را چاپ خواهد کرد:
Filename: src/lib.rs
use std::error::Error;
use std::fs;
pub struct Config {
pub query: String,
pub file_path: String,
}
impl Config {
pub fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
pub fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}ما هنوز از یک حلقه for برای بازگرداندن هر خط از search و چاپ آن استفاده میکنیم.
اکنون باید کل برنامه بهدرستی کار کند! بیایید آن را امتحان کنیم، ابتدا با واژهای مانند frog که باید دقیقاً یک خط از شعر امیلی دیکینسون را بازگرداند.
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
عالی! حالا بیایید کلمهای را امتحان کنیم که چندین خط را مطابقت دهد، مثل body:
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
و در نهایت، مطمئن شویم که وقتی کلمهای را جستجو میکنیم که در هیچ جای شعر وجود ندارد، مثل monomorphization، هیچ خطی دریافت نخواهیم کرد:
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
عالی! ما نسخه کوچکی از یک ابزار کلاسیک ساختیم و چیزهای زیادی درباره نحوه ساختاردهی برنامهها آموختیم. همچنین کمی درباره ورودی و خروجی فایل، طول عمرها، تست کردن و تجزیه دستورات خط فرمان یاد گرفتیم.
برای تکمیل این پروژه، به طور مختصر نشان خواهیم داد که چگونه با متغیرهای محیطی کار کنیم و چگونه به خطای استاندارد (standard error) چاپ کنیم، که هر دو در هنگام نوشتن برنامههای خط فرمان مفید هستند.
کار با متغیرهای محیطی
ما باینری minigrep را با افزودن یک ویژگی اضافی بهبود میدهیم: گزینهای برای جستجوی حساسنبودن به حروف کوچک و بزرگ که کاربر میتواند از طریق یک متغیر محیطی آن را فعال کند. میتوانستیم این ویژگی را بهصورت گزینهای در خط فرمان پیادهسازی کنیم و از کاربران بخواهیم که هر بار آن را وارد کنند، اما با استفاده از یک متغیر محیطی، به کاربران اجازه میدهیم که فقط یکبار این متغیر را تنظیم کنند و در کل آن نشست ترمینال، تمام جستجوهای آنها بهصورت حساسنبودن به حروف انجام شود.
نوشتن یک تست شکستخورده برای تابع search_case_insensitive
ابتدا تابع جدیدی به نام search_case_insensitive به کتابخانه minigrep اضافه میکنیم که زمانی فراخوانی میشود که متغیر محیطی مقدار داشته باشد. ما همچنان از فرایند توسعه آزمونمحور (TDD) پیروی میکنیم، بنابراین گام اول، نوشتن یک تست شکستخورده است. یک تست جدید برای تابع search_case_insensitive اضافه میکنیم و نام تست قبلیمان را از one_result به case_sensitive تغییر میدهیم تا تفاوت بین این دو تست واضحتر شود، همانطور که در لیست 12-20 نشان داده شده است.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}توجه کنید که ما متن تست قدیمی را نیز ویرایش کردهایم. ما یک خط جدید با متن "Duct tape." با
حرف بزرگ D اضافه کردهایم که نباید با عبارت جستجو "duct" در حالت حساس به حروف کوچک و
بزرگ مطابقت داشته باشد. تغییر دادن تست قدیمی به این صورت کمک میکند که مطمئن شویم عملکرد
جستجوی حساس به حروف کوچک و بزرگ که قبلاً پیادهسازی کردهایم به طور تصادفی شکسته نمیشود.
این تست باید اکنون عبور کند و همچنان باید عبور کند در حالی که ما روی جستجوی غیرحساس به حروف
کار میکنیم.
تست جدید برای جستجوی غیرحساس به حروف کوچک و بزرگ از "rUsT" به عنوان عبارت جستجو استفاده
میکند. در تابع search_case_insensitive که قصد داریم اضافه کنیم، عبارت جستجوی "rUsT"
باید با خط حاوی "Rust:" با حرف بزرگ R و خط "Trust me." مطابقت داشته باشد، حتی اگر هر
دو حالت متفاوتی نسبت به عبارت جستجو داشته باشند. این تست شکستخورده ما است و به دلیل اینکه
هنوز تابع search_case_insensitive تعریف نشده است، کامپایل نخواهد شد. میتوانید یک
پیادهسازی موقتی که همیشه یک وکتور خالی برمیگرداند اضافه کنید، مشابه کاری که برای تابع
search در لیستینگ 12-16 انجام دادیم تا تست کامپایل شده و شکست بخورد.
پیادهسازی تابع search_case_insensitive
تابع search_case_insensitive که در لیستینگ 12-21 نشان داده شده است، تقریباً مشابه تابع
search خواهد بود. تنها تفاوت این است که ما عبارت جستجو و هر خط را کوچکحرف میکنیم تا
صرفنظر از مورد ورودیها، هنگام بررسی اینکه آیا خط شامل عبارت جستجو است، هر دو به یک مورد
تبدیل شوند.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\
Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}search_case_insensitive برای کوچکحرف کردن عبارت جستجو و خط قبل از مقایسه آنهاابتدا رشته query را به حروف کوچک تبدیل میکنیم و آن را در متغیر جدیدی با همان نام ذخیره میکنیم و مقدار اصلی query را شَدو (shadow) میکنیم. فراخوانی to_lowercase بر روی query ضروری است تا صرفنظر از اینکه کاربر عبارت مورد جستجوی خود را به صورت "rust"، "RUST"، "Rust" یا "rUsT" وارد کند، ما با آن گویی که "rust" وارد شده است برخورد کنیم و نسبت به حروف کوچک و بزرگ حساس نباشیم. هرچند to_lowercase نگاشت پایهی Unicode را انجام میدهد، اما صد درصد دقیق نخواهد بود. اگر قصد نوشتن یک برنامه واقعی را داشتیم، نیاز به کار بیشتری در این بخش بود، اما از آنجا که این بخش در مورد متغیرهای محیطی است، نه Unicode، در همین حد باقی میمانیم.
توجه کنید که اکنون query یک رشته (String) به جای برش رشته (string slice) است، زیرا
فراخوانی to_lowercase دادههای جدید ایجاد میکند به جای اینکه به دادههای موجود اشاره کند.
به عنوان مثال، بگویید عبارت جستجو "rUsT" است: آن رشته شامل یک u یا t کوچک نیست که بتوانیم
استفاده کنیم، بنابراین باید یک String جدید شامل "rust" تخصیص دهیم. وقتی اکنون query را
به عنوان یک آرگومان به متد contains منتقل میکنیم، نیاز داریم که یک علامت & اضافه کنیم
چون امضای contains به گونهای تعریف شده است که یک برش رشته دریافت میکند.
بعداً یک فراخوانی به to_lowercase بر روی هر line اضافه میکنیم تا همه کاراکترها کوچکحرف
شوند. اکنون که line و query را به کوچکحرف تبدیل کردهایم، مطمئن میشویم که مطابقتها
صرفنظر از مورد عبارت جستجو پیدا شوند.
بیایید ببینیم آیا این پیادهسازی تستها را پاس میکند یا خیر:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
عالی! تستها پاس شدند. حالا بیایید تابع جدید search_case_insensitive را از تابع run
فراخوانی کنیم. ابتدا یک گزینه پیکربندی به ساختار Config اضافه میکنیم تا بین جستجوی حساس
به حروف کوچک و بزرگ و غیرحساس به حروف کوچک و بزرگ سوئیچ کنیم. افزودن این فیلد باعث ایجاد
خطاهای کامپایل میشود زیرا هنوز این فیلد را در هیچ جا مقداردهی نکردهایم:
Filename: src/main.rs
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}We added the ignore_case field that holds a Boolean. Next, we need the run
function to check the ignore_case field’s value and use that to decide
whether to call the search function or the search_case_insensitive
function, as shown in Listing 12-22. This still won’t compile yet.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}search or search_case_insensitive based on the value in config.ignore_caseدر نهایت، باید بررسی کنیم که آیا متغیر محیطی تنظیم شده است یا خیر. توابع مربوط به کار با متغیرهای محیطی در ماژول env از کتابخانه استاندارد قرار دارند که در بالای فایل src/main.rs از قبل در scope قرار دارد. برای بررسی اینکه آیا متغیر محیطیای به نام IGNORE_CASE مقداری دارد یا نه، از تابع var در ماژول env استفاده میکنیم، همانطور که در لیست 12-23 نشان داده شده است.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}IGNORE_CASEاینجا یک متغیر جدید به نام ignore_case ایجاد میکنیم. برای مقداردهی آن، تابع env::var را
فراخوانی کرده و نام متغیر محیطی IGNORE_CASE را به آن میدهیم. تابع env::var یک Result
برمیگرداند که در صورت تنظیم بودن متغیر محیطی به هر مقداری، مقدار Ok با مقدار متغیر محیطی را
دارد. اگر متغیر محیطی تنظیم نشده باشد، مقدار Err برگردانده میشود.
ما از متد is_ok روی Result استفاده میکنیم تا بررسی کنیم که آیا متغیر محیطی تنظیم شده است،
که نشان میدهد برنامه باید جستجو را به صورت غیرحساس به حروف کوچک و بزرگ انجام دهد. اگر متغیر
محیطی IGNORE_CASE به هیچ مقداری تنظیم نشده باشد، is_ok مقدار false برمیگرداند و برنامه
جستجو را به صورت حساس به حروف کوچک و بزرگ انجام میدهد. ما به مقدار متغیر محیطی نیازی نداریم، فقط
میخواهیم بررسی کنیم که آیا تنظیم شده است یا نه. بنابراین از is_ok به جای متدهایی مانند
unwrap، expect یا دیگر متدهای مرتبط با Result استفاده میکنیم.
ما مقدار متغیر ignore_case را به نمونه Config منتقل میکنیم تا تابع run بتواند این مقدار
را بخواند و تصمیم بگیرد که آیا باید تابع search_case_insensitive یا search را فراخوانی کند.
امتحان کردن برنامه
حالا بیایید برنامه را امتحان کنیم! ابتدا برنامه را بدون تنظیم متغیر محیطی و با عبارت جستجوی
to اجرا میکنیم. این عبارت باید با هر خطی که شامل کلمه to به صورت تمام حروف کوچک باشد،
مطابقت داشته باشد:
$ cargo run -- to poem.txt
برنامه همچنان باید به درستی کار کند و تنها خطوطی که کاملاً با عبارت مطابقت دارند را برگرداند.
حالا برنامه را با متغیر محیطی IGNORE_CASE که به مقدار 1 تنظیم شده است اجرا میکنیم و
همان عبارت جستجو to را امتحان میکنیم:
$ IGNORE_CASE=1 cargo run -- to poem.txt
در صورت استفاده از PowerShell، نیاز است که متغیر محیطی را تنظیم کنید و سپس برنامه را به صورت دستورات جداگانه اجرا کنید:
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
این دستور باعث میشود که IGNORE_CASE برای مدت زمان نشست ترمینال شما تنظیم باقی بماند. میتوانید
آن را با دستور Remove-Item حذف کنید:
PS> Remove-Item Env:IGNORE_CASE
برنامه باید خطوطی که شامل to هستند و ممکن است حروف بزرگ داشته باشند را برگرداند:
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
عالی! حالا برنامه minigrep ما میتواند جستجوهای غیرحساس به حروف کوچک و بزرگ را انجام دهد که
با یک متغیر محیطی کنترل میشود. حالا شما میدانید چگونه گزینههایی را که از طریق آرگومانهای
خط فرمان یا متغیرهای محیطی تنظیم میشوند مدیریت کنید.
برخی برنامهها اجازه میدهند که آرگومانها و متغیرهای محیطی برای یک پیکربندی واحد استفاده شوند. در این موارد، برنامهها تصمیم میگیرند که یکی از آنها اولویت داشته باشد. برای تمرین بیشتر، سعی کنید حساسیت به حروف کوچک و بزرگ را از طریق یک آرگومان خط فرمان یا یک متغیر محیطی کنترل کنید. تصمیم بگیرید که در صورت تنظیم یکی به حساس و دیگری به غیرحساس بودن، آرگومان خط فرمان یا متغیر محیطی باید اولویت داشته باشد.
ماژول std::env ویژگیهای مفید بسیاری برای کار با متغیرهای محیطی دارد: مستندات آن را بررسی کنید
تا ببینید چه امکاناتی در دسترس است.
نوشتن پیامهای خطا به خروجی خطای استاندارد به جای خروجی استاندارد
در حال حاضر، ما تمام خروجیهای خود را با استفاده از ماکروی println! به ترمینال مینویسیم. در بیشتر ترمینالها، دو نوع خروجی وجود دارد: خروجی استاندارد (stdout) برای اطلاعات عمومی و خروجی خطای استاندارد (stderr) برای پیامهای خطا. این تمایز به کاربران امکان میدهد که خروجی موفقیتآمیز یک برنامه را به یک فایل هدایت کنند اما همچنان پیامهای خطا را روی صفحه ببینند.
ماکروی println! فقط قادر به نوشتن در خروجی استاندارد است، بنابراین برای نوشتن به خروجی خطای استاندارد باید از چیزی دیگر استفاده کنیم.
بررسی محل نوشتن خطاها
ابتدا بررسی میکنیم که محتوای چاپشده توسط minigrep در حال حاضر به خروجی استاندارد نوشته میشود، از جمله پیامهای خطایی که میخواهیم به جای آنها در خروجی خطای استاندارد نوشته شوند. این کار را با هدایت جریان خروجی استاندارد به یک فایل و عمداً ایجاد یک خطا انجام خواهیم داد. ما جریان خروجی خطای استاندارد را هدایت نمیکنیم، بنابراین هر محتوایی که به خروجی خطای استاندارد ارسال شود همچنان روی صفحه نمایش داده خواهد شد.
برنامههای خط فرمان انتظار میرود که پیامهای خطای خود را به جریان خروجی خطای استاندارد ارسال کنند تا در صورت هدایت جریان خروجی استاندارد به یک فایل، پیامهای خطا همچنان روی صفحه نمایش داده شوند. برنامه ما در حال حاضر به درستی عمل نمیکند: ما به زودی خواهیم دید که پیام خطا به جای صفحه نمایش به فایل ذخیره میشود!
برای نشان دادن این رفتار، برنامه را با استفاده از دستور > و مسیر فایل output.txt که میخواهیم جریان خروجی استاندارد را به آن هدایت کنیم، اجرا میکنیم. هیچ آرگومانی ارائه نخواهیم کرد، که باید منجر به یک خطا شود:
$ cargo run > output.txt
دستور > به شل میگوید که محتوای جریان خروجی استاندارد را به output.txt بنویسد به جای اینکه آن را روی صفحه نمایش دهد. ما پیام خطایی که انتظار داشتیم روی صفحه ببینیم را ندیدیم، بنابراین به این معنی است که باید در فایل ذخیره شده باشد. این همان چیزی است که output.txt شامل میشود:
Problem parsing arguments: not enough arguments
بله، پیام خطای ما به خروجی استاندارد چاپ میشود. برای پیامهای خطایی مانند این بهتر است که به خروجی خطای استاندارد چاپ شوند تا فقط دادههای حاصل از اجرای موفقیتآمیز در فایل قرار گیرند. ما این موضوع را تغییر خواهیم داد.
نوشتن خطاها به خروجی خطای استاندارد
ما از کدی که در لیستینگ 12-24 نشان داده شده است برای تغییر نحوه چاپ پیامهای خطا استفاده میکنیم. به دلیل بازسازیای که قبلاً در این فصل انجام دادیم، تمام کدی که پیامهای خطا را چاپ میکند در یک تابع به نام main قرار دارد. کتابخانه استاندارد ماکروی eprintln! را ارائه میدهد که به جریان خروجی خطای استاندارد چاپ میکند، بنابراین دو جایی که ما println! را برای چاپ خطاها فراخوانی کردهایم را به eprintln! تغییر میدهیم.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}eprintln!حالا برنامه را دوباره اجرا میکنیم به همان روش، بدون هیچ آرگومانی و با هدایت خروجی استاندارد با استفاده از >:
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
حالا خطا را روی صفحه میبینیم و output.txt خالی است، که همان رفتاری است که از برنامههای خط فرمان انتظار داریم.
برنامه را دوباره اجرا میکنیم با آرگومانهایی که خطایی ایجاد نمیکنند اما همچنان خروجی استاندارد را به یک فایل هدایت میکنند، مانند این:
$ cargo run -- to poem.txt > output.txt
هیچ خروجی روی ترمینال نخواهیم دید و output.txt شامل نتایج ما خواهد بود:
Filename: output.txt
Are you nobody, too?
How dreary to be somebody!
این نشان میدهد که اکنون از خروجی استاندارد برای خروجیهای موفقیتآمیز و از خروجی خطای استاندارد برای خروجیهای خطا استفاده میکنیم، همانطور که مناسب است.
خلاصه
این فصل به طور خلاصه برخی از مفاهیم اصلی که تاکنون آموختهاید را مرور کرد و توضیح داد که چگونه عملیات ورودی/خروجی معمول را در Rust انجام دهید. با استفاده از آرگومانهای خط فرمان، فایلها، متغیرهای محیطی و ماکروی eprintln! برای چاپ خطاها، شما اکنون آمادهاید تا برنامههای خط فرمان بنویسید. همراه با مفاهیم فصلهای قبلی، کد شما سازماندهی خوبی خواهد داشت، دادهها را به طور مؤثر در ساختارهای داده مناسب ذخیره میکند، خطاها را به خوبی مدیریت میکند و به خوبی تست شده است.
ویژگیهای زبانهای تابعی: تکرارگرها و closureها
طراحی زبان Rust از بسیاری از زبانها و تکنیکهای موجود الهام گرفته است و یکی از تأثیرات مهم آن برنامهنویسی تابعی است. برنامهنویسی به سبک تابعی اغلب شامل استفاده از توابع به عنوان مقادیر است، از طریق ارسال آنها به عنوان آرگومان، بازگرداندن آنها از دیگر توابع، اختصاص آنها به متغیرها برای اجرای بعدی و موارد دیگر.
در این فصل، ما بحث نخواهیم کرد که برنامهنویسی تابعی چیست یا چه نیست، بلکه به جای آن درباره برخی از ویژگیهای Rust که مشابه ویژگیهای بسیاری از زبانهایی است که اغلب به آنها تابعی گفته میشود، صحبت خواهیم کرد.
به طور خاص، ما پوشش خواهیم داد:
- _Closure_ها، ساختاری شبیه به تابع که میتوان آن را در یک متغیر ذخیره کرد
- _پیمایشگر_ها (Iterator)، روشی برای پردازش مجموعهای از عناصر
- نحوه استفاده از closureها و iteratorها برای بهبود پروژهٔ ورودی/خروجی در فصل ۱۲
- عملکرد closureها و iteratorها (هشدار: آنها سریعتر از چیزی هستند که ممکن است فکر کنید!)
ما قبلاً برخی از ویژگیهای دیگر Rust، مانند الگوها و enums را پوشش دادهایم که همچنین از سبک تابعی تأثیر گرفتهاند. از آنجایی که تسلط بر closureها و تکرارگرها بخش مهمی از نوشتن کد ایدوماکتیک و سریع در Rust است، ما کل این فصل را به آنها اختصاص خواهیم داد.